Conan-Embedding-v2: Training an LLM from Scratch for Text Embeddings
Conan-Embedding-v2: Training an LLM from Scratch for Text Embeddings
Written by. Shiyu Li, Yang Tang, Ruijie Liu, Shi-Zhe Chen, Xi Chen
EMNLP 2025 Oral
1. Conan-embedding-v2: 모델의 등장 배경과 필요성
배경
기존 LLM 기반 임베딩 모델은 뛰어난 성능을 보여왔지만, LLM과 임베딩 모델 간의 훈련 패러다임 격차 때문에 성능에 제약 존재
- LLM은 causal language modeling에 최적화되어 있고,
- 임베딩 모델은 문장 전체의 표현(bidirectional contextual embeddings)을 만들어내는 데 집중.
기존 접근의 한계
- LLM 학습 데이터(웹, 책, 토큰 단위 예측용)와
- 임베딩 학습 데이터(문장 단위 의미 표현, 검색·분류용)는 본질적으로 다름.
2. Conan-embedding-v2의 컨트리뷰션
- 데이터 격차 해소
- 다국어 쌍 및 교차 언어 검색 데이터셋(Cross-lingual Retrieval, CLR)을 추가.
- 다양한 언어 표현을 하나의 임베딩 공간에 통합할 수 있도록 설계.
- 훈련 격차 해소
- 소프트 마스킹 메커니즘(Soft Masking) 도입.
- Causal Attention(LLM용)에서 Bidirectional Attention(임베딩용)로 점진적 전환을 지원해, 모델이 갑작스러운 구조 변화로 최적화에서 멈추지 않도록 설계.
- 성능 최적화
- 동적 하드 네거티브 마이닝(DHNM) 기법을 적용.
- 훈련 중 난이도가 낮아진 부정 예제를 새로운 하드 네거티브로 교체하여 모델이 지속적으로 도전적인 학습 환경에서 훈련될 수 있도록 함.
3. Conan-embedding-v2
학습은 크게 4단계로 구분:
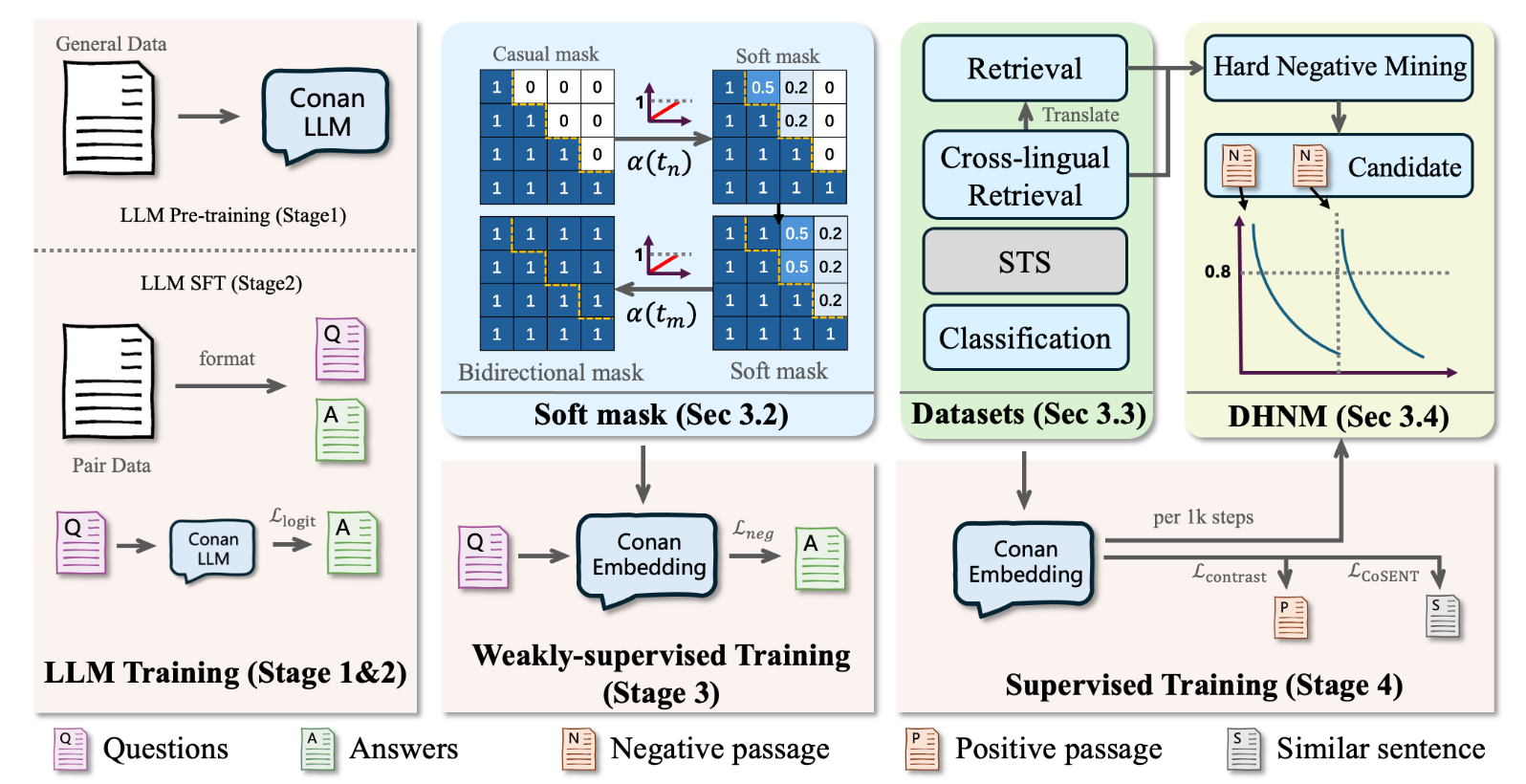
- LLM Pre-training
