FinLoRA : Benchmarking LoRA Methods for Fine-Tuning LLMs on Financial Datasets
FinLoRA : Benchmarking LoRA Methods for Fine-Tuning LLMs on Financial Datasets
Written by. Dannong Wang, Jaisal Patel
연구 배경 및 목적
문제 인식
- 일반 LLM은 금융 분야에서 전문지식 부족으로 성능이 떨어짐
- 전체 파인튜닝(full fine-tuning) 은 시간, 비용, 자원 부담이 커서 비효율적
- 기존 연구(ex. FinGPT)는 일부 LoRA 적용 사례만 있고, 다양한 LoRA 기법 비교 연구는 부재
FinLoRA의 목표
- 다양한 LoRA 방법을 정량적으로 벤치마크
- 금융 특화 과업에 최적화된 LoRA 전략 도출
- XBRL 기반 고난도 QA 문제 해결능력 평가 포함
- 오픈소스 생태계 기여 (데이터셋, 코드, 모델 공개)
주요 기여:
- 19개 금융 데이터셋 큐레이션: 일반 금융 작업, 금융 분석, 전문 XBRL 작업 등 19개의 금융 데이터셋을 큐레이션.
- 특히, 150개의 SEC 공시를 기반으로 4개의 새로운 XBRL 분석 데이터셋을 생성.
- 5가지 LoRA 방법론 및 5가지 기본 LLM 평가
- LoRA, QLoRA, DoRA, rsLoRA, Federated LoRA 등 5가지 LoRA 방법론과 Llama 3.1 8B/70B, DeepSeek V3, Gemini 2.0 FL, GPT-4o 5가지 기본 LLM을 평가
- 성능 향상 입증
- LoRA 방법론이 기본 모델 대비 평균 36%의 상당한 성능 향상을 달성했음을 발견.
- 광범위한 실험 결과 제공
- 정확도, F1 점수, BERTScore를 포함한 실험 결과와 미세 조정 및 추론 단계에서의 시간 및 GPU 메모리 측면의 계산 비용을 보고.
- 실용적 고려사항 제시
- 협업 학습 시 데이터 프라이버시 및 치명적 망각(catastrophic forgetting)과 같은 LoRA 배포의 실제적 고려사항을 다룸.
- 오픈 소스 공개
- 데이터셋, LoRA 어댑터, 코드 및 문서는 GitHub(https://github.com/Open-Finance-Lab/FinLoRA)에서 공개.
금융 작업에서 LLM 미세 조정의 필요성
- 일반 LLM의 한계
- GPT-4o, Llama 3.1, DeepSeek-V3와 같은 범용 LLM은 광범위한 NLP 역량을 보여주지만, 금융 작업에서는 성능이 부족.
- XBRL 데이터 처리의 중요성 및 데이터셋 부족: XBRL(eXtensible Business Reporting Language) 데이터는 기업의 재무 정보를 전자적으로 보고하고 분석하기 위한 국제 표준 언어지만, 관련 분석 작업을 위한 전용 데이터셋이 부족.
- 미세 조정의 필요성 강조: 효과적인 금융 LLM 개발을 위해 LoRA와 같은 미세 조정 방법론의 필요성 강조
- 사전 학습 데이터셋의 고품질 금융 데이터 부족
- The Pile과 같은 많은 사전 학습 데이터셋은 주로 일반 웹 크롤링(GitHub, arXiv 등)에서 가져오므로, 고품질의 전문 금융 데이터가 부족.
- 복잡한 금융 분석을 위한 타겟 미세 조정 필수
- 고품질의 전문 금융 데이터는 비공개이며 XBRL과 같은 복잡한 형식으로 존재.
- 따라서 복잡한 금융 분석에 필요한 이해를 LLM에 부여하기 위해서는 큐레이션된 도메인 특화 데이터셋에 대한 타겟 미세 조정이 필수.
- XBRL 분석 사례 연구: Llama 기본 모델은 XBRL 질문에서 오류를 보이지만, LoRA 미세 조정을 통해 개선된 결과를 보임.
- XBRL 태그 추출: 기본 모델은 “equity”, “carrying value”와 같은 표면적인 키워드 일치에 의존하여 잘못된 태그(US-GAAP:MajorityEquityInterest)를 지정하고, “under the equity method”와 같은 중요한 맥락을 무시.
- 반면, LoRA 미세 조정 모델: 올바른 태그(US-GAAP:EquityMethodInvestments)를 지정.
