CollabEval: Enhancing LLM-as-a-Judge via Multi-Agent Collaboration
CollabEval: Enhancing LLM-as-a-Judge via Multi-Agent Collaboration
Written By. Yiyue Qian, Shinan Zhang, Yun Zhou, Haibo Ding, Diego Socolinsky, Yi Zhang
1. 문제 정의
- 배경
- AI 생성 결과를 사람이 아니라 LLM이 평가하는 LLM-as-a-Judge 패러다임의 확산
- 문제 1: 단일 LLM 평가의 편향
- 사전학습 데이터와 지식 차이에서 비롯되는 모델들의 편향
- 특정 모델의 성향으로 평가 결과가 영향을 받을 수 있음.
- 문제 2: 일관성 부족
- 동일 유형의 입력에 대해서도 모델별 판단 차이 발생 가능성
- 평가 안정성과 객관성 확보의 어려움
- 문제 3: 평가 차원별 성능 편차
- 어떤 모델은 relevance에 강하고 coherence에는 약한 식의 메트릭별 편차 존재
- 단일 judge 기반 평가의 범용성 부족
- 핵심 문제 4: 기존 multi-agent 방식의 한계
- 기존 접근의 중심이 되는 debate 기반 구조의 비효율성 → 정확한 판단보다는 debate를 이기는 것에 초점을 맞춰 대화가 길어지는 등의 부작용이 발생함.
- 다양한 평가 시나리오에 대한 유연성 부족
- 논문의 문제의식
- 평가 역시 복잡한 추론 과정이라는 전제
- 단일 모델의 판단보다,
- 여러 모델의 독립 평가
- 근거 비교
- 협업을 통한 수정
최종 정리
가 더 신뢰 가능하다는 관점
- 최종 목표
- 더 강건한 평가 프레임워크 구축
- 더 일관된 판단 구조 확보
- 더 효율적인 multi-agent 평가 체계 설계
2. 해결방법: CollabEval
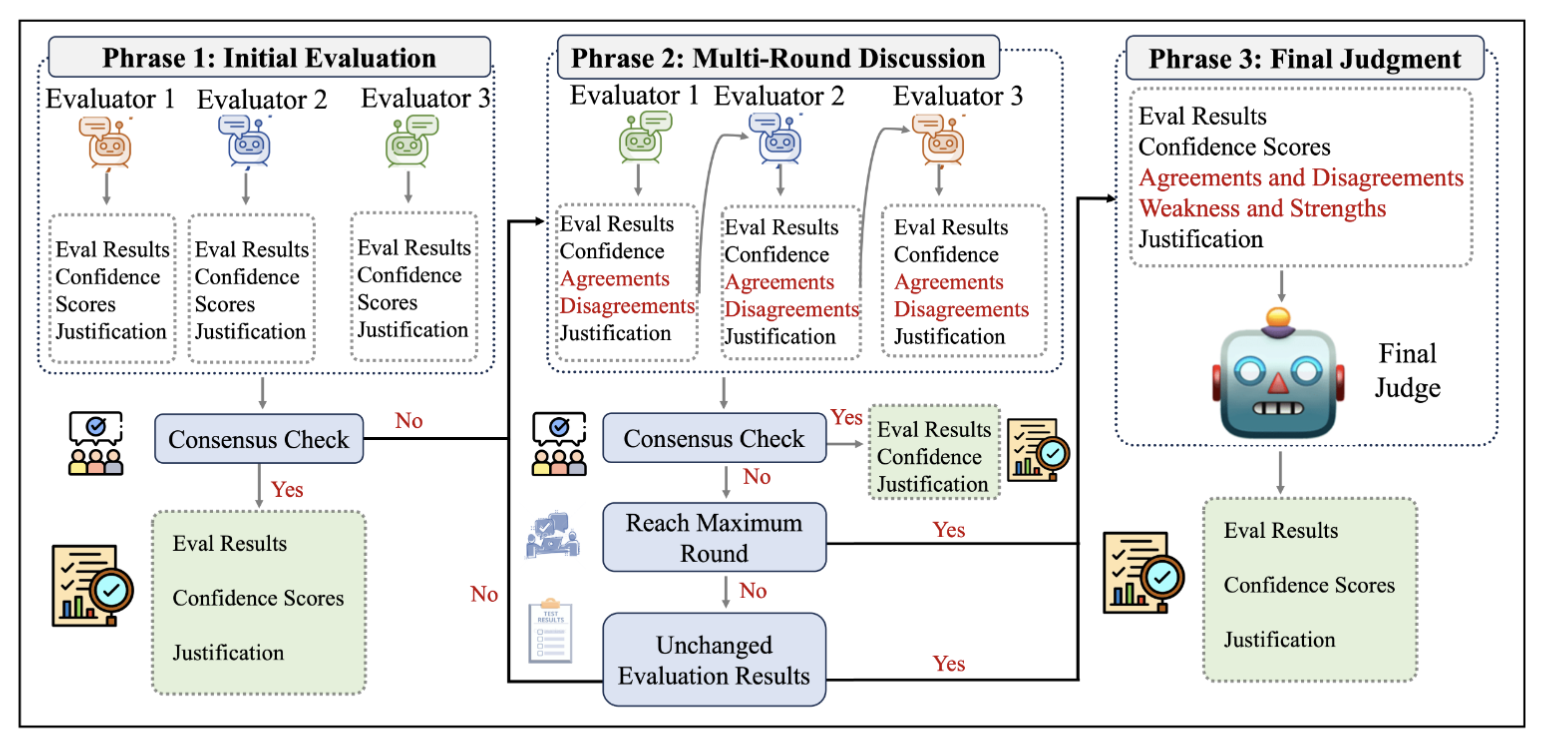
2-1. 핵심 아이디어
- 기본 개념
- 여러 LLM evaluator의 협업 기반 평가 프레임워크
- 경쟁적 debate가 아니라 협력적 collaboration 중심의 설계
- 전체 구조
- Initial Evaluation
- Multi-Round Discussion
Final Judgment
의 3단계 구조
- 핵심 차별점