- 데이터: 약 3조 토큰 (뉴스, Q&A, 웹 데이터 등).
- 초기 세대 GPT-3: 300B → Conan-embedding-v2(3T)의 10분의 1 수준
- Meta LLaMA 2: 2T → Conan(3T)보다 적음
- 최신 LLaMA 3 / Gemini: 10T 이상 → Conan(3T)보다 많음
- 아키텍처: 8 레이어, 은닉 차원 3584, 입력 토큰 32K까지 지원.
- 파라미터: 1.4B.
- 토크나이저: 다국어 코퍼스 기반, 약 15만 어휘.
- 데이터: 약 3조 토큰 (뉴스, Q&A, 웹 데이터 등).
- Supervised Fine-Tuning
- 데이터: 약 6억 개의 쿼리-긍정 응답 쌍.
- 포맷: 지시 → 입력 → 출력.
- Embedding Weakly-supervised
- InfoNCE 로스 + In-batch Negative 샘플링.
- gte-Qwen2-7B-instruct로 데이터 품질 평가 후 특정 조건 시 사용 안함.
- 당시 SOTA급 임베딩 모델을 사용해 쌍의 품질 평가
- 목적: 초기 임베딩 표현 학습.
- Embedding Supervised
- 다운스트림 작업별 미세 조정.
- 테스크: 검색, 교차 언어 검색, 분류, STS.
- STS는 CoSENT 손실 사용.
- STS: (sentence1, sentence2, similarity score) 구조 → 회귀/순위 기반 손실 사용
CoSENT Loss
\[L_{cos} = \log\left(1 + \sum_{Order} \exp \frac{\langle x_k, x_l \rangle - \langle x_i, x_j \rangle}{\tau}\right)\]- Order = 실제 유사도가 sim(i,j) > sim(k,l)인 쌍
- 즉, STS에서는 쌍끼리의 상대적 순위를 학습
- 네거티브 샘플을 인위적으로 사용하지 않고, 데이터셋 내 문장쌍의 유사도 점수를 활용
3.1. Soft Mask 메커니즘
- 차이점
- LLM: causal mask, upper triangular attention weight 0.
