CLIP-MoE: Towards Building Mixture of Experts for CLIP with Diversified Multiplet Upcycling
Written By. Jihai Zhang, Xiaoye Qu
1. 문제 정의: 기존 CLIP의 구조적 한계
기존 CLIP은 강력하지만 다음과 같은 근본적 한계가 있음:
CLIP은 feature space의 일부만 사용
- 특정 시멘틱 정보(예: 색)에는 민감하지만 texture·shape·orientation 등 다른 feature를 잘 못 잡음.
- 즉, representation collapse 수준의 정보 손실 발생.
CLIP은 MLLM의 비전 인코더로 자주 활용 → 이로 인해 MLLM에서 “blind pair” 현상 발생
- 서로 다른 의미의 이미지가 같은 embedding으로 매핑됨 → reasoning 실패.
기존 접근의 한계
데이터 품질 개선 / 거대 모델 재학습 등 노력은 대부분 from-scratch training
⇒ 비용 매우 높음.
2. Diversified Multiplet Upcycling (DMU) → CLIP-MoE
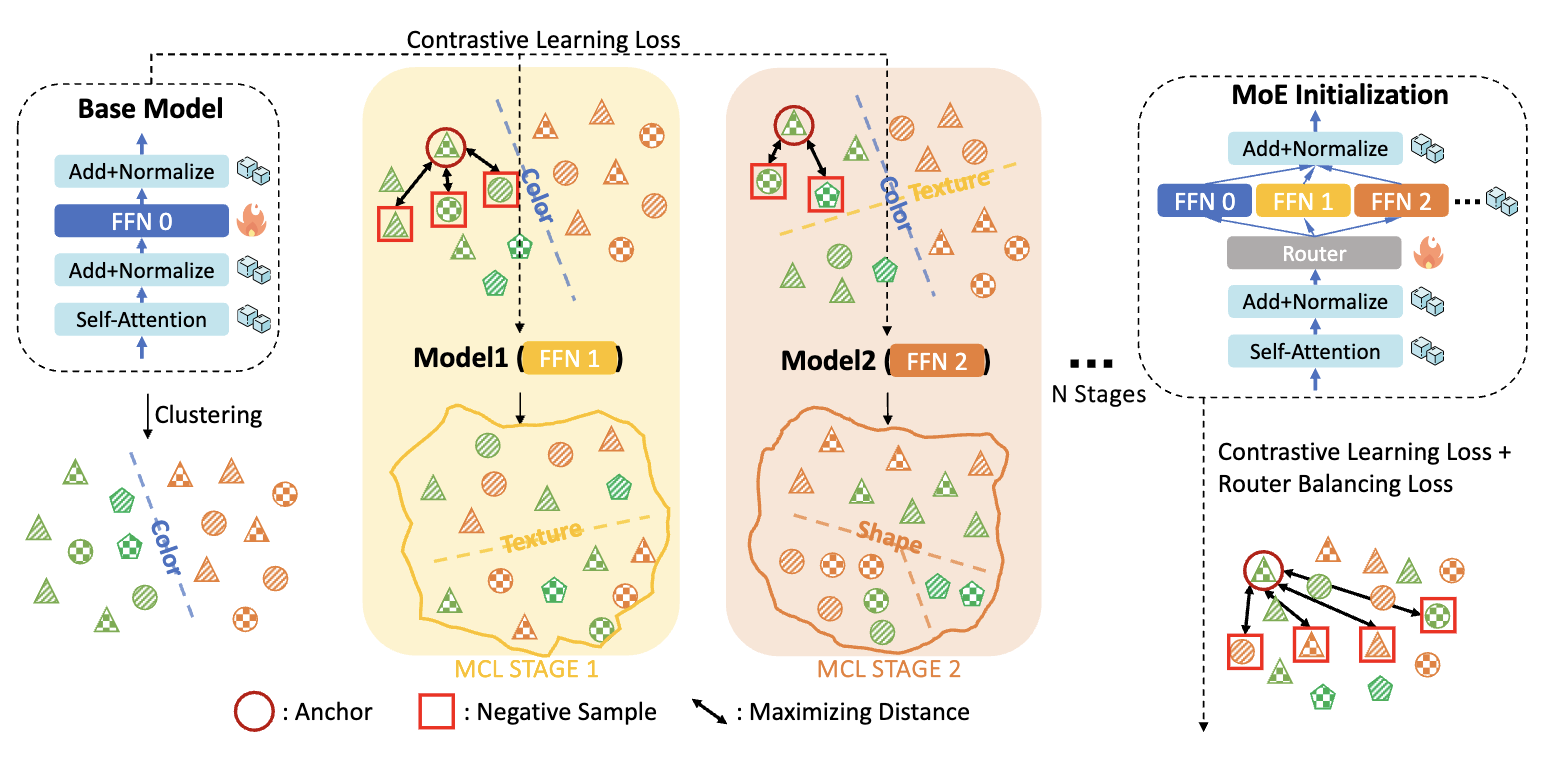
CLIP을 저렴하게 개선하는 새로운 전략:
단계 1 — MCL(Multistage Contrastive Learning)로 서로 다른 FFN 생성
- CLIP의 전체 파라미터 중 FFN(Feed Forward Network)만 stage별로 fine-tune
- Stage 0: 원래 FFN (예: 색상 정보 중심)
Stage 1: negative sampling이 color-cluster 내부에서 이루어져
→ texture 등 새로운 정보 학습
Stage 2: accumulated clustering
→ shape 등 색+texture를 구분해야 하므로 더 미세 정보를 학습
- 이 과정을 반복해 서로 다른 시멘틱 subspace를 포착한 FFN 세트 생성
→ 즉, 한 번의 모델에서 여러 “전문가 FFN”을 생성
단계 2 — 이 FFN들을 전문가(Experts)로 묶어 MoE 구성