- XBRL 공식 계산: 기본 모델은 “Equity” 키워드에 일치하는 값을 참조하는 태그를 잘못 선택하고, decimals=”-6” 속성을 무시.
- LoRA 미세 조정 모델: 올바른 계산 결과를 제공.
- 사전 학습 데이터셋의 고품질 금융 데이터 부족
- 비용 및 시간 효율성:
- 전체 미세 조정의 높은 비용: 전체 미세 조정(Full fine-tuning)은 계산 비용이 많이 들어 대부분의 조직에 부담.
- BloombergGPT의 경우 270만 달러의 비용과 53일이 소요
- 전체 미세 조정의 높은 비용: 전체 미세 조정(Full fine-tuning)은 계산 비용이 많이 들어 대부분의 조직에 부담.
FinLoRA 벤치마크 구성

- 4가지 작업 유형:
- 일반 금융 작업:
- 감성 분석 (sentiment analysis, SA): Financial PhraseBank (FPB), Financial QA sentiment analysis (FiQASA), Twitter Financial News Sentiment (TFNS), News with GPT Instruction (NWGI) 데이터셋을 포함
- 각 데이터셋은 뉴스 또는 트윗의 금융 텍스트와 감성 레이블을 포함.
- 헤드라인 분석 (Headline Analysis): 금융 헤드라인을 “예” 또는 “아니오” 두 가지 클래스로 분류.
- 개체명 인식 (Named-entity recognition, NER): 문장당 하나의 개체를 “위치”, “사람”, “조직” 세 가지 클래스 중 하나로 분류.
- 감성 분석 (sentiment analysis, SA): Financial PhraseBank (FPB), Financial QA sentiment analysis (FiQASA), Twitter Financial News Sentiment (TFNS), News with GPT Instruction (NWGI) 데이터셋을 포함
- 금융 자격증 (Financial Certificate): CFA Level I, II, III 및 CPA Regulation 시험을 포함.
- 금융 보고 (Financial Reporting): XBRL Terminology, Financial Numeric Entity Recognition (FiNER), Financial Numeric Extreme Labeling (FNXL)을 포함.
- 재무제표 분석 (Financial Statement Analysis): Financial Math 및 FinanceBench를 포함.
- 일반 금융 작업:
- 새롭게 추가된 XBRL 분석 데이터셋:
- 구성: Dow Jones 30개 기업의 2019-2023년 연간 보고서에서 파생된 4가지 새로운 XBRL 분석 데이터셋을 도입.
- 데이터셋 유형: 각 예시는 질문, 관련 필터링된 XBRL 텍스트 세그먼트(소스 자료), 그리고 정답을 제공.
- XBRL 태그 추출 (XBRL tag extraction): 자연어 설명이 주어지면 원시 XBRL 텍스트 세그먼트에서 특정 XBRL 태그를 추출.
- XBRL 값 추출 (XBRL value extraction): 자연어 설명이 주어지면 원시 XBRL 텍스트 세그먼트에서 숫자 값을 추출.
- XBRL 공식 구성 (XBRL formula construction): LLM이 XBRL 데이터에서 여러 관련 사실(및 해당 XBRL 태그)을 식별하고 선택한 다음, 이러한 태그를 구성 요소로 사용하여 표준 금융 공식(예: 순이익률, 유동비율)을 구성.
- XBRL 공식 계산 (XBRL formula calculation): 이전 작업을 기반으로 LLM이 실제 숫자 값을 공식에 대입하고 최종 결과를 계산하도록 요구.
- 데이터셋 구축 파이프라인:
- 초기 분류: 금융 작업을 9가지 범주로 분류하고, 각 범주에 대한 훈련 세트를 생성하여 범주별 LoRA 어댑터를 개발.
- XBRL 데이터셋 생성: Dow Jones 30개 기업의 XBRL 형식 10-K 연간 보고서(2019-2023)를 사용하여 4가지 유형의 질문을 생성.
- 맥락 관련성 보장: XBRL 파일 세그먼트는 연도 및 보고 축과 같은 관련 요소를 기반으로 자동으로 필터링.
- 평가 지표:
- 일반 금융 작업, 금융 분석, XBRL 분석: LLM의 출력을 평가하기 위해 Exact Match (EM)를 사용하고 정확도와 가중 F1 점수 사용.
- XBRL Term 및 FinanceBench: BERTScore, F1을 사용
기본 모델 및 LoRA 방법론
- 기본 모델:
- LoRA 미세 조정 및 성능 벤치마킹: Llama 3.1 8B Instruct 및 Gemini 2.0 Flash Lite 두 모델 활용.
