Boosting Data Utilization for Multilingual Dense Retrieval
Boosting Data Utilization for Multilingual Dense Retrieval
Written By. Chao Huang, Fengran Mo, Yufeng Chen, Changhao Guan
1. 연구 목적 및 배경
- 기존 연구는 주로 모델 아키텍처 개선에 집중했지만, 이 논문은 데이터 활용도를 높이는 방식에 초점을 맞춤.
- 핵심 문제는 false negatives와 비효율적인 mini-batch 구성
- 이를 해결하기 위한 세가지 Stage를 제안.
2. 제안하는 방법 개요
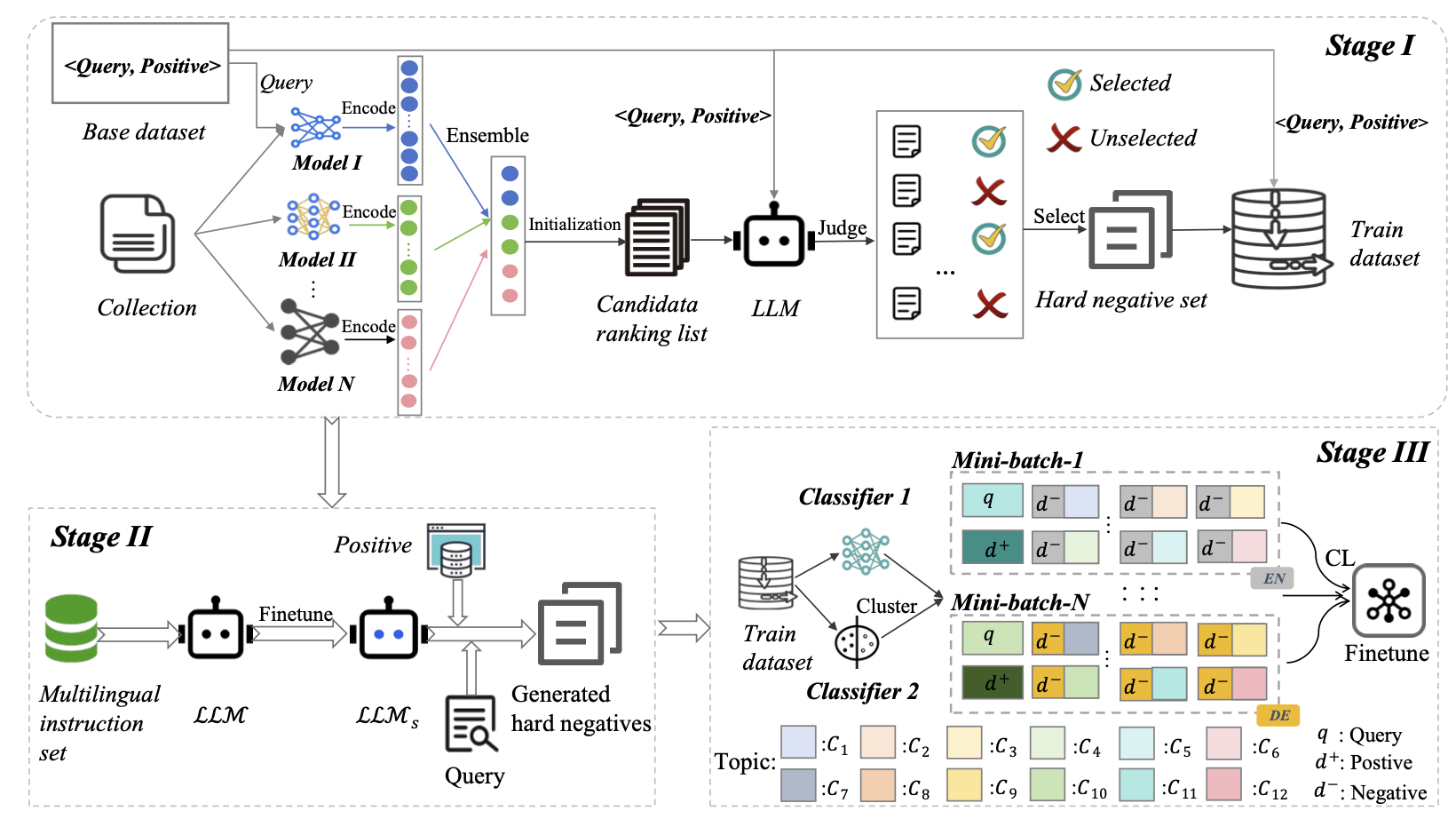
Stage 1: Hard Negative Set Construction (하드 네거티브 후보 생성 및 필터링)

- 목적:
- 질 낮은 또는 실제로는 관련 있는 문서(false negative)가 부정 샘플로 사용되는 문제 해결
- 다양한 언어에 대해 신뢰성 있는 하드 네거티브 샘플을 확보
- 방법:
- 다국어 retriever 앙상블 구성
- 여러 다국어 임베딩 모델 (mE5, BGE 등)로 질의와 문서를 각각 임베딩
- 각 모델의 출력(feature)을 컨캣하여 후보 문서 목록 생성
- 왜 유사도를 더하는 방식이 아니라 컨캣(concat)해서 dot product 하는가?
