Chain-of-Thought Prompting Obscures Hallucination Cues in Large Language Models: An Empirical Evaluation
Chain-of-Thought Prompting Obscures Hallucination Cues in Large Language Models: An Empirical Evaluation
Written by. Jiahao Cheng, Tiancheng Su, Jia Yuan1, Guoxiu He
연구 목적
CoT prompting은 LLM의 추론력을 향상시키고 할루시네이션 빈도를 줄이지만, 그 과정에서 할루시네이션를 감지하는 데 사용되는 내부 신호를 흐리게 만들어 기존의 detection 기법을 덜 효과적으로 만든다는 가설을 검증.
실험 개요 및 방법론
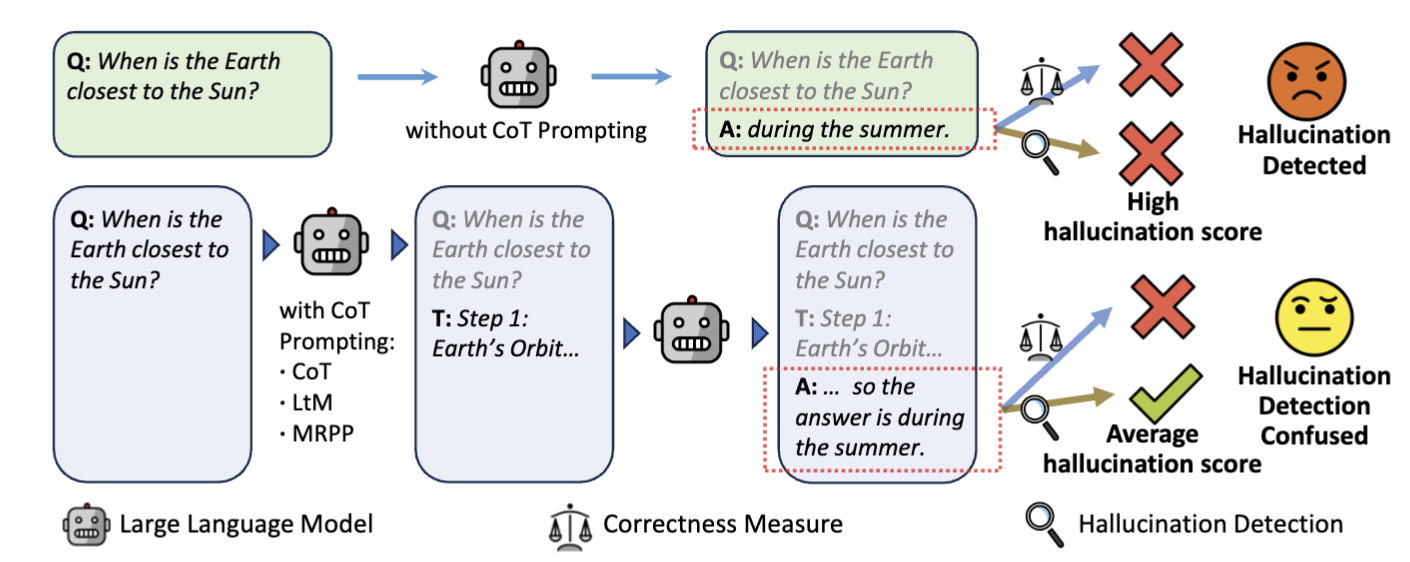
CoT Prompting 방식
세 가지 prompting 방식 사용:
- Zero-shot CoT (기본형): “Let’s think step by step”
- Least-to-Most (LtM): 복잡한 문제를 하위 문제로 나눔
- Minimum Reasoning Path Prompting (MRPP): 가장 간단한 추론 경로만 사용
- CoT 프롬프팅을 적용한 LLM은 모든 데이터셋에서 일관되게 더 높은 정확도를 달성
- 예시: Llama-3.1-8B-Instruct의 경우, 세 데이터셋에서 정확도가 각각 90.5, 90.16, 80.79에서 97.67, 94.96, 91.57로 향상
- 그러나 더 고급 CoT 변형의 효과는 덜 일관적
- LtM은 다중 경로 추론을 사용하지만, 여러 그럴듯한 추론 경로에 직면했을 때 모호성으로 인해 기본 Llama보다 성능이 좋지만 표준 CoT에는 미치지 못함.
- MRPP는 신뢰도 기반 검증을 추가로 통합하여 기본 CoT 접근 방식보다도 뛰어난 성능을 보임.