- 임베딩: bidirectional mask, 모든 토큰 접근 가능.
- 문제점
- causal mask에서 bidirectional으로 바로 전환하면 학습 불안정.
- 해결책: 소프트 마스크
- 전이 함수 α(t)
t= 현재 학습 단계(step)τ= 총 학습 단계 수
즉, 학습이 진행됨에 따라 0 → 1까지 점진적으로 증가하는 값.
- 학습 초반(
t=0) →α(0)=0→ 완전 causal mask - 학습 중반(
t=τ/2) →α=0.5→ causal + 일부 bidirectional - 학습 후반(
t=τ) →α=1→ 완전 bidirectional mask
- 마스킹 수식
M_ij(t)= attention mask 행렬의 i행 j열 값i= 현재 단어 위치j= 참조하려는 단어 위치l= 전체 시퀀스 길이
적용
\[Attention(Q,K,V) = softmax((\frac{QK^T}{\sqrt{d}} \times M)) \times V\]
3.2. 교차 언어 검색 데이터셋 (CLR Dataset)
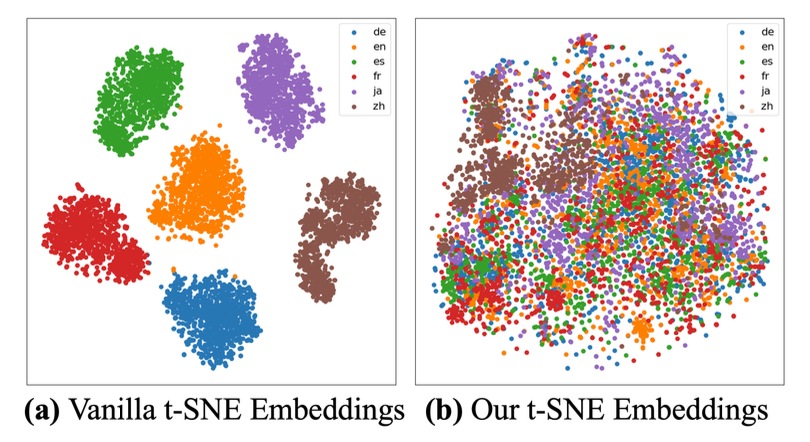
- 목적: 다국어 표현을 하나의 통합 공간에서 학습.
- 구축 방식
- 기존 검색 데이터셋(예: MSMARCO)의 쿼리를 26개 언어로 번역. → 쿼리는 번역하되 정답은 번역하지 않음.
- 약 1000만 쌍 데이터 확보.
- 번역은 Qwen2.5-7B를 활용.
- 효과 검증
- Amazon 리뷰 다국어 데이터(영/중/일/독/불/스페인어)에서 테스트.
- CLR 데이터셋 미포함 → 언어별로 분리된 클러스터.
- CLR 데이터셋 포함 → 언어 간 임베딩 분포가 잘 통합됨.
3.3. 동적 하드 네거티브 마이닝 (DHNM)
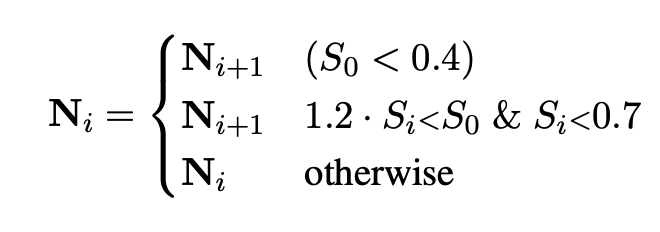
- 기존 한계
- 전처리 단계에서만 하드 네거티브 마이닝 → 고정된 부정 예제 사용.