- 단순 다수결 방식이 아닌 평가 오케스트레이션 시스템이라는 점
- 합의 여부를 단계별로 점검하는 consensus-driven 구조
2-2. Phase 1: Initial Evaluation
- 목적
- 각 evaluator의 고유한 시각과 강점을 서로 간섭 없이 확보하는 단계
- 수행 방식
- 여러 evaluator의 독립적 평가 수행
- 각 evaluator의 출력 항목
- 평가 결과
- confidence score
- detailed justification
- 의미
- 단순 점수 수집이 아니라 이후 토론에 활용 가능한 구조화된 판단 기록 확보
- 독립적으로 결과를 도출하여 다른 모델 의견에 끌리는 anchoring 효과 방지 목적
- 합의 검사
- 모든 evaluator의 결론 일치 시 즉시 종료 구조
- 불일치 존재 시 Phase 2로 이동하는 조건부 진행 구조
- 설계 의의
- 토론을 항상 수행하지 않고 필요할 때만 수행하는 효율성 중심 설계
2-3. Phase 2: Multi-Round Discussion
- 핵심 역할
- evaluator들이 서로의 평가와 근거를 참고해 자기 판단을 수정·정교화하는 단계
- 각 evaluator가 참고하는 정보
- 모든 agent의 초기 평가 결과
- 이전 라운드의 confidence score
- agreement / disagreement 정보
- 다른 evaluator의 justification
- 토론의 성격
- 상대를 이기기 위한 반박 중심 토론이 아닌 협업형 심의 구조
- 다른 모델들의 근거를 반영해 판단을 보정하는 과정이라는 점이 핵심
- 라운드 진행 방식
- 한 evaluator의 업데이트 결과가 다음 evaluator의 입력으로 누적 반영되는 순차 구조
- 한 라운드 내부에서도 평가 정보가 점진적으로 축적되는 형태
- 효과
- 단순 결론 교환이 아닌 쟁점을 중심으로 불일치를 해결하기 위한 구조
- “누가 무엇을 판단했는가”보다 “왜 동의·비동의하는가”를 드러내는 정보 축적 방식
- order bias 완화 장치
- 특정 모델의 과도한 대화 흐름 지배 방지 목적 → evaluator 발화 순서의 랜덤 셔플 적용
2-4. Consensus Check와 종료 조건
- 매 라운드 종료 시 확인 항목
- 현재 라운드에서 합의 도달 여부
- 최대 라운드 수 도달 여부