- 기본 모델로만 평가: Llama 3.1 70B Instruct, DeepSeek V3, GPT-4o 세 가지 추가 모델을 기본 모델로만 평가.
- LoRA 방법론
- (바닐라) LoRA (Low-Rank Adaptation): 사전 학습된 모델의 가중치를 보존하고 더 작은 학습 가능한 가중치 세트를 도입하는 매개변수 효율적인 미세 조정 방법
- QLoRA (Quantized LoRA): 4비트 양자화를 사용하여 메모리 사용량을 더욱 줄인다. 미세 조정 중에는 사전 학습된 모델의 모든 가중치가 4비트로 양자화
- DoRA (Weight-Decomposed Low-Rank Adaptation)
- W0를 열 방향 크기 벡터 m과 방향 행렬 V로 분해.
- 방향 행렬만 LoRA를 통해 업데이트를 받으며, 크기 벡터는 별도로 업데이트.
1) 분해(DoRA의 기본 아이디어)
- 예시: 가중치 $W_0$ (크기 2×3; 입력 차원 3개 = 열 3개):
- 열별 노름(크기) m과 단위 방향행렬 V를 구하기.
- 1열 $[2,0]^T$ : ∥ ⋅ ∥=2 → 방향 $[1,0]^T$
- 2열 $[0,4]^T$: ∥ ⋅ ∥=4 → 방향 $[0,1]^T$
- 3열 $[-3,4]^T$: ∥ ⋅ ∥=5 → 방향 $[-0.6,\ 0.8]^T$
따라서
\[m=[2,\ 4,\ 5],\quad V=\begin{bmatrix} 1 & 0 & -0.6\\ 0 & 1 & \ \ 0.8 \end{bmatrix},\quad W_0 = V\cdot \mathrm{Diag}(m).\]
2) DoRA에서 두 가지 업데이트
- (A) 크기만 바꾸기 (열별 스칼라 스케일)
- 예: 두 번째 입력 차원의 크기만 4→6으로 키움 m’=[2,6,5]
→ 방향은 유지, 해당 열의 “세기”만 커짐.
- (B) 방향만 LoRA로 바꾸기 (저랭크 ΔV=BA)
랭크 r=1 예시로
\[A=\begin{bmatrix}0.10 & -0.20 & 0.05\end{bmatrix},\quad B=\begin{bmatrix}0.5\\ 0\end{bmatrix} \Rightarrow \\ BA= \begin{bmatrix}0.05 & -0.10 & 0.025\\ 0 & 0 & 0\end{bmatrix}\]방향 행렬 갱신: $V^′=V+BA$
\[V'= \begin{bmatrix} 1.05 & -0.10 & -0.575\\ 0 & 1 & 0.8 \end{bmatrix}\]DoRA는 열별로 다시 정규화(단위 길이)
\[\widehat V' \approx \begin{bmatrix} 1.0000 & -0.0995 & -0.5836\\ 0.0000 & \ \,0.9950 & \ \,0.8120 \end{bmatrix}\]이제 원래 크기 m=[2,4,5]를 곱해 최종 가중치 $W’=\widehat V’\cdot\mathrm{Diag}(m)$:
→ 방향(열의 모양)이 바뀌고, 크기는 그대로라서 2·4·5만큼의 세기는 유지.
(C) 최종 가중치
\[W''=\widehat V'\cdot\mathrm{Diag}(m')\approx \begin{bmatrix} 2.0000 & -0.5970 & -2.918\\ 0.0000 & \ \,5.9700 & \ \,4.060 \end{bmatrix}\]
→ 방향(각 열의 모양)도 바뀌고, 크기(열별 세기)도 바뀐 결합 효과가 한 번에 반영.
(참고)
\[\begin{align}\Delta M_{\mathrm{FT}}^{t} &= \frac{1}{k} \sum_{n=1}^{k} \left| m_{\mathrm{FT}}^{n,t} - m_{0}^{n} \right| \\\Delta D_{\mathrm{FT}}^{t} &= \frac{1}{k} \sum_{n=1}^{k} \left( 1 - \cos\!\left( V_{\mathrm{FT}}^{n,t}, W_{0}^{n} \right) \right)\end{align}\]
- LoRA는 모든 중간 step에서 일관된 양의 기울기 추세를 보이며 방향과 크기의 변화 사이에 비례 관계가 있음을 나타냄.
- 반대로 FT는 상대적으로 음의 기울기를 가진 보다 다양한 학습 패턴을 보임.