- 훈련이 진행되면 예제가 더 이상 어렵지 않게 됨.
- DHNM 기법
- 훈련 중 각 배치에서 하드 네거티브 난이도를 실시간 측정.
- 코사인 점수 기반: $S = cos(f(q), f(p))$
- 일정 기준(예: 0.4 미만)을 만족하지 않으면 교체.
- 계산 오버헤드 없음
- 로스 계산 중 이미 점수 활용 가능.
- t 시점 이터레이션에서 로스 계산시 자연스럽게 코사인 계산 → 일정 기준을 만족하지 않으면 다음 이터레이션 때 네거티브 샘플 변경
- 결과: 항상 어려운 네거티브 예제를 유지.
4. Experiments
4.1 Training Data (학습 데이터)
Embedding Weakly-supervised Pretraining
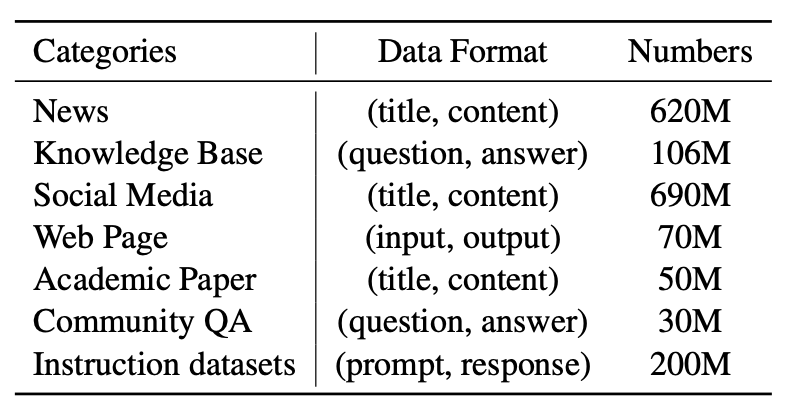
- 데이터 소스:
- CC-News (뉴스 데이터)
- mC4 (멀티언어 웹 크롤링 데이터)
- Wikipedia
- BAAI Chinese Corpora Internet (중국어 웹 데이터)
- 처리 방식: Data-Juicer로 저품질, 중복, 유해 콘텐츠 제거
- Data-Juicer : 알리바바에서 만든 LLM 관련 라이브러리
- 주로 title–content 쌍 사용
- 데이터 소스:
Embedding Supervised Training (임베딩 태스크용)

- 영어·중국어 기준, 5개 태스크 데이터셋 구축:
- Retrieval
- Reranking
- Classification
- Clustering
- Semantic Textual Similarity (STS)
- MTEB 평가셋과 겹치는 데이터는 제거
- 영어·중국어 기준, 5개 태스크 데이터셋 구축:
4.2 Model Architecture (모델 구조)
- 총 파라미터: 1.4B
- Transformer layers: 8
- Hidden dimension: 3584
- Attention heads: 32 (GQA 방식, KV-heads=8)
- FFN 차원: 8192
- Context length: 32,768
- Vocab size: 150K
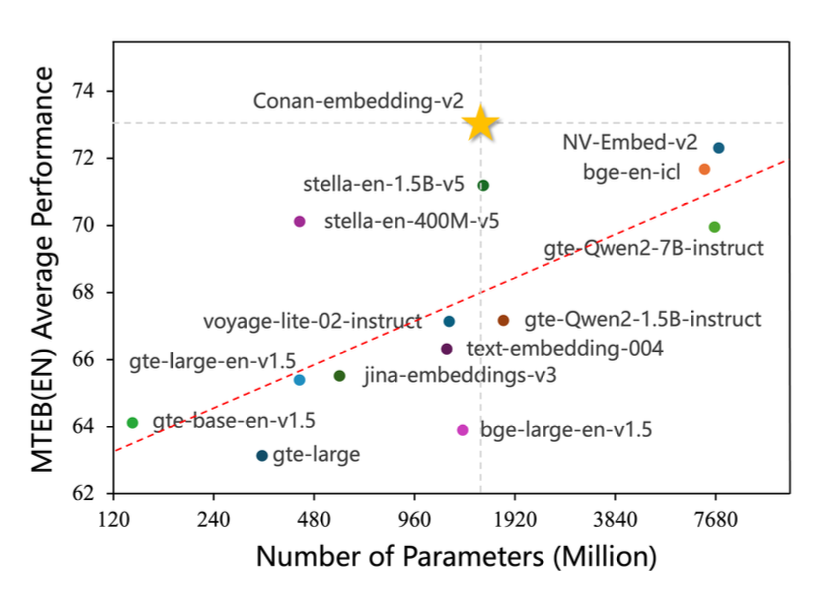
4.3 MTEB Results
MTEB English + Chinese 성능
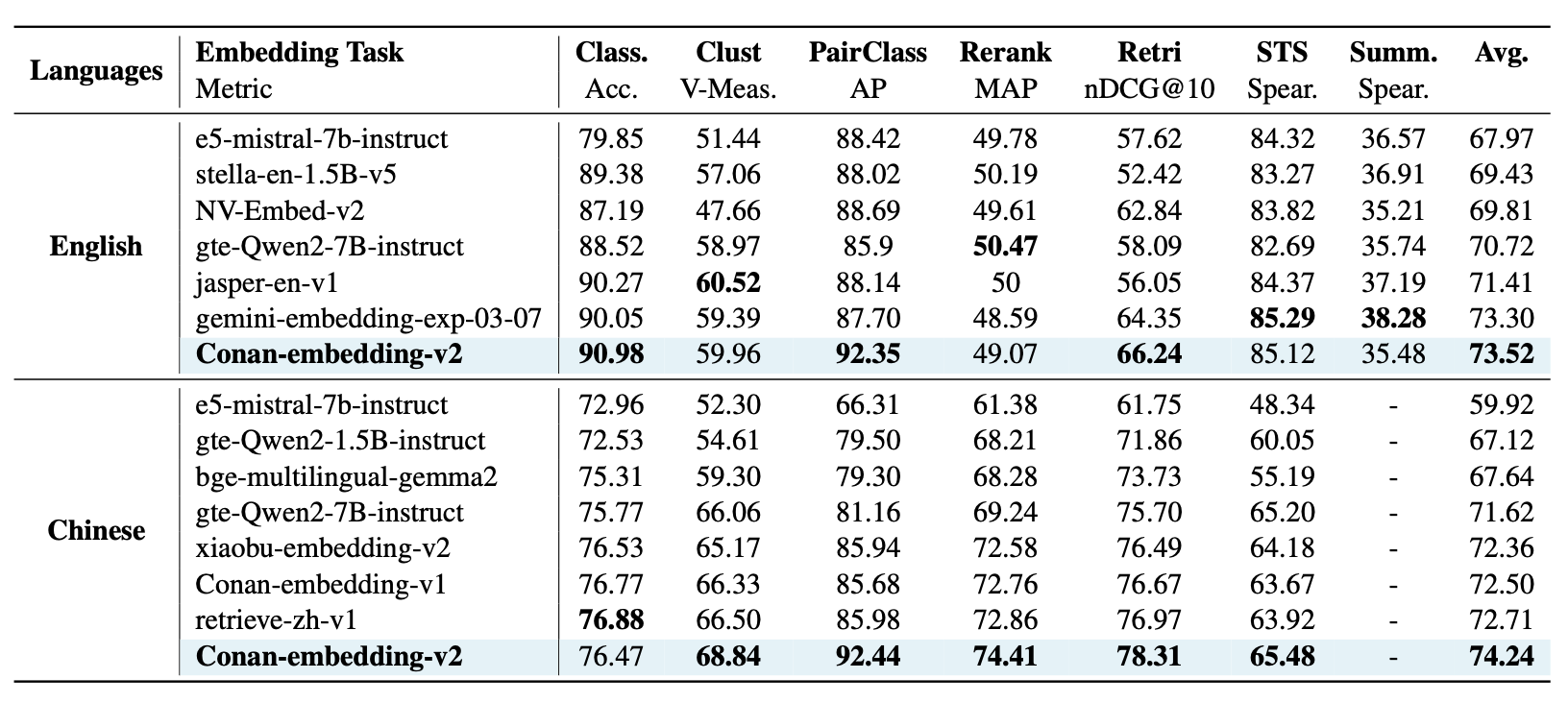
- Conan-embedding-v2:
- English 평균: 73.52 (SOTA)
- Chinese 평균: 74.24 (SOTA)
- Conan-embedding-v2:
Zero-shot 성능
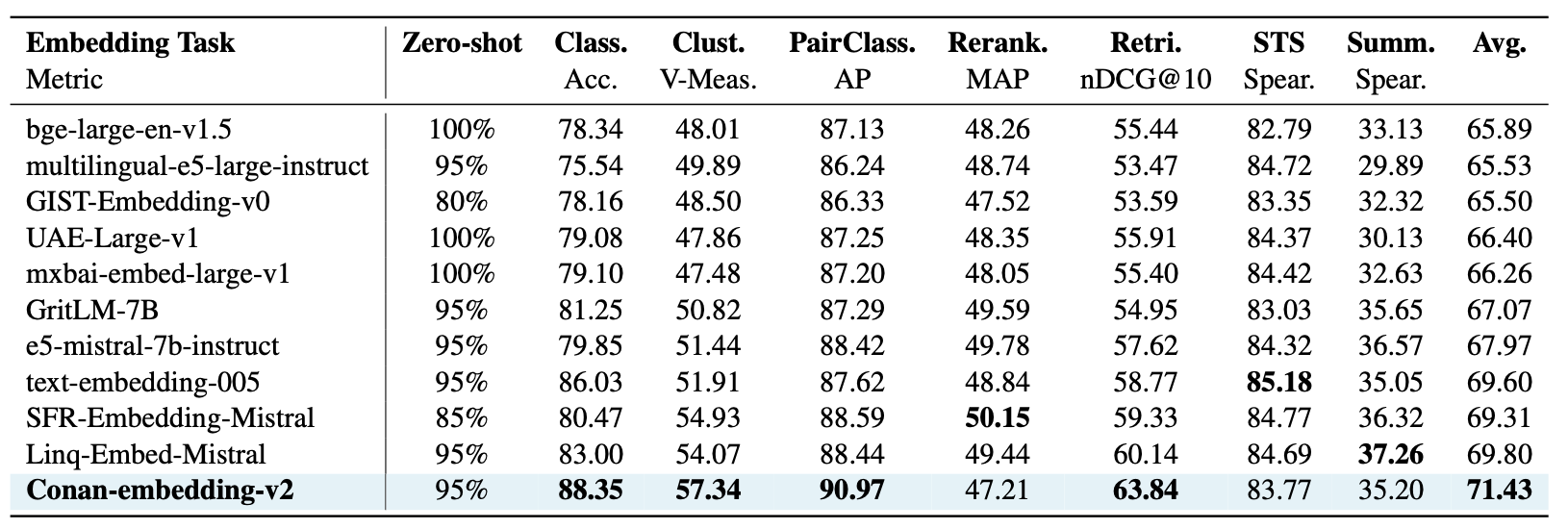