- 원래 FFN을 Expert0, Stage1 FFN을 Expert1, Stage2 FFN을 Expert2 …
- 모든 transformer block의 FFN을 MoE layer로 대체
- Router는 랜덤 초기화 but FFN expert는 학습된 그대로 삽입
- Top-k routing (k=2)
⇒ dense CLIP → sparsely activated CLIP-MoE로 업그레이드
단계 3 — Router만 contrastive loss + load-balancing loss로 추가 학습
- FFN expert는 freeze
- Router가 각 expert를 잘 활용하도록 학습
- Load balancing loss로 특정 expert만 사용되는 현상 방지
3. MCL(다단계 대조학습)의 역할
논문의 핵심 기여 중 하나.
MCL이 왜 다양한 FFN을 만드는가?
각 stage가 이전 stage가 이미 배운 특징을 제외하고 새로운 정보를 학습할 수밖에 없는 negative sampling 구조 때문.
예시:
- Stage 0 → color 중심
- Stage 1 → 같은 color cluster 내에서 contrast ⇒ texture 중심 학습
- Stage 2 → color+texture cluster 내에서 contrast ⇒ shape 중심 학습
즉, stage가 쌓일수록 구조적으로 새로운 feature 학습을 강제함.
4. MoE로 통합할 때의 장점
Ensemble과 비교했을 때:
Ensemble은 모든 모델을 매번 forward
→ 비용 높음
→ cross-attention 불가
MoE로 만들면:
- Input에 따라 top-k expert만 선택
- 각 expert는 서로 다른 feature subspace 특화
- Parameter scale은 커지지만 activated params는 거의 동일함
5. 실험 결과
5.1 Expert specialization 분석
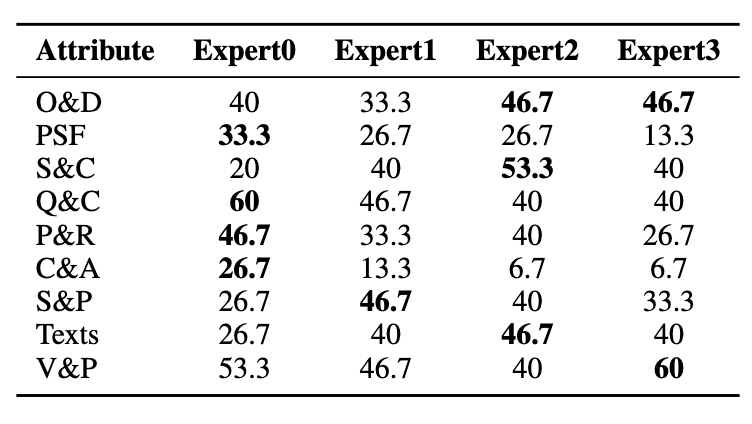
MMVP benchmark에서 attribute별 best expert가 다르게 나타남.