- FT와 LoRA의 이러한 구분은 각각의 학습 능력을 반영.
- LoRA는 크기와 방향 업데이트를 비례적으로 늘리거나 줄이는 경향이 있지만 보다 섬세한 조정 능력이 부족.
- 특히 LoRA는 FT와 달리 큰 크기 변화와 함께 약간의 방향 변화를 실행하거나 그 반대로 실행하는 데 능숙하지 않음.
- rsLoRA (Rank-Stabilized LoRA)
- 바닐라 LoRA는 스케일링 팩터 α/r을 사용하는데, 이는 랭크 r이 증가함에 따라 기울기가 폭발하거나 감소.
- rsLoRA는 스케일링 팩터 α/√r을 사용하여 더 높은 랭크에서 기울기 스케일 안정성을 제공하며, XBRL 분석과 같은 긴 맥락 작업에 더 높은 랭크를 사용할 수 있도록 함.
- Federated Learning을 사용한 LoRA
- 금융 부문에서는 여러 기관이 자체 독점 데이터셋을 사용하여 협업하기를 원하지만, 규정 준수 및 개인 정보 보호 문제로 인해 데이터를 공유할 수 없음.
- 연합 학습은 로컬 데이터에서 모델을 미세 조정하고 LoRA 업데이트를 중앙 노드로 집계하여 이 문제를 해결.
- 미세 조정 설정:
- LoRA 어댑터: 각 LoRA 방법론에 대해 작업 범주별로 병합된 해당 훈련 세트를 기반으로 9개의 LoRA 어댑터를 미세 조정.
- 학습률 및 배치 크기: 학습률은 1e-4를 사용했으며, 배치 크기는 프롬프트 길이에 따라 2~8로 설정.
벤치마크 결과
관점 I: 금융 데이터셋에 대한 LoRA 방법론 성능
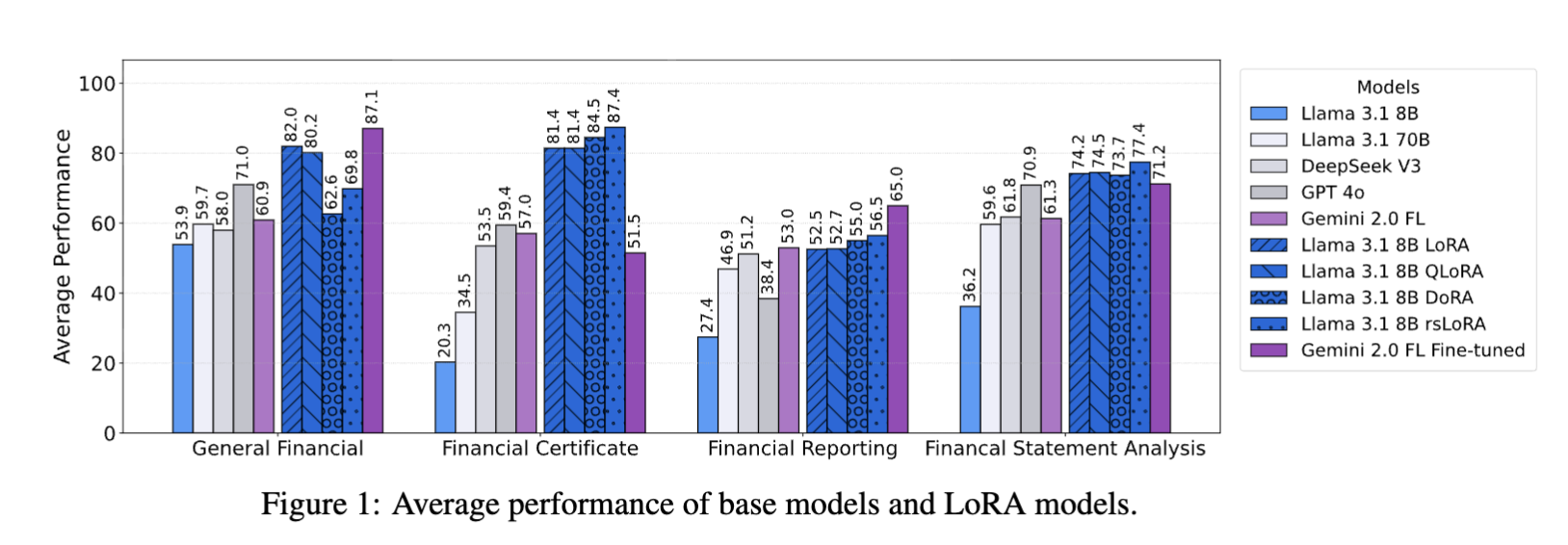
- LoRA 변형의 비교 성능:
- 전반적인 우수성: LoRA 미세 조정된 Llama 3.1 8B Instruct 모델은 NWGI 및 FNXL을 제외한 대부분의 데이터셋에서 일반적으로 우수한 성능.