- 엔트로피 감소 및 신뢰도 증가:
- CoT 프롬프팅 후 모든 LLM에서 엔트로피가 일관되게 감소
- 이는 LLM이 예측에 대해 더 확신을 가지게 되어 선택한 답변에 더 높은 확률을 할당함을 시사
- 예시: Llama의 엔트로피는 CoT 적용 후 각각 23.96, 26.33, 46.94에서 6.63, 13.50, 21.39로 감소.
- 다른 CoT 전략에서도 유사한 감소가 관찰되어 모델 신뢰도의 전반적인 향상을 반영
사용된 LLM 모델들
- Llama-3.1-8B-Instruct
- Mistral-7B-Instruct-v0.3
- DeepSeek-R1-Distill-Llama-8B
- Llama-3.1-80B-Instruct
- 추론 능력에 최적화된 DeepSeek-R1-Distill-Llama-8B 모델은 추론이 비활성화되었을 때 예상보다 훨씬 낮은 성능을 보임.
- CoT가 활성화되면 성능이 크게 향상되지만, 정확도 면에서는 여전히 Llama에 뒤처짐.
- 흥미롭게도 CoT 프롬프팅 하에서 DeepSeek은 모든 데이터셋에서 Llama보다 낮은 엔트로피를 보여, 더 많은 오답을 생성함에도 불구하고 예측에 대한 더 큰 신뢰도를 시사.
실험 데이터셋
- MCQA: CommonSenseQA, ARC-Challenge, MMLU - 객관식 질문 답변(MCQA) 데이터셋
- CommonsenseQA: 상식 추론 평가를 위해 설계된 벤치마크.
- ARC-Challenge: 고급 추론이 필요한 과학 관련 질문에 중점을 둔 도전적인 데이터셋
- MMLU: 광범위한 학술 및 전문 분야를 포괄하는 대규모 벤치마크로, 일반 지식 및 추론 능력을 종합적으로 평가
- Fact-based QA: TriviaQA, PopQA, HaluEval, TruthfulQA - 복잡한 추론이 필요한 네 가지 QA 데이터셋
- TruthfulQA: 환각 탐지를 위해 명시적으로 설계된 데이터셋
- TriviaQA: 대규모 독해 데이터셋
- PopQA: 엔티티의 롱테일 분포를 대상으로 하는 질문을 포함하는 데이터셋
- HaluEval: LLM 생성 콘텐츠의 사실적 정확도를 평가하는 데이터셋
- Summarization: CNN/Daily Mail - 문맥 이해가 필요한 한 가지 요약 데이터셋
- CNN/DailyMail: 주어진 뉴스 기사를 기반으로 요약을 생성해야 하는 요약 데이터셋.
주요 실험 결과
1. CoT는 정답률 향상시키지만…
- 모든 LLM에서 정확도는 증가 (예: Llama-3.1-8B-Instruct는 CoT 적용 시 정확도 상승).
- 하지만 AUROC(할루시네이션 감지 민감도)은 감소, 즉 감지 성능은 저하됨.
2. Confidence shift: 확신은 높아졌지만 더 틀림
- CoT 이후 LLM의 confidence는 증가, 하지만 틀린 답에도 높은 확신을 가짐.
- 이는 detection 모델이 hallucination을 덜 민감하게 감지하게 만듦.