- Expert0 → color, quantity, appearance
- Expert1 → structure
- Expert2 → orientation, text
- Expert3 → viewpoint
정말로 MCL이 서로 다른 전문가 FFN을 만든다는 실증적 근거
5.2 Zero-shot Image-Text Retrieval
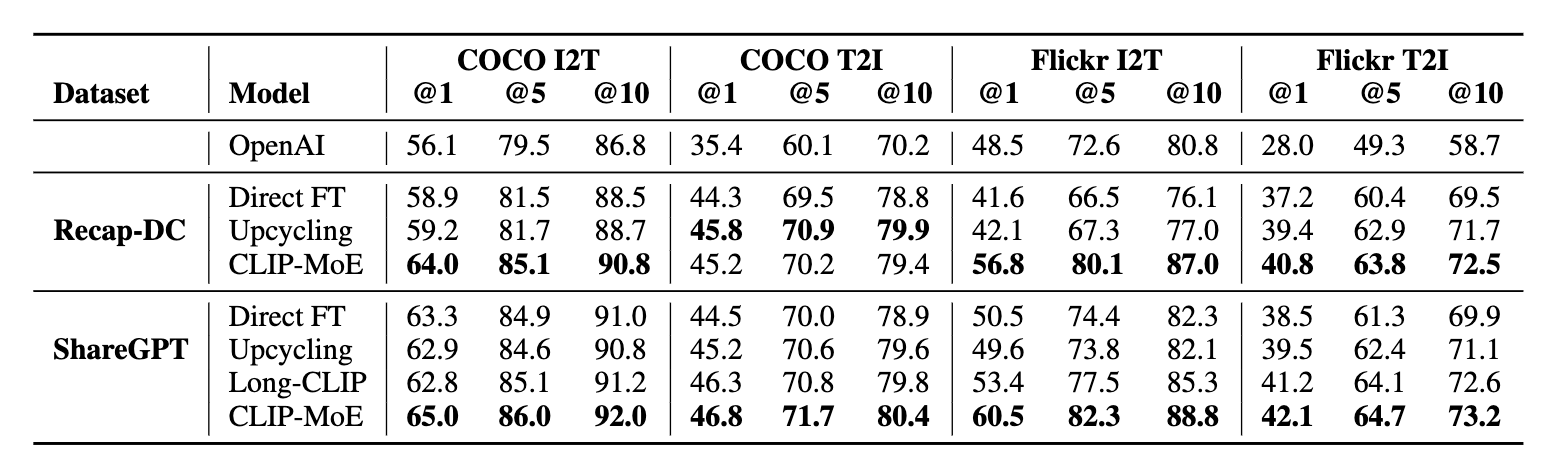
COCO / Flickr30k 기준 CLIP-MoE는:
- 모든 baseline(OpenAI, direct FT, upcycling, Long-CLIP)보다 전부 우위
- 특히 Flickr I2T 성능 폭발적 향상
- ShareGPT4V 학습 기준 → R@1: 60.5 (기존 최고보다 +7.1)
fine-grained 정보 획득 능력 증가를 명확히 입증
5.3 MLLM Vision Encoder로 사용 (LLaVA-1.5)

CLIP-ViT-L/14@336px 기반 LLaVA에 CLIP-MoE를 넣었더니:
- MMBench: +1.6
- MM-Vet: +4.2
- VizWiz: +2.5
BLIP, LLaVA 등 VLM에서 vision encoder로 plug-in 했을 때 성능 상승
5.4 Zero-shot Classification
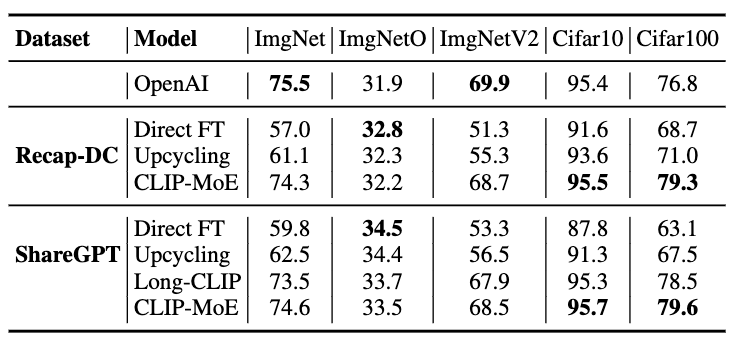
- ImageNet, ImageNetV2 같은 coarse-grained task는 큰 개선 없음
- 하지만 CIFAR10/100 일부에서 오히려 더 좋음
이유:
- MCL+MoE는 fine-grained differentiation을 강화
- coarse-grained classification은 그런 정보를 필요로 하지 않음
5.5 Ablation: MCL 없이 MoE만 붙였을 때

MCL 기반 expert 사용한 CLIP-MoE가
vanilla MoE보다 확실히 우수함
MCL이 키!
6. 훈련 효율성
- 전체 파라미터: 약 0.69B activated (4 expert 중 top-2)
- Training cost는 from-scratch CLIP(Recap) 대비 2% 이하
- GPU: 8×A100, 전체 약 2.5시간 학습
비용 대비 성능이 매우 뛰어남
7. 결론
결론
CLIP을 다시 학습하지 않고,
기존 CLIP → MCL로 다양한 FFN 생성 → MoE로 묶는 DMU 전략
- 적은 compute로 CLIP 성능 대폭 확장
- MLLM에서 vision encoder로 큰 성능 향상