- 단순히 각 모델의 유사도 점수를 더하는 방식은 모델 간 스케일 차이 문제를 해결하기 어려움. → 정규화하는 과정이 영향을 줌.
- 어떤 retriever는 cosine 값이 좁은 범위에 분포, 다른 retriever는 넓게 분포 → 단순 합산하면 특정 모델에 편향됨
- 단순히 각 모델의 유사도 점수를 더하는 방식은 모델 간 스케일 차이 문제를 해결하기 어려움. → 정규화하는 과정이 영향을 줌.
- LLM 기반 평가
- 후보 문서에 대해 LLaMA 3.1-70B-Instruct으로 “정확도”와 “완전성”을 평가
- 각 후보 문서를 아래와 같은 기준으로 평가:
- Accuracy: 사실 오류 여부
- Completeness: 쿼리에 대한 정보 포함 여부
- 이 두 항목을 점수로 매기고, 정확도 0점 & 완전성 0점이면 “진짜 hard negative”로 간주. ⇒ false negative 제거됨
- 점수 기준:
- 0: 관련 없음
- 1: 부분 관련
- 2: 매우 관련
- 점수 기준:
- 다국어 retriever 앙상블 구성
중요: 이 단계를 통해 실제로는 관련 있는 문서를 모델 학습에 방해가 되는 부정 샘플로 잘못 사용하는 것을 방지함
Stage 2: LLM-aided Hard Negative Generation
- 목적:
- Stage 1 이후 샘플 수가 부족한 질의에 대해 추가적인 하드 네거티브 샘플 생성
- 특히 저자원 언어나 후보 문서가 적은 케이스에서 유용
- 방법:
- LLM Instruction Fine-tuning
- 다국어 instruction을 활용해 LLM을 파인튜닝 (Alpaca 데이터 기반)
- 구글 번역으로 번역한 다국어 instruction을 포함
- 논문에서는 Alpaca 데이터셋 기반의 영문 instruction들을 Google Translate를 이용해 16개 언어로 자동 번역하여 multilingual instruction set을 구성.
- 즉, 같은 task (예: “이 문서를 요약하세요”)에 대해 다국어로 instruction을 제공해서 모델이 다양한 언어 상황에 적응할 수 있게 만듬.