- Conan-embedding-v2 (1.4B) vs Linq-Embed-Mistral (7B) 비교
- Conan이 더 작은 모델임에도 불구하고 성능 우위
- 평균 점수: 71.43 → 기존보다 확실한 개선
4.4 MKQA Benchmark (Cross-lingual)
- MKQA = Multilingual Knowledge QA (26개 언어, 26만 쿼리–답변 쌍)
- 평가 지표: Recall@20, Recall@100, nDCG@10
성능
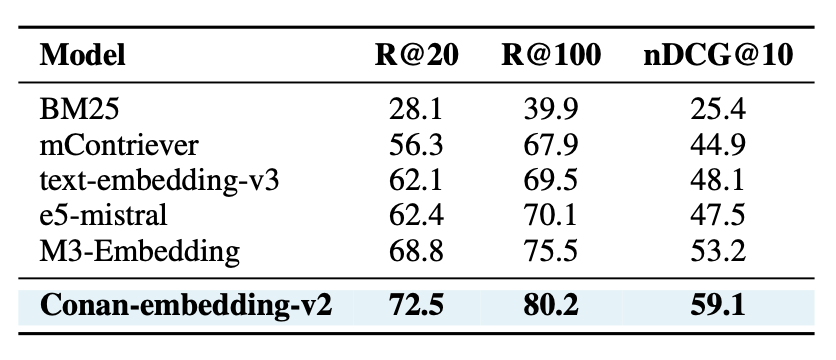
- 가장 강력한 기존 모델(M3-Embedding) 대비 +3.6% (R@20), +5.9% (nDCG@10) 개선
4.5 Ablation Study
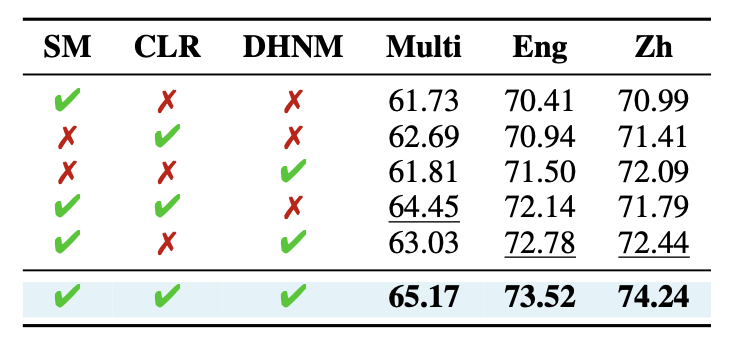
세 가지 핵심 기법의 조합 효과 분석:
- Cross-lingual Retrieval(CLR)만 사용 → multilingual 성능 ↑
- DHNM만 사용 → 단일언어 성능 ↑
- SM + CLR + DHNM → 모든 태스크 SOTA
4.6 Analysis
1) Practical Considerations
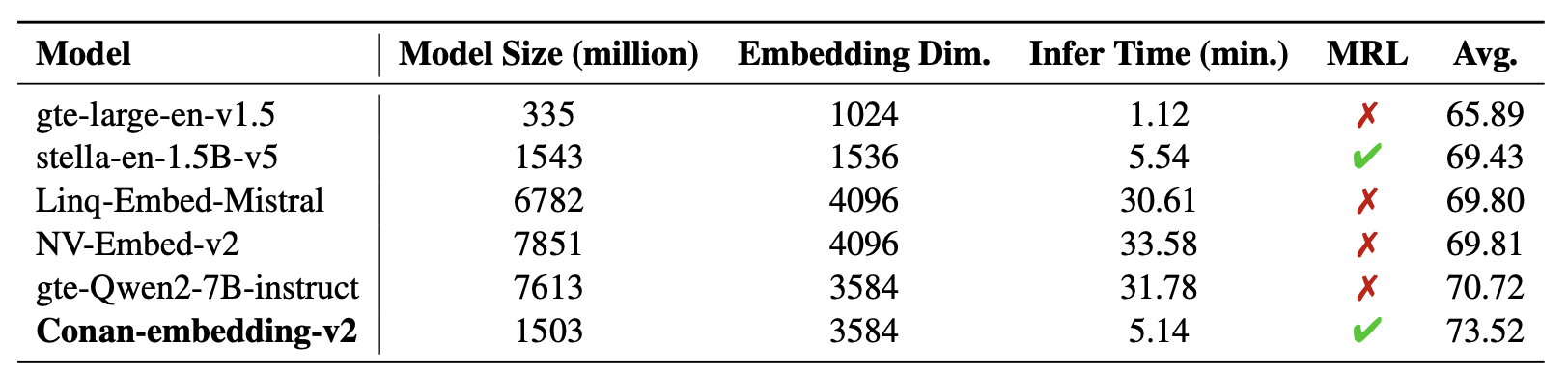