- 이전 라운드 대비 결과 변화 여부
- 종료 규칙
- 합의 도달 시 즉시 종료
- 합의 미도달이더라도
- 최대 라운드 수 도달
결과 변화 없음
중 하나 충족 시 Phase 3 진입
- 위 조건 미충족 시 다음 discussion round 진행
- 장점
- 불필요한 반복 토론 방지
- 성능과 계산 비용의 균형 추구
2-5. Phase 3: Final Judge Evaluation
- 진입 조건
- multi-round discussion 이후에도 합의 실패인 경우
- 혹은 평가 결과가 더 이상 바뀌지 않는 경우
- 최종 judge가 참고하는 정보
- 이전 모든 라운드의 평가 결과
- confidence score
- justification
- agreement / disagreement 정보
- 토론 과정 속 평가 변화 추이
- 역할
- 처음부터 새로 평가하는 judge가 아니라, 전체 기록을 읽고 최종 판정을 내리는 메타 judge 역할
- 실험 설정
- final judge로 Claude Sonnet 3.5 사용
2-6. 이 방법이 효과적인 이유
- 효과 1: 다양성 확보
- 서로 다른 모델의 상이한 편향을 조합해 단일 모델의 극단적 성향 완화 효과
- 효과 2: 근거 기반 상호 보정
- justification과 disagreement 공유를 통한 오류 보정 구조
- 강한 모델이 약한 모델의 판단 오류를 교정할 수 있는 구조적 가능성
- 효과 3: 효율성 확보
- consensus check와 early stopping을 통한 불필요한 계산 감소
- 한 줄 요약
- 독립 평가 → 근거 공유 → 합의 확인 → 필요 시 최종 판정의 계층형 평가 시스템이라는 점이 핵심
3. 실험
3-1. 실험 목적
- CollabEval이
- 단일 LLM judge보다 우수한지
기존 multi-agent 평가보다 우수한지
를 검증하는 목적
3-2. 평가 모드
- Criteria-based Evaluation
- coherence(글의 흐름이 자연스러운지), consistency(생성된 내용이 원문 사실과 일치하는지), fluency(문장이 문법적으로 자연스럽고 읽기 편한지), relevance(생성 결과가 입력/원문/질문의 핵심에 얼마나 관련되어 있는지) 등 다차원 점수 평가 방식
- Pair-wise Comparison