- Positive-Driven Back-Forward Generation
- positive 문서를 LLM이 요약
- 해당 요약을 기반으로 새로운 query 생성
- 이 새로운 query로 retriever 앙상블을 사용하여 다시 top-k 문서 후보 수집
- 다시 Stage 1의 LLM 판별 단계를 활용해 positive가 아닌 문서만 기존 hard negative 후보 pool에 추가하여 수량을 30개로 맞춤
- 기존에 10개 남았다면, LLM을 통해 20개 추가 생성
- 15개라면, 15개 추가 생성
- 반복해서 보충해서 최종적으로 query당 30개 hard negatives가 되도록 맞춤. - 결과적으로 hard negative 후보 수가 각 query마다 균등하게 유지됨
- LLM Instruction Fine-tuning
Stage 3: Effective Mini-Batch Construction (효율적인 미니배치 구성)
- 목적:
- Contrastive Learning을 통해 모델을 fine-tune할 때, 학습 배치의 구성도 성능에 중요한 영향을 미침
- 방법:
- Mini-batch 내 언어 일치 (monolingual 구성)
- 서로 다른 언어의 쌍은 너무 쉽게 구분되기 때문에, 같은 언어 내에서 fine-tuning
- 토픽 다양성 확보
- fastText 기반 분류기로 문서의 주제를 분류 (DBpedia + Yahoo 기반)
- 배치 내에 다양한 주제를 포함시켜 Semantic 다양성 확보
- 토픽 추출 방식
- 사용된 모델: fastText 분류기
- 데이터셋:
- DBpedia Ontology (fine-grained entity categories, 14개 클래스)
- Yahoo Answers (coarse-grained, 10개 일반 카테고리)
- 절차:
- 각 문서에 대해 두 데이터셋 라벨로 각각 토픽 라벨을 부여
- 이 결과를 결합해 새로운 12개 카테고리(C1–C12)를 새로 정의(수동)
- mini-batch를 만들 때 각 query–doc pair에 토픽 라벨이 붙음
- 배치 샘플링 시 monolingual + multi-topic 구조로 맞춤
가중치 기반 Negative 샘플 선택
\[\omega(d^-) = \alpha_l(d^-) + \beta_c(d^-)\]- $\alpha_l$: 언어 기반 가중치
- 자주 등장하는 언어보다 저자원 언어에 높은 가중치를 부여
- 전체 언어 데이터셋 비율을 활용
- $\beta_c$: 토픽 기반 가중치
- 흔하지 않은 주제일수록 더 높은 비중을 줌
- 각 배치 내 토픽의 데이터셋 비율을 활용 → 배치마다 값 달라짐
- 목적
- 모델이 소외된 언어나 주제를 무시하지 않도록 유도
- 기존 $\mathcal{L}_{\text{CL}}$ : infoNCE Loss
- contrastive learning에서 loss 계산 시 이 가중치를 반영:
- $\alpha_l$: 언어 기반 가중치
- 이 전략은 저자원 언어와 적은 데이터셋 주제를 모델이 더 잘 학습할 수 있도록 설계됨
- Mini-batch 내 언어 일치 (monolingual 구성)
전체 프로세스 요약:
- Stage 1: 기존 후보 문서 중 false negative 제거
- Stage 2: 부족한 negative를 LLM이 생성
- Stage 3: 최종 배치를 언어 통일 + 주제 다양성 + 가중치 기반으로 구성
- 결과적으로, 이 방법은 Dense Retriever 모델이 정확하고 일반화 가능한 표현 학습을 하도록 도와줍니다.
3. 실험 결과
벤치마크: MIRACL (다국어 문서 검색 데이터셋, 16개 언어)
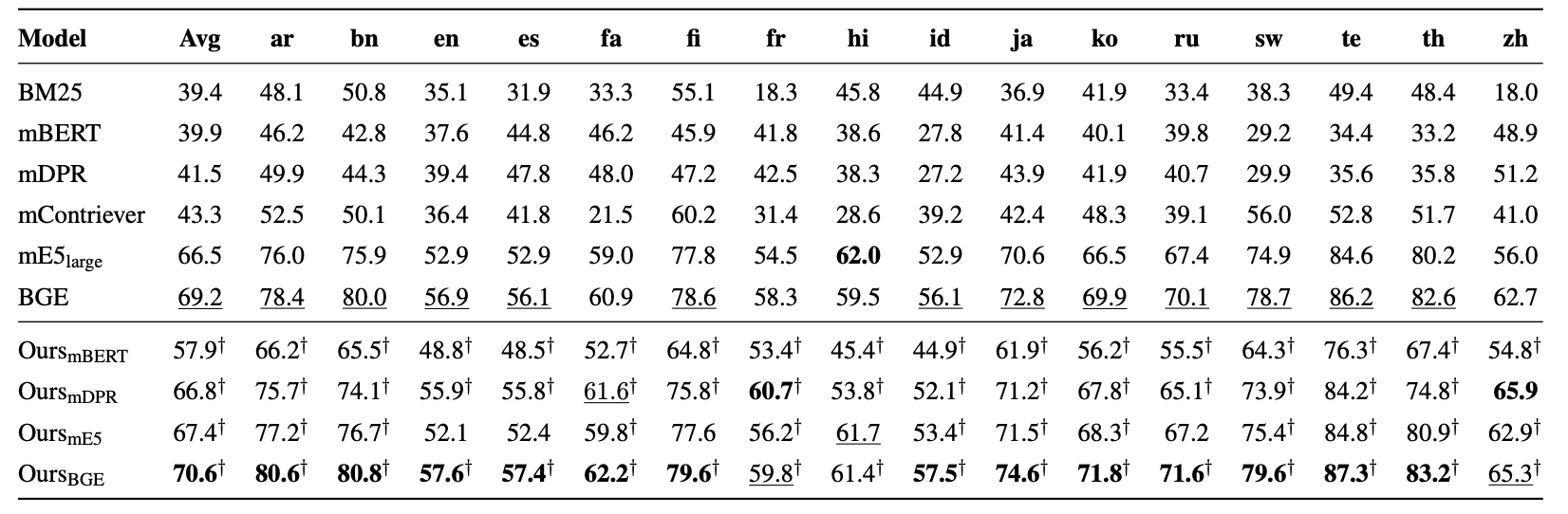
- nDCG@10 기준, 기존 최고 성능 모델인 BGE 대비 +1.4%p 향상.
- mBERT, mDPR, mE5, BGE 모든 모델에서 일관된 성능 향상을 보임.
Hard Negative 구성 방식 비교
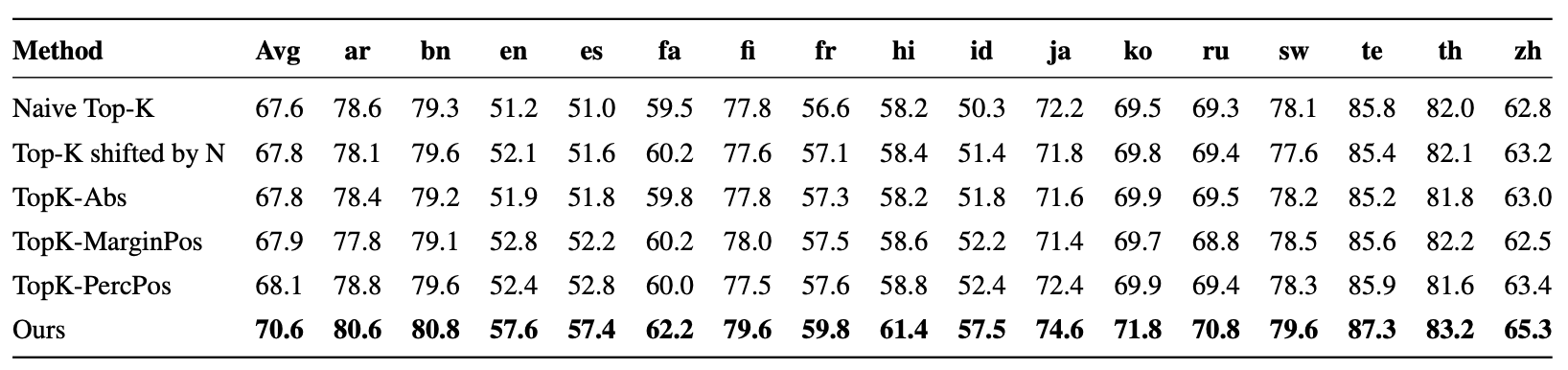
- 기존의 다양한 Hard Negative 방식들 (TopK-Shift, TopK-Margin 등)과 비교 시, 항상 최고 성능을 기록
Ablation Study
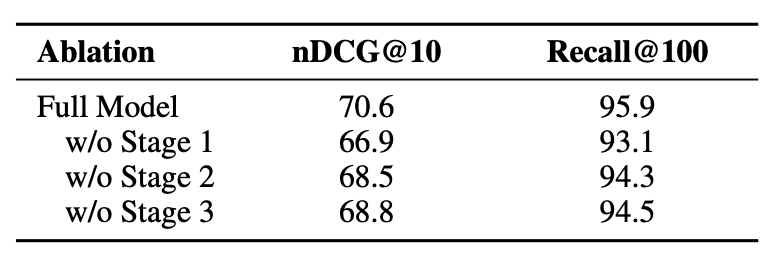
- 세 가지 스테이지 제거 시 성능이 각각 2~4% 감소 → 모든 단계가 성능에 기여함
4. 분석 및 인사이트
Hard Negative의 질

- Stage 1에서 평균적으로 19.5% false negative 제거.