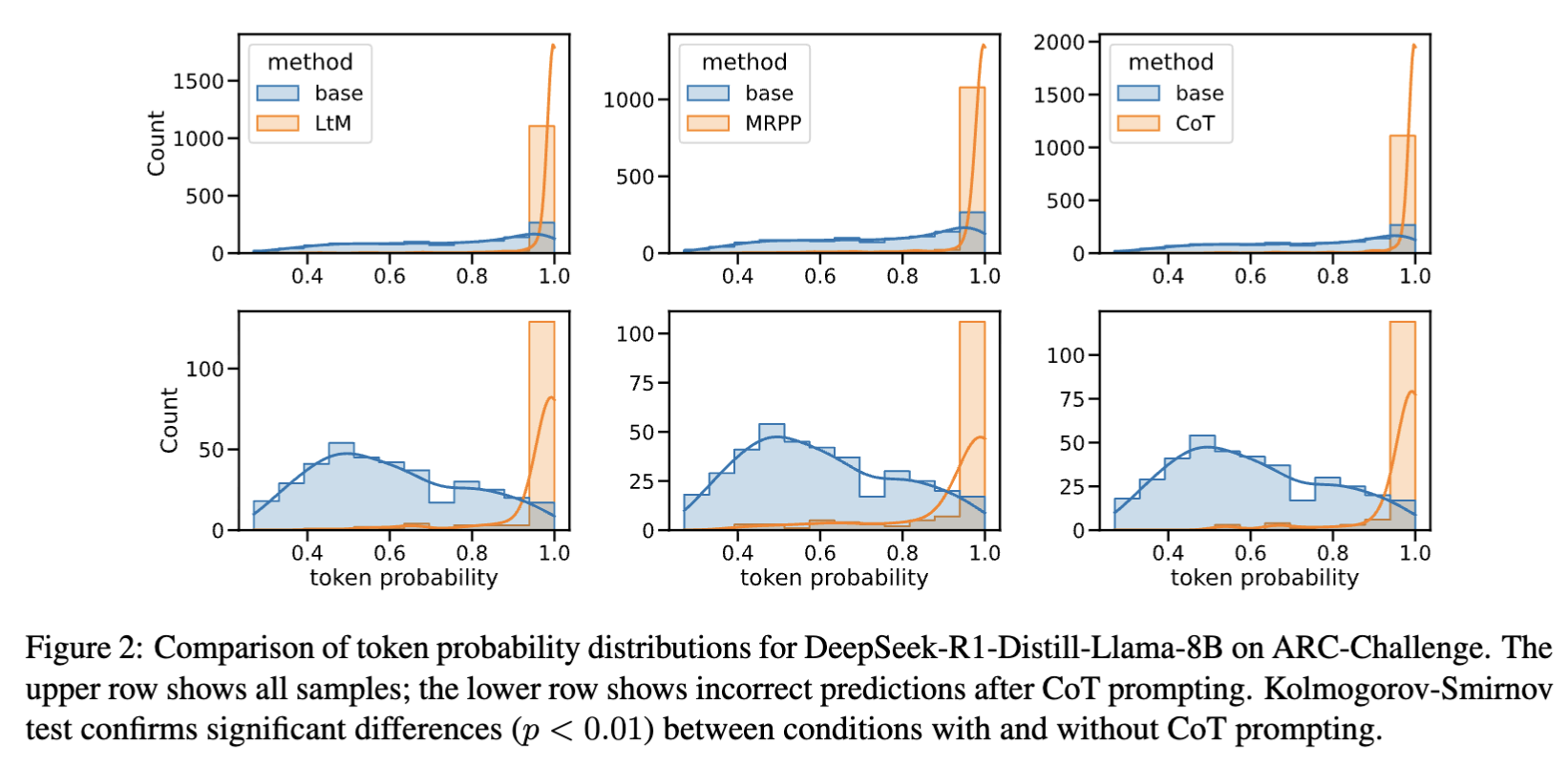
- Figure 2의 그래프는 틀린 답변도 높은 토큰 확률로 생성됨을 보여줌.
- CoT 프롬프팅 전에는 LLM이 샘플 전반에 걸쳐 비교적 균일한 확률 분포를 보이며, 환각 샘플의 경우 분포가 왼쪽으로 치우쳐 있어 오답이 낮은 확률을 받는 경향이 있음을 나타냄.
- 그러나 CoT 프롬프팅 후에는 분포가 이동하여 LLM이 올바른 답변과 오답 모두에 유사하게 높은 확률을 할당.
- 대부분의 hallucination detection 모델들은:
- Hidden state vector, attention, logits, confidence 등을 입력으로 받아
- 이 응답이 거짓일 가능성이 있는가?를 판단.
- 그런데 CoT를 적용하면:
- 정답이든 오답이든 매우 유사한 구조의 추론 문장을 생성하게 되고
- Hidden states도 비슷한 분포를 형성 (아래 Figure 4 참조)
3. Detection 방법별 영향
- Self-evaluation 기반 감지법(예: Verbalized Certainty)은 CoT에 특히 취약.
- 예: 잘못된 답이라도 “Based on Wikipedia…” 같은 추론을 포함하며 거짓된 신뢰감을 전달.
- Consistency 기반 감지법(예: EigenScore, SelfCheckGPT-NLI)은 비교적 강건.
Consistency 기반 감지법이란? 모델이 자신을 얼마나 “일관되게” 유지하는지를 이용해 감지하는 방법.
- 대표 기법
- SelfCheckGPT
- 동일한 질문을 모델에게 여러 번 묻고,
- 생성된 응답들이 서로 얼마나 일치하는지 측정
- 불일치 정도가 클수록 hallucination 가능성이 높음
- NLI 기반 방법 (예: SelfCheckGPT-NLI)
- 모델의 응답을 claim으로 보고,
- 여러 증거 문장들과 Natural Language Inference (NLI)를 수행
- NLI란?