- 두 응답 중 어느 쪽이 더 우수한지 판단하는 방식
3-3. 데이터셋
- SummEval
- criteria-based 평가용 데이터셋
- 1600개 예시
- 100개 뉴스 기사 기반
- 16개 모델 생성 요약 포함
- 8명의 전문가가 4개 차원 점수 부여 구조
- chatbot_arena_conversations
- pairwise 비교용 데이터셋
- 1000개 랜덤 샘플 사용
- lmsys_arena_human_preference_55k
- 인간 선호 기반 pairwise 비교용 데이터셋
- 1000개 랜덤 샘플 사용
3-4. 비교 대상
- Single LLM-as-a-Judge
- Mistral Large
- Claude Haiku
- Claude Sonnet 3
Llama 3 70b
각각을 단독 evaluator로 활용한 baseline
- Agent-based LLM-as-a-Judge
- Round-Table Agents Eval baseline 사용
- 순차적 평가 전달 구조
- 최대 라운드 후에도 합의 실패 시 다수결 적용 구조
- CollabEval 실제 구성
- evaluator:
- Mistral Large
- Claude Haiku
- Claude Sonnet
- Llama 3 70b
- 최대 discussion round: 3회
- final judge: Claude Sonnet 3.5
- evaluator:
3-5. Criteria-based 평가 결과
- SummEval 평가 결과
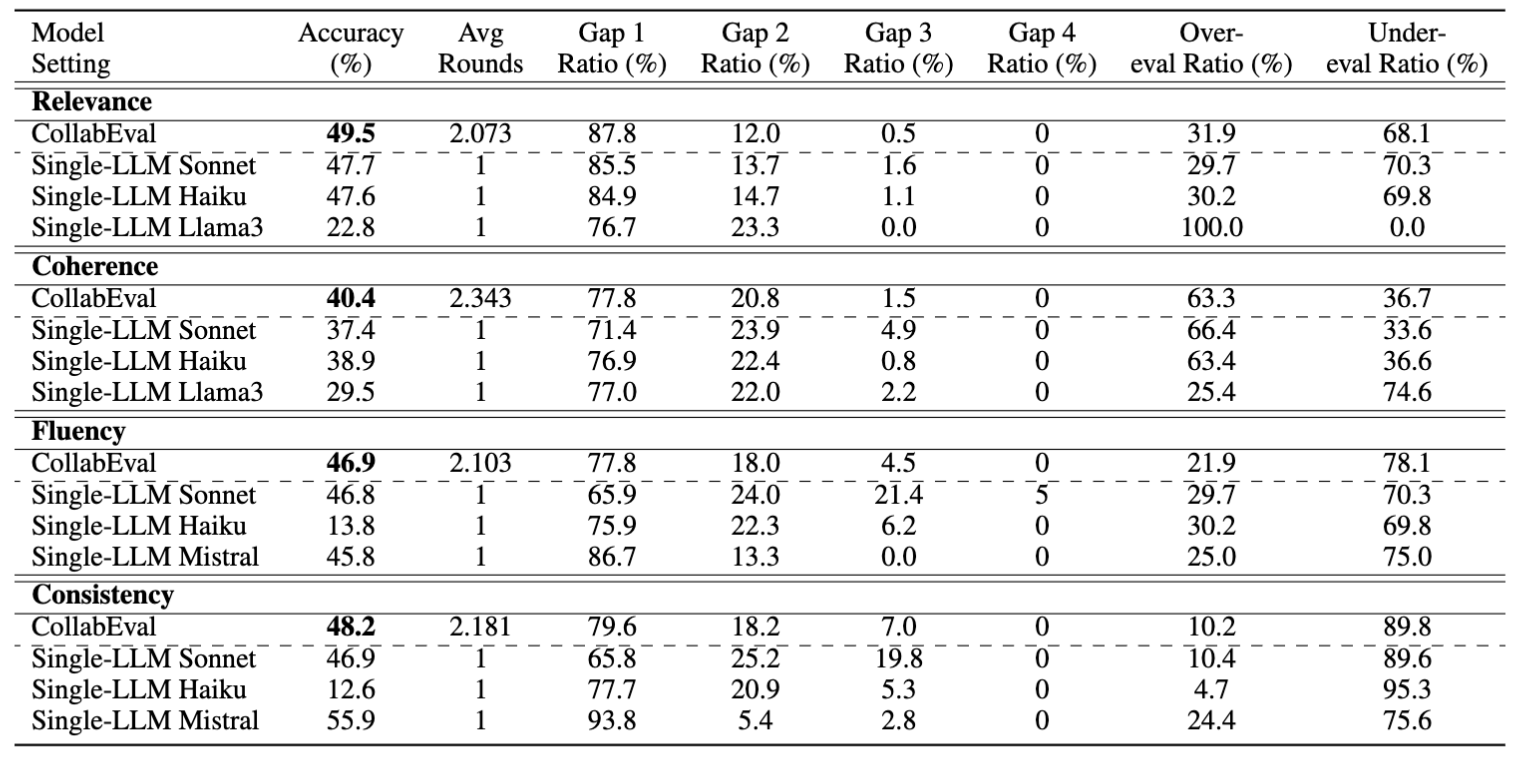
- GAP N Ratio : 모델 평가가 틀렸을 경우 실제 정답과의 차이가 N점인 경우의 비율 / Over-eval Ratio : 오답 중에서 모델 점수가 정답보다 높은 경우의 비율(Under은 그 반대)
- relevance, coherence, fluency에서 단일 LLM 대비 최고 또는 근접 최고 수준 성능
- 잘못 판단해도 큰 폭의 오류보다는 근소하게 틀림.
- 주의점
- Consistency 정확도에서는 Single-LLM Mistral 55.9%가 CollabEval 48.2%보다 높음
- 따라서 모든 단일 수치에서 절대 우위라기보다,
- 정확도
- 안정성
편향 완화
를 함께 달성한 점이 핵심 강점이라는 해석이 적절할듯?