- Stage 2의 LLM 생성 샘플은 전체 hard negatives의 약 9.1% 차지
Mini-Batch 구성 전략
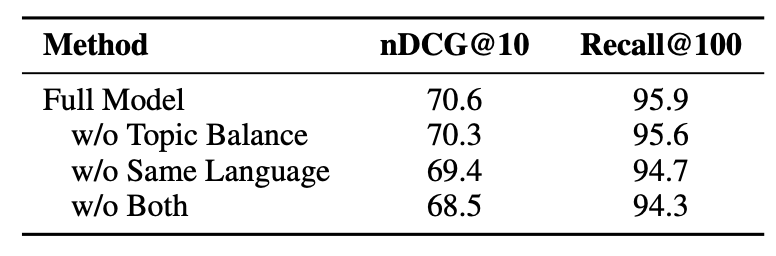
- 적당히 높은 가중치가 좋은 성능을 보여줌, 언어와 토픽 가중치가 유사할 때 좋은 성능을 보여줌.
Sampling Weight 조정
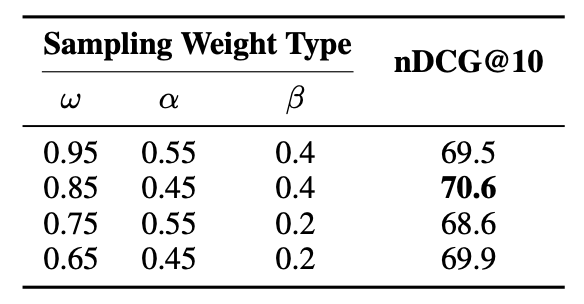
- 낮은 언어 가중치(α)와 높은 토픽 가중치(β)가 좋은 성능을 보여줌
LLM Judgment vs Ground-truth filtering
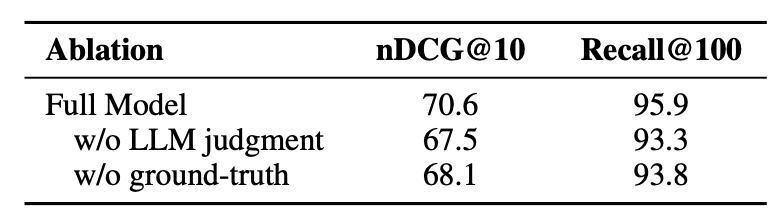
- 둘 다 제거 시 성능 하락, 특히 LLM judgment가 더 중요
- Ground-truth가 정확하지 않을 수 있음
- 예: 영어 query에 대해서는 영어 문서에 대한 Relevance 라벨은 있지만, 동일한 의미의 프랑스어 문서에는 라벨이 없을 수도 있음.
LLM Hard Negative Generation 방식

- Multilingual Instruction Fine-Tuning (MIFT)와 Positive-driven Backward Generation (PDBG)이 모두 성능 기여
결론 및 한계
- 핵심 아이디어
- 다국어 dense retrieval에서 단순 아키텍처 개선이 아니라, 데이터 활용 효율 극대화에 집중.
- 제안 방법:
- Hard negative 후보를 retriever 앙상블 + LLM filtering으로 고품질화.
- 부족한 negatives는 LLM generation으로 보충.
- Mini-batch를 monolingual + multi-topic 구조로 설계하고, 언어·토픽 기반 가중치를 적용.
- 성과:
- MIRACL 16개 언어에서 일관된 성능 향상.
- 특히 저자원 언어 성능 개선에 두드러진 효과.
- MIRACL 16개 언어에서 일관된 성능 향상.
- Limitations:
- LLM 호출이 훈련 비용을 높임 (추론 시에는 영향 없음).
- LLM 기반 false negative 판별이 완벽하지 않아 오판 가능성 존재.
- 향후에는 더 정교한 filtering 메커니즘이나 사람 기반 validation이 필요.
This post is licensed under CC BY 4.0 by the author.