- 최고 성능: 바닐라 LoRA(8비트, 랭크 8)는 Llama 3.1 8B 기본 모델의 37.05% 대비 37.69% 증가한 74.74의 가장 높은 전체 평균 점수를 달성.
- 범주별 성능:
- 바닐라 LoRA: 일반 금융 작업에서 다른 LoRA 변형보다 우수.
- rsLoRA: 금융 분석, 금융 보고 및 재무제표 분석에서 선두를 차지.
- rsLoRA의 고랭크 성능 우수성:
- rsLoRA는 더 큰 랭크에서 기울기 폭발 또는 소멸을 방지하기 위해 α/r 대신 α/√r로 스케일링하는 방법.
- 낮은 퍼플렉시티: rsLoRA 논문의 실험은 더 높은 랭크(예: r=64)에서 더 낮은 퍼플렉시티를 보임.
- 세부 정보 캡처: 더 높은 랭크 LoRA가 더 많은 세부 정보를 캡처한다는 사실과 함께, rsLoRA의 이점은 주로 높은 랭크에서 활용.
- DoRA의 두 가지 학습률 이점:
- 성능 저하: DoRA는 다른 세 가지 LoRA 방법론보다 성능이 좋지 않음.
- 동일한 학습률 사용의 문제: 크기 벡터와 방향 행렬 업데이트에 동일한 학습률을 사용했는데, 이는 두 가지 업데이트 유형 간의 기울기 스케일이 다르기 때문에 일부 경우에 최적의 성능을 내지 못할 수 있을듯?
- 잠재적 개선: 크기 벡터가 저랭크 업데이트의 학습률보다 높은 자체 학습률을 가질 경우 DoRA는 더 높은 성능을 달성할 수 있을 것.
관점 II: 금융 작업 LoRA 적합성
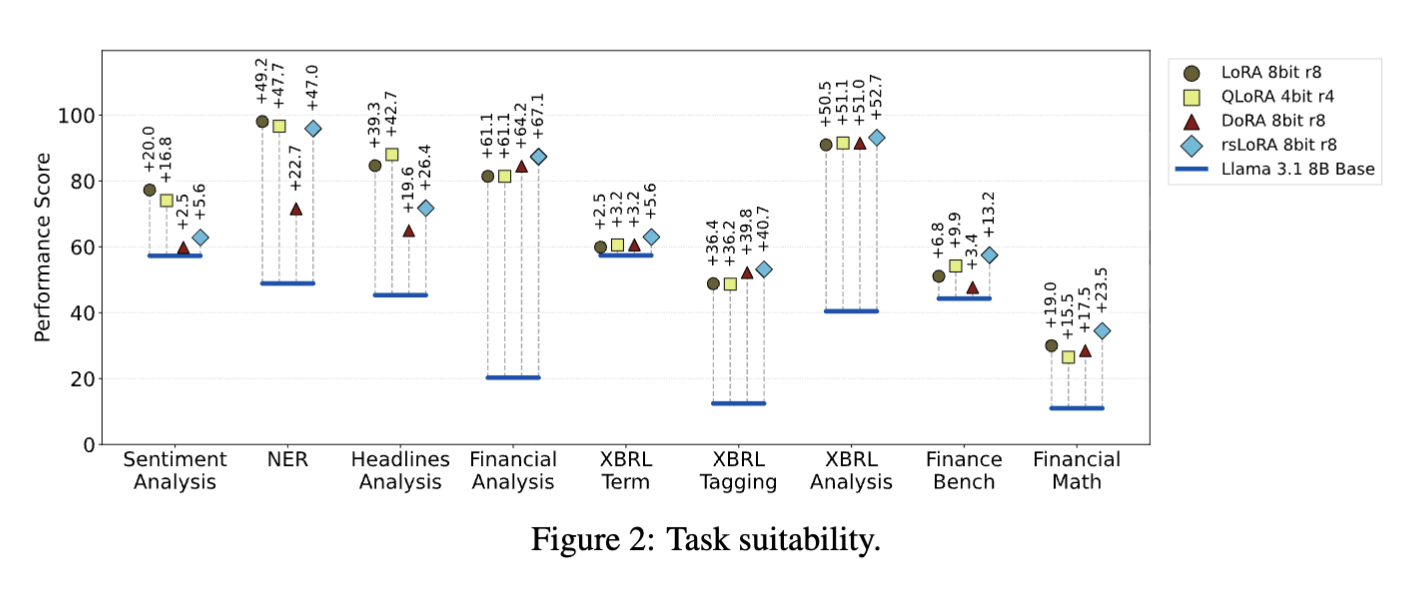
- XBRL 분석의 높은 개선: XBRL 분석 작업은 LoRA로 인한 성능 개선이 상당한 반면, FinanceBench는 최소한의 개선을 보임.
- XBRL의 역할: XBRL에 내재된 표준화된 의미론 및 분류법은 LLM에 더 구조화되고 일관된 학습 환경을 제공하여, OCR 처리된 PDF 데이터에 의존하고 풍부하고 표준화된 메타데이터가 부족한 FinanceBench에 비해 더 효과적인 적응을 촉진.
- 이러한 결과는 재무 보고서 분석을 위한 효과적인 LLM 통합을 가능하게 하는 XBRL의 중요한 역할을 강조.
관점 III: LoRA 방법론의 리소스 사용량 및 성능 트레이드오프
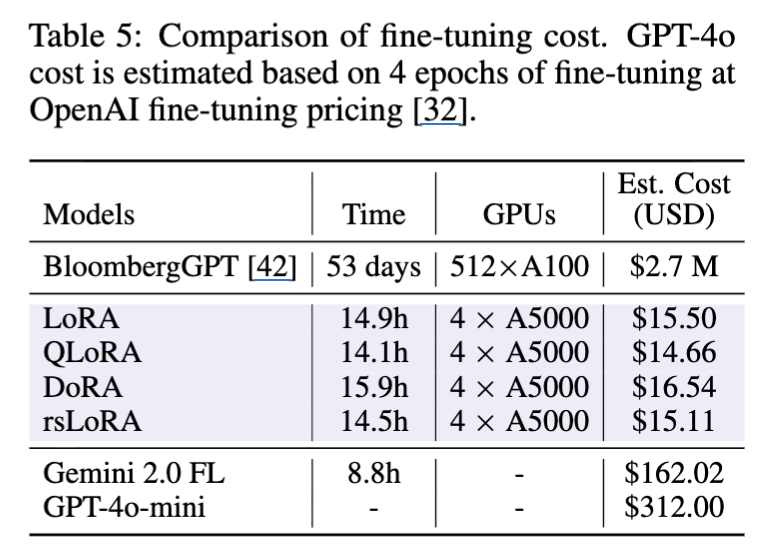
- 미세 조정 비용:
- GPU 사용: 4개의 NVIDIA A5000 GPU를 사용하여 실험 수행.
- 시간 및 비용: 미세 조정에 소요된 시간은 QLoRA의 14.1시간에서 DoRA의 15.9시간까지 다양했으며, 이는 약 56.4~63.6 GPU 시간에 해당.
- 비용 효율성: GPU 시간당 0.26달러로 추정했을 때, 총 비용은 약 14.66달러에서 16.54달러에 이른다. 이는 Google 또는 OpenAI와 같은 제공업체의 미세 조정 서비스보다 훨씬 비용 효율적.
- 추론 시간:
- Gemini API의 낮은 지연 시간: Gemini API는 일반적으로 로컬 Llama 3.1 8B Instruct 모델보다 낮은 추론 지연 시간을 보이며, 프롬프트 길이 증가에 덜 민감.
- 로컬 Llama 모델의 잠재적 개선: 로컬에 배포된 Llama 모델의 추론 속도는 더 큰 배치 크기를 사용하면 크게 향상될 수 있음.
관점 IV: 실제 금융 시나리오에서 LoRA 적용의 실용성
- Federated LoRA:
- 데이터 프라이버시: 금융 데이터의 민감한 특성상 협업 훈련을 위해 연합 학습과 같은 개인 정보 보호 기술이 필요.
- 실험 설정: 4개 노드 환경을 시뮬레이션하고 FedAvg 알고리즘을 사용하여 감성 분석 데이터셋을 노드에 분할.
- 성능: 연합 LoRA는 중앙 집중식 LoRA의 성능 수준에는 미치지 못했지만, 기본 Llama 모델에 비해 눈에 띄는 개선을 보여줌.
Catastrophic Forgetting:
