Aligning Information Capacity Between Vision and Language via Dense-to-Sparse Feature Distillation for Image-Text Matching
Aligning Information Capacity Between Vision and Language via Dense-to-Sparse Feature Distillation for Image-Text Matching
Written by. Yang Liu, Wentao Feng, Zhuoyao Liu
개요
- 이 논문은 이미지-텍스트 매칭(Image-Text Matching, ITM) 성능을 향상시키기 위해 텍스트 임베딩의 정보량(Information Capacity)에 주목
- 기존 방법들이 짧고 간결한 텍스트에만 의존하여 시멘틱 정렬을 시도하는 한계를 극복하기 위해, 본 논문은 D2S-VSE(Dense-to-Sparse Visual Semantic Embedding)라는 새로운 프레임워크를 제안
핵심 문제
- 기존 ITM 모델들은 sparse(짧고 간결한) 텍스트만으로 이미지와 정렬하여 정보 용량이 제한된 임베딩을 학습함 → 다중 시각(multi-view) 설명 대응이 어려움
- Dense한 설명은 더 많은 정보를 담고 있으나, 실제 테스트에서는 사용되지 않음
- 그래서, 학습은 dense로 하고 추론은 sparse로 하는 두 단계 구조가 필요
주요 기여 (Contributions)
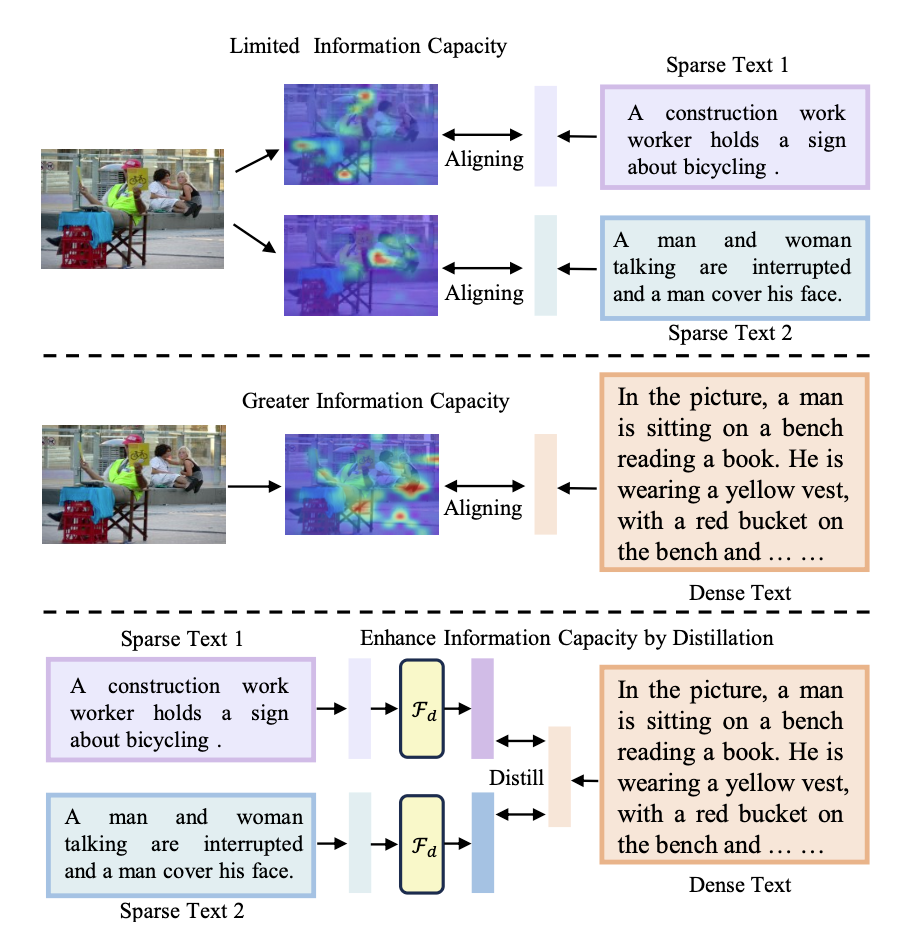
- Information Capacity의 중요성을 강조하며 임베딩 모델 성능 향상을 위한 핵심으로 설정
- D2S-VSE 프레임워크 제안
- Stage 1: Dense text와 이미지의 정렬을 통해 정보량이 풍부한 이미지 임베딩 학습
- Stage 2: Dense → Sparse distillation으로 sparse 텍스트 임베딩의 정보량을 보완
방법론: D2S-VSE 구조
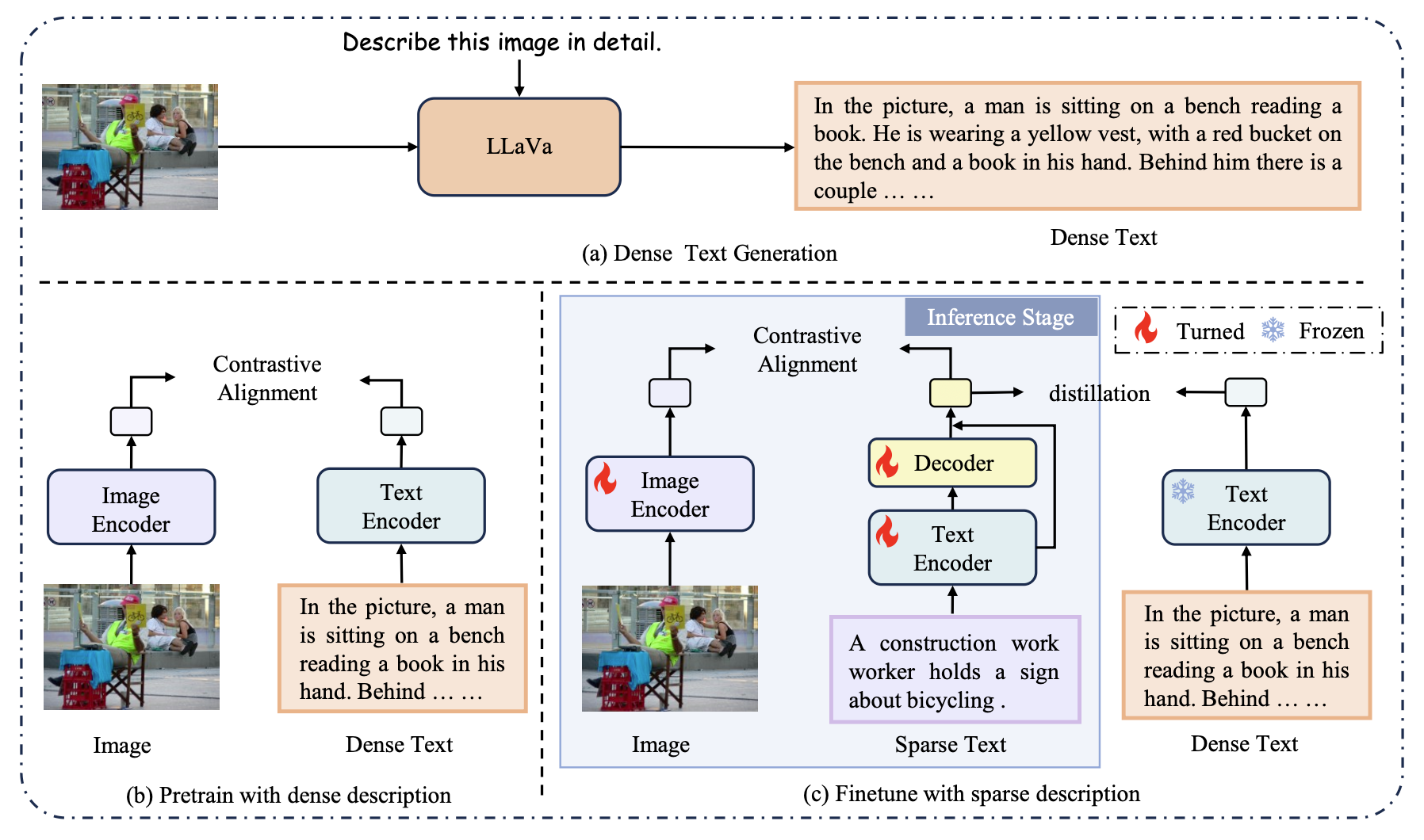
1. Pre-training with Dense Text (Stage 1)
- 목적: 이미지와 dense text를 정렬 → 정보량 높은 시멘틱 임베딩 생성
- 과정
LLaVa 같은 비전-언어 대형 모델을 활용해 각 이미지에 대해 Dense Text 생성
“Describe this image in detail.” 프롬프트 사용
- Contrastive Learning을 통해 image-dense text 쌍 정렬
- 더 많은 시맨틱 정보를 갖는 임베딩 학습
2. Fine-tuning with Sparse Text + Dense-to-Sparse Distillation (Stage 2)
- 목적: 테스트에선 dense text가 제공되지 않음 → 모델이 sparse text에 적응해야 함
- 기존 VSE는 sparse text로만 학습하므로 정보 손실 발생
- sparse text를 masked dense text로 보고, dense text에서 정보를 distill하여 sparse text의 표현력을 높임
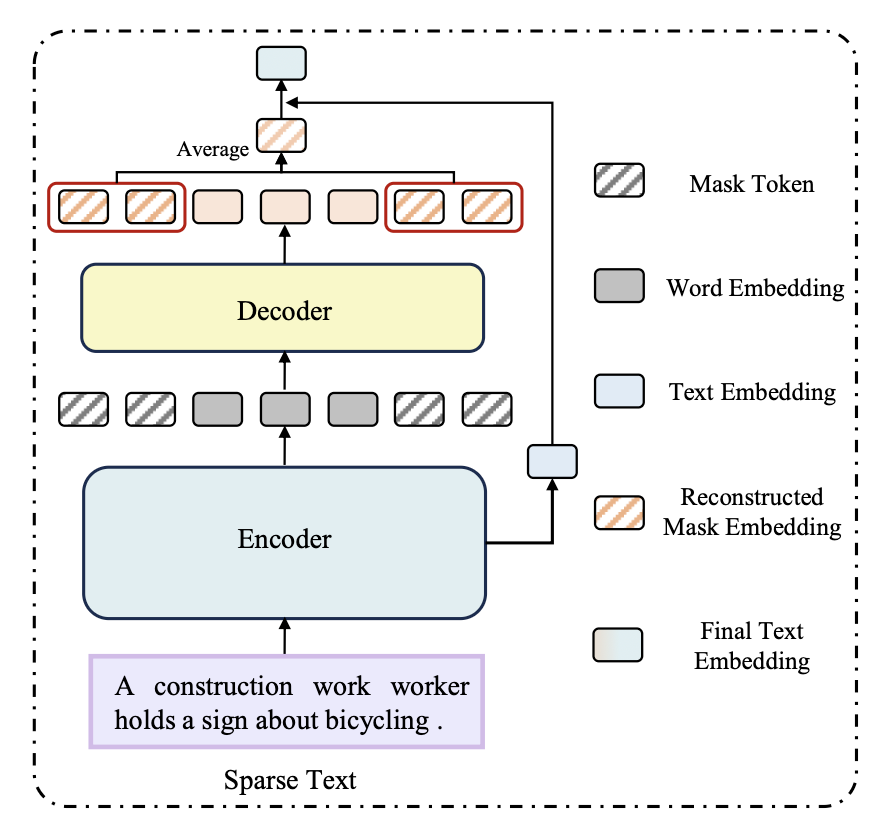
- 과정
- Sparse text → Encoder → 임베딩 생성
- Learnable Mask Tokens(100개)와 함께 Decoder 입력 → dense text의 의미를 재구성
- Decoder 출력 임베딩과 원래 sparse 임베딩을 합쳐서 정보가 보강된 최종 텍스트 임베딩 생성
- 추론 시 임베딩 추출
- 입력
- 이미지
- Sparse 텍스트 - 실제 사용자 텍스트 - 구성 요소:
- 이미지 인코더:
- 이미지 → 임베딩 벡터
- 학습 시 dense text와 정렬되도록 훈련됨 → 정보량 풍부
- 텍스트 인코더 + 디코더 (Sparse Branch):
- Sparse 텍스트 Ts → 텍스트 인코더 → $\mathbf{t}^s$
- Mask tokens과 함께 디코더 → 추가 정보 복원 → $\hat{\mathbf{t}^s}$
- 최종 텍스트 임베딩 = $\mathbf{t}^s + \hat{\mathbf{t}^s}$
3. Loss Function
- Distillation Loss: dense와 sparse 임베딩 간 cosine 유사도 최소화
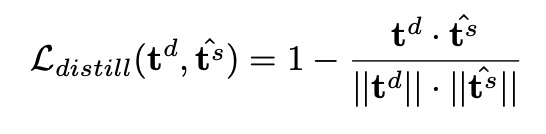
- Alignment Loss: 이미지와 sparse 텍스트 정렬 유지
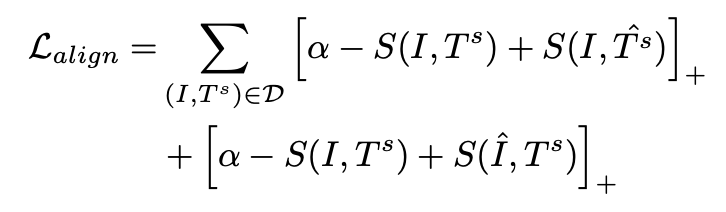
- 최종 Loss: $L = L_{align} + L_{distill}$
Experiments
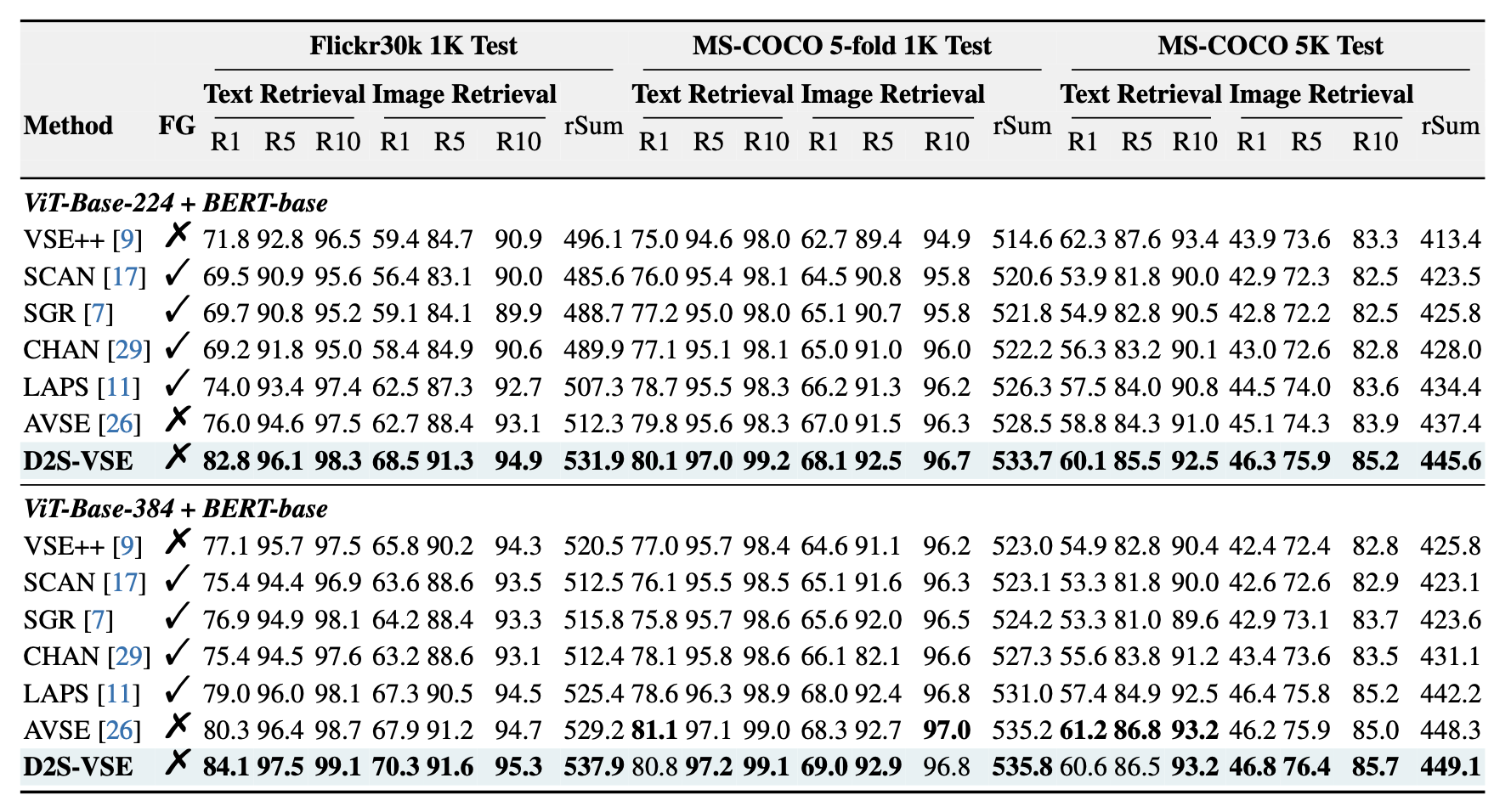
- MS-COCO, Flickr30K 데이터셋 기준, D2S-VSE가 모든 기준에서 최고 성능 기록
- Flickr30K (ViT-base-224):
- Text Retrieval R@1: 82.8%
- Image Retrieval R@1: 68.5%
- 기존 최고 모델 AVSE 대비 6.8%/5.8% 향상
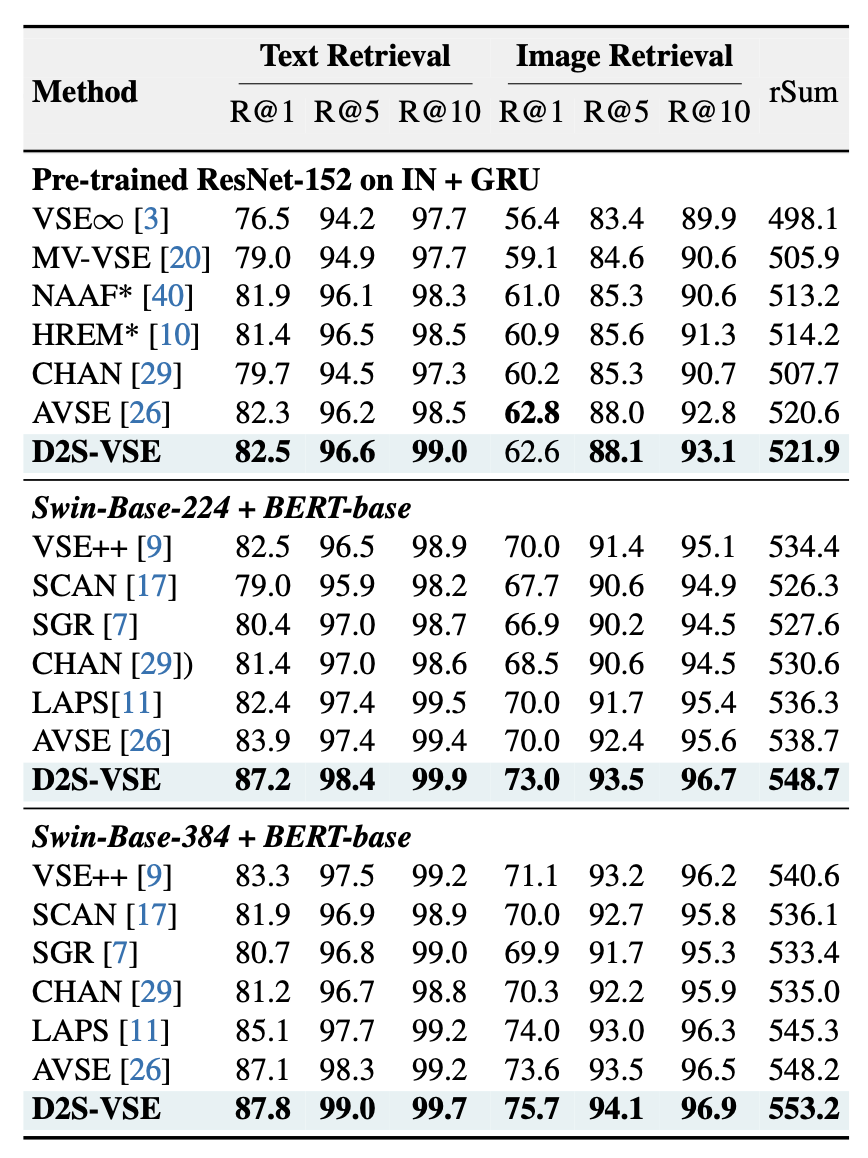
- 다양한 백본에서도 좋은 성능
Ablation Study
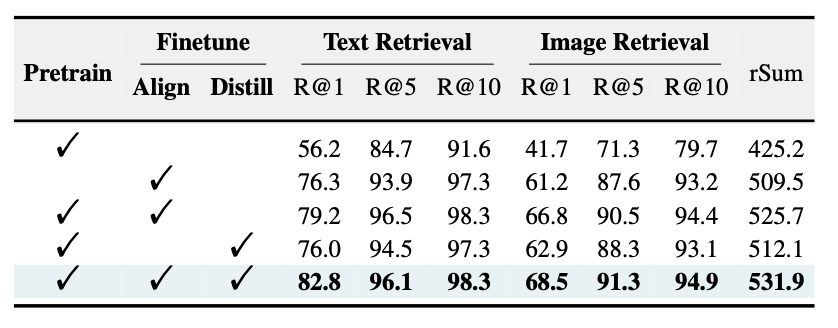
- Pre-training만 한 경우: 성능 낮음 → fine-tuning 필수
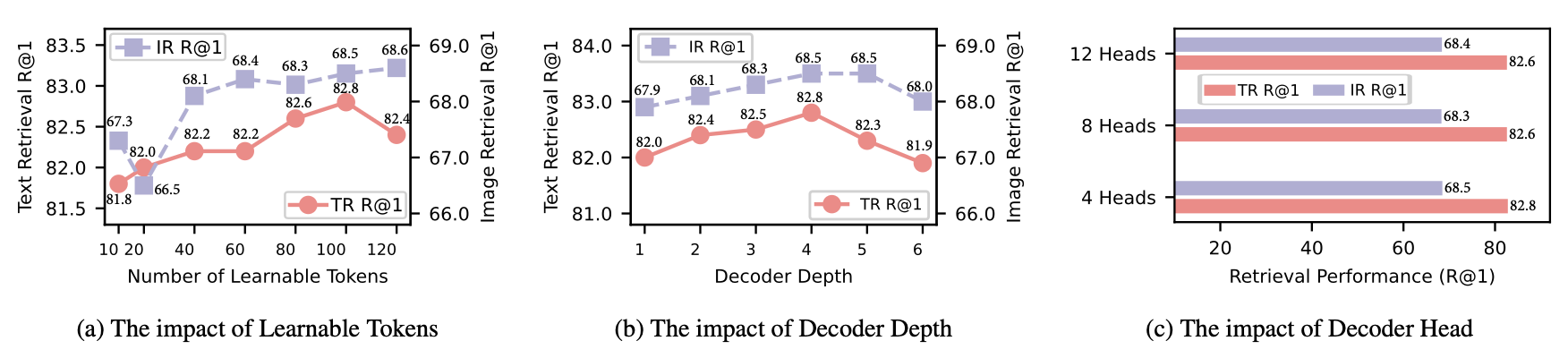
- Distillation이 추가된 경우, Text R@1 82.8%로 상승
- Decoder 깊이: 4 layers일 때 최적

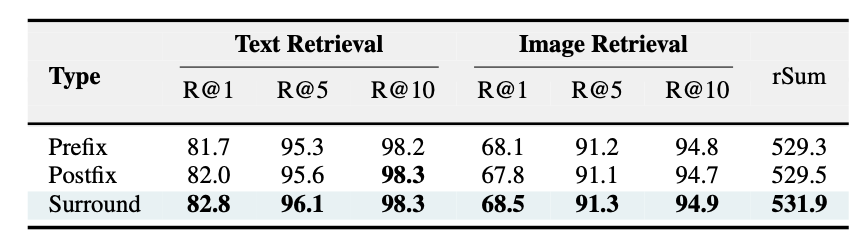
- Learnable Token 위치: Surround 방식이 Prefix/Postfix보다 우수
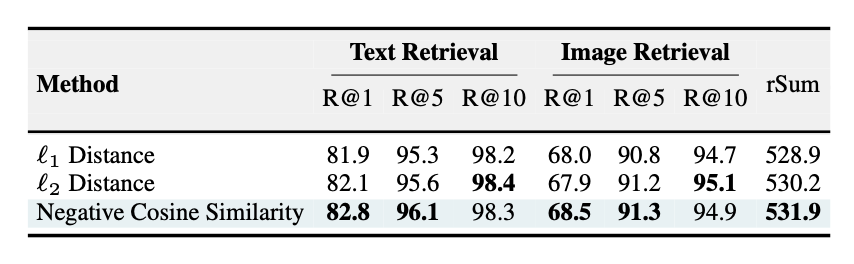
- distill loss 계산 시 유사도 메트릭 중 코사인 유사도가 제일 좋은 성능
결론
- 기존 ITM 방식의 한계를 정보 용량 관점에서 정의하고,
- D2S-VSE라는 Dense-to-Sparse distillation 기반의 VSE 프레임워크로 극복
- 다양한 실험 결과를 통해 현존 최고 수준의 성능을 달성
This post is licensed under CC BY 4.0 by the author.