- 주어진 두 문장(전제 Premise와 가설 Hypothesis) 사이의 관계를 아래 세 가지 중 하나로 분류하는 과제:
- Entail / Neutral / Contradict 판별
관계 설명 예시 Entailment 전제를 바탕으로 가설이 참일 수밖에 없음 Premise: “모든 고양이는 포유류다.” Hypothesis: “고양이는 포유류다.” Contradiction 전제와 가설이 모순됨 Premise: “그는 결혼했다.” Hypothesis: “그는 독신이다.” Neutral 전제를 바탕으로 가설의 진위를 판단할 수 없음 Premise: “그는 공원에 있다.” Hypothesis: “그는 운동 중이다.” - NLI란?
- Contradict 비율이 높으면 hallucination일 가능성 ↑
- EigenScore
- 응답을 여러 방식으로 재작성해보고, 그 결과들을 latent space에서 비교해 표현 일관성을 측정
- LLM에 같은 질문을 여러 번 반복해서 응답 생성
- 예: 동일한 질문을 5회 반복 → 각 응답을 벡터(임베딩)로 변환
- 공분산 행렬 계산
- 우리가 가진 건: X=[x1,x2,x3,x4,x5]∈R5×d
- x_i: LLM 응답 벡터 (예: 768차원)
- 총 5개 응답 → 5행 768열 행렬 - 공분산 행렬(C)을 계산
- $C = \frac{1}{n-1} X^\top X$ - 이 행렬은 각 차원 간에 얼마나 함께 변동하는지를 측정.
- 고유값(Eigenvalue) 추출
- Why?~
- 각 고유값은 그 방향(고유벡터)으로의 분산의 크기를 나타냄
- 첫 번째 고유값은 데이터가 가장 많이 퍼져 있는 방향의 분산
- 즉,
- 이 첫 번째 고유값이 작다 → 벡터들이 특정 방향으로 응집해 있음 → 응답이 서로 유사함 → 일관성 높음
- 고유값이 크다 → 벡터들이 흩어져 있음 → 응답이 서로 다름 → hallucination 의심
- Why?~
- SelfCheckGPT
- 기존 방식과 차이
- Confidence-based: 모델이 얼마나 확신하는지(Hidden score, token probability 등)
- Consistency-based: 모델이 얼마나 자기 모순 없이 말하는지를 기반
4. 내부 상태 변화
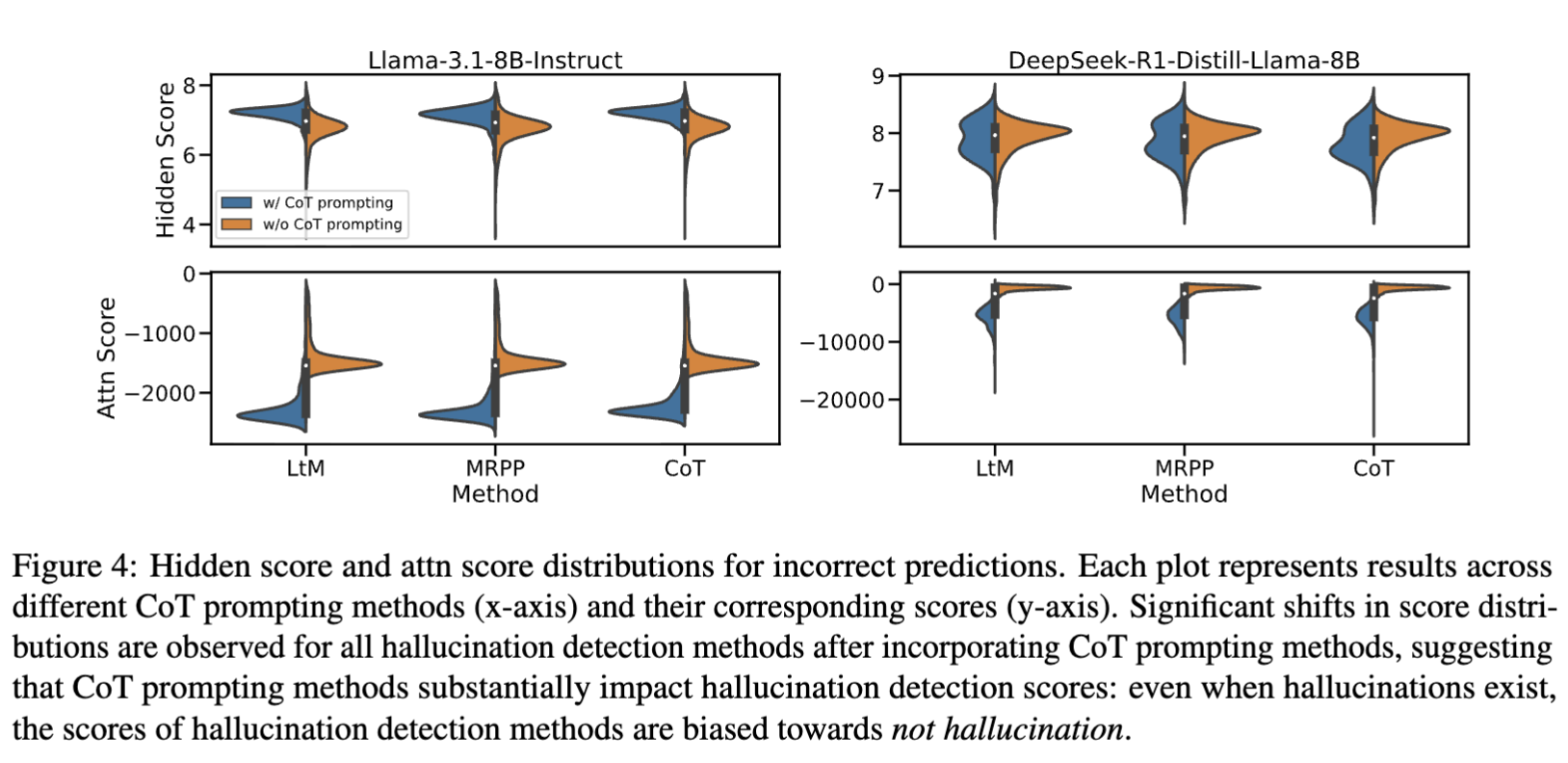
- Figure 4에 따르면 CoT는 LLM 내부의 Hidden Score와 Attention Score 분포를 밀집시킴.
- CoT를 적용하면 Hidden/Attention Score의 분포가 좁고 밀집된 범위로 수렴.
- 즉, 모든 응답이 (맞든 틀리든) 비슷한 수준의 confidence와 attention 집중도를 가지게 됨.
- 이로 인해 정답/오답 간 구분이 흐려짐.
- 즉, 감지 모델이 hallucination을 구분하기 어려워짐.
5. Calibration (모델 신뢰도 정합성)
- CoT 이후 Expected Calibration Error(ECE)가 증가 → 감지 모델이 잘못된 confidence 판단을 하게 됨.
ECE란? ECE는 모델의 예측 확률(confidence)과 실제 정답률(accuracy) 사이의 평균적인 차이를 측정한 값
- 즉, 모델이 “나는 90% 확신해”라고 말했을 때, 실제로 그 예측이 90% 맞아야 잘 calibrated 된 것
ECE는 다음과 같은 방식으로 계산:
- 모델의 예측들을 confidence 값에 따라 여러 bin으로 나눔.
- 각 bin마다:
- 예측 평균 confidence: 예측들이 얼마나 자신 있었는지.
- 정답률(accuracy): 실제로 얼마나 맞았는지.
- 각 bin에서 두 값의 차이의 절댓값을 계산한 후, 전체 예측에 대한 가중 평균을 계산
여기서:
- B_m은 m번째 bin,
- n은 전체 예측 수,
- acc(Bm)은 해당 bin의 정확도,
- conf(Bm)은 해당 bin의 평균 confidence.
즉,
- ECE가 낮을수록 → 모델의 confidence는 실제 정확도와 잘 맞음 = 잘 calibrated
- ECE가 높을수록 → 모델은 과도한 자신감을 보이거나, 반대로 자신감 부족일 수도 있음 = 부정확한 확신
예시:
- 모델이 “난 95% 확신해” 라고 했는데 실제로 60%만 맞는다면 → 높은 ECE → 위험
결론 및 시사점
- CoT는 응답의 정확성과 해석 가능성은 높여주지만, hallucination 감지력을 떨어뜨리는 이중적 효과를 가짐.
- 기존의 감지 시스템은 CoT로 인해 성능 저하 또는 baseline 방법(Perplexity)에 비해 나은 성능을 보이지 못하는 경우도 발생.
- 이는 CoT-friendly한 새로운 감지 기법 개발의 필요성을 시사함.
This post is licensed under CC BY 4.0 by the author.