3-6. Pair-wise 비교 결과
- Chatbot Arena Data / Arena Human Preference Data 평가 결과
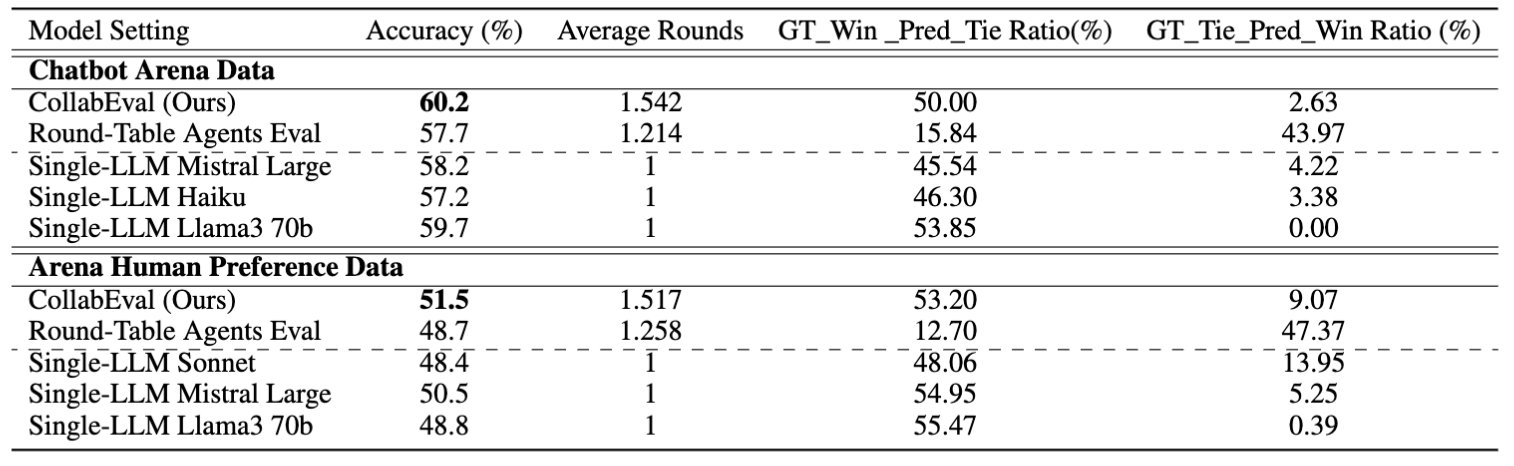
- 두 pairwise 데이터셋 모두에서 CollabEval 최고 정확도 기록
- 평균 라운드 약 1.5회 수준 : multi-agent 방식임에도 과도한 토론 길이 미발생
- GT_Win_Pred_Tie, GT_Tie_Pred_Win 비율 분석을 통해, 애매한 경우를 무리하게 단정하지 않으면서도 필요한 경우 명확한 승패 판단 수행 가능성 제시
3-7. 추가 분석 1: Discussion Round 수의 영향
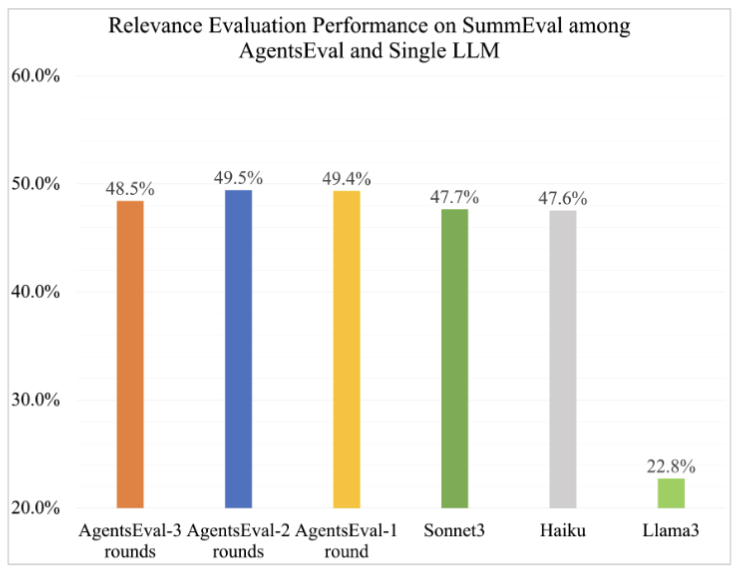
- 첫 discussion round에서 가장 큰 성능 향상 발생, 2라운드에서 소폭 개선, 3라운드에서 오히려 약간 하락하는 패턴
- 논문 해석 : 초반 라운드에서 핵심 정보 대부분 교환한 후에는 정보 포화 발생
- 실무적 : 라운드 수 증가가 항상 성능 향상을 의미하지 않음 → 실험 해봐야 안다.
3-8. 추가 분석 2: Gap Ratio 분석
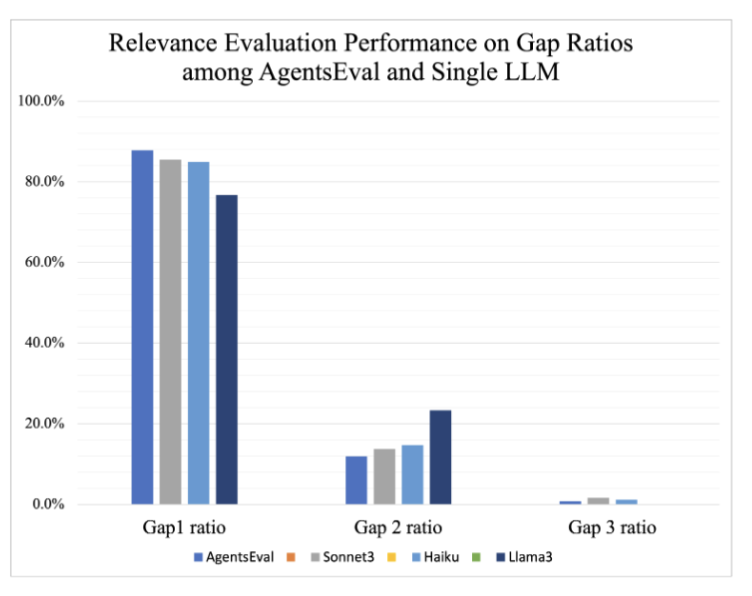
- CollabEval의 가장 높은 Gap 1 ratio를 보이고 Gap 2, Gap 3로 갈수록 빠르게 감소하는 패턴 → 오류 발생 시 대부분 작은 오차 수준에 머무는 정밀한 평가 경향
3-9. 추가 분석 3: Evaluation Pattern 분석
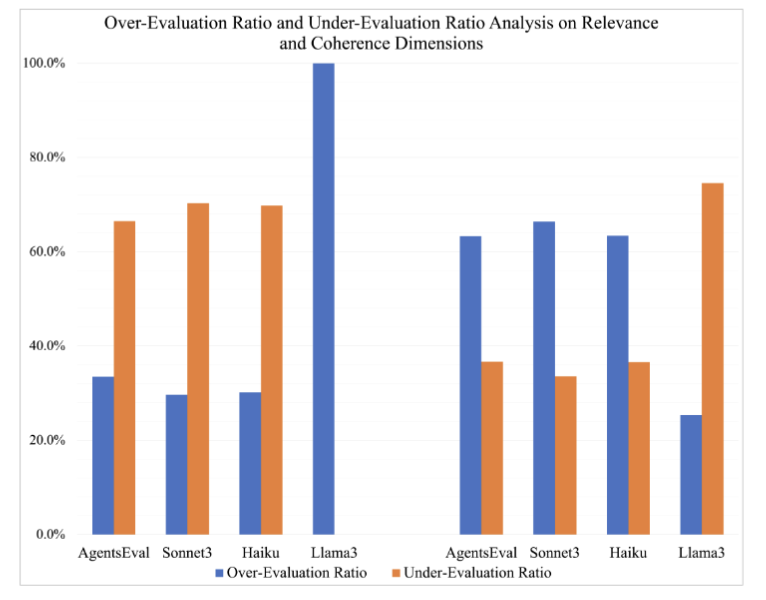
- relevance에서는 CollabEval, Sonnet, Haiku가 대체로 under-evaluation 경향
- coherence에서는 동일 모델들이 over-evaluation 경향
- 의미 : 편향은 모델 고유 특성뿐 아니라 평가 차원에 따라서도 달라지는 현상, 단일 judge보다 multi-agent 조합이 유리할 수 있다는 근거
3-10. 추가 분석 4: Robustness와 Consistency
- 일부 개별 모델이 약해도 CollabEval 전체 성능의 급격한 붕괴 미발생
- 대표 사례
- relevance에서 Llama3 정확도 22.8%, 반면 CollabEval은 1 round만으로 49.4% 유지
- 논문 해석 : 단순 평균 효과가 아니라, 서로 다른 evaluator의 장단점을 조율하는 orchestration mechanism의 결과라는 설명
3-11. 추가 분석 5: Collaboration vs Debate
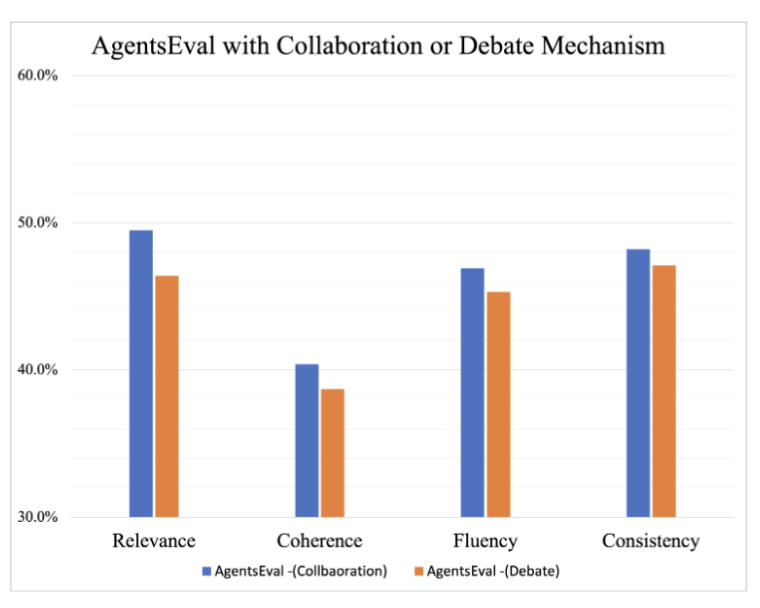
- relevance, coherence, fluency, consistency 전 차원에서 collaboration 방식이 debate 방식보다 높은 정확도 기록
- 의미 : 평가 문제에서는 반박 중심 구조보다, 정보 공유와 합의 형성 중심 구조가 더 효과적이라는 결론
4. 결론
- 단일 LLM judge보다 여러 LLM의 협업형 평가 구조가 더 우수하다는 주장
- 확인된 장점
- 편향 완화 효과
- 일관성 향상 가능성
- 개별 모델 약점에 대한 강건성 확보
- CollabEval
- 단순 다수결 시스템이 아니라, 독립 평가 + 협업적 근거 통합 + 최종 메타 판정 구조의 평가 오케스트레이션 프레임워크라는 점
- 실험적 결론
- pairwise 평가에서는 일관된 최고 성능, criteria-based 평가에서도 전반적으로 강한 성능
- 특히 편향 완화와 안정성 측면에서 의미 있는 결과 확인
- 주의
- 모든 세부 지표에서 절대적 최고 성능은 아님
- 일부 차원에서는 특정 단일 모델의 더 높은 정확도 존재
- 그럼에도 CollabEval의 핵심 가치는 최고 정확도 하나가 아니라 균형성, 강건성, 편향 완화, 실용적 효율성의 동시 확보에 있음
5. 요약
- 문제
- 단일 LLM judge의 편향, 일관성 부족, 차원별 성능 편차, 기존 debate형 multi-agent의 비효율성
- 해결
- 독립 초기 평가
- 다중 라운드 협업 토론
최종 judge 판정
의 3단계 CollabEval 구조 제안
- 핵심 차별점
- debate가 아니라 collaboration 중심 구조
- confidence, justification, agreement/disagreement 활용
- consensus check 기반 조기 종료 메커니즘
- 실험 결과
- pairwise 평가 최고 성능
- criteria-based 평가 전반적 우수 성능
- 편향 완화와 안정성 측면의 장점 확인
- 최종 의미
- 평가에서도 단일 judge보다 협업형 심의 구조가 더 robust하고 실용적이라는 결론
This post is licensed under CC BY 4.0 by the author.