- 추론 시간: 5.14분 (빠름)
- MRL (Matryoshka Representation Learning) 지원 → 다차원 임베딩 가능
- Supervised Embedding 학습할 때 MRL로 학습
→ 성능과 효율성 모두 균형 잡힘
2) Training Gap 분석
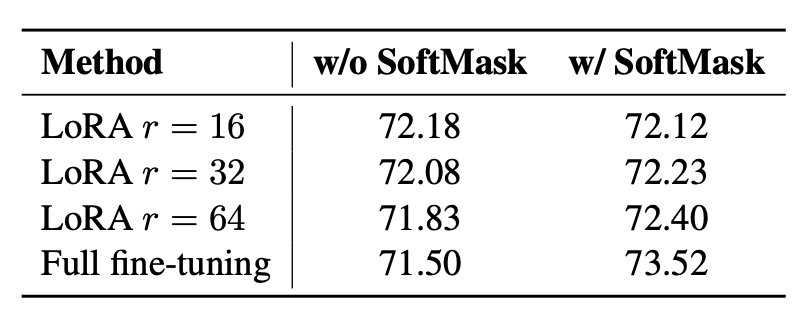
- Token-level (causal) vs Sentence-level (contrastive) 학습 간 차이
- Soft Mask 적용 시 full fine-tuning이 가장 좋은 성능 (73.52)
- LoRA도 Soft Mask 적용 시 성능 개선됨
→ Soft Mask가 두 패러다임 간 간극을 효과적으로 메워줌
5. Conclusion
- Conan-embedding-v2는 처음부터 학습한(1.4B 파라미터) LLM을 텍스트 임베딩 전용으로 파인튜닝한 모델임.
- 기존 LLM 기반 임베딩 모델의 두 가지 간극 문제를 해결:
- 데이터 간극 → LLM 학습 시 embedding 데이터(뉴스, QA, 다국어 pair) 반영
- 훈련 간극 → Soft Mask, Cross-lingual Retrieval, Dynamic Hard Negative Mining 적용
- 훈련 전략:
- LLM pretraining + SFT (instruction pair 활용)
- Soft Mask → embedding weakly supervised 파인튜닝 학습
- Cross-lingual Retrieval + DHNM → embedding superivsed 학습
- 결과:
- MTEB (English & Chinese) SOTA 달성
- MKQA (26개 언어)에서 강력한 cross-lingual 성능
- 모델 크기 작음에도 불구하고 효율성과 속도까지 확보
6. Limitations
- 언어별 데이터 편중
- Cross-lingual Retrieval dataset에서 영어–중국어 데이터 비중이 매우 높음
이로 인해 특정 언어(특히 Indo-European 계열)에서 성능이 좋고,
아랍어(65.2%), 한국어(67.5%) 같은 영어와 거리가 먼 언어에서는 성능 낮음
- → 언어 분포 균형 잡힌 데이터 필요
- Numerical Consistency
- 예: “3 fairy tales” vs “5 fairy tales” → 의미적으로 유사하지만 embedding 유사도가 낮음
- 임베딩 모델은 숫자를 그냥 토큰으로 처리 → 양적 관계를 이해 못 함
- → 향후 수치 데이터 다양화 필요
This post is licensed under CC BY 4.0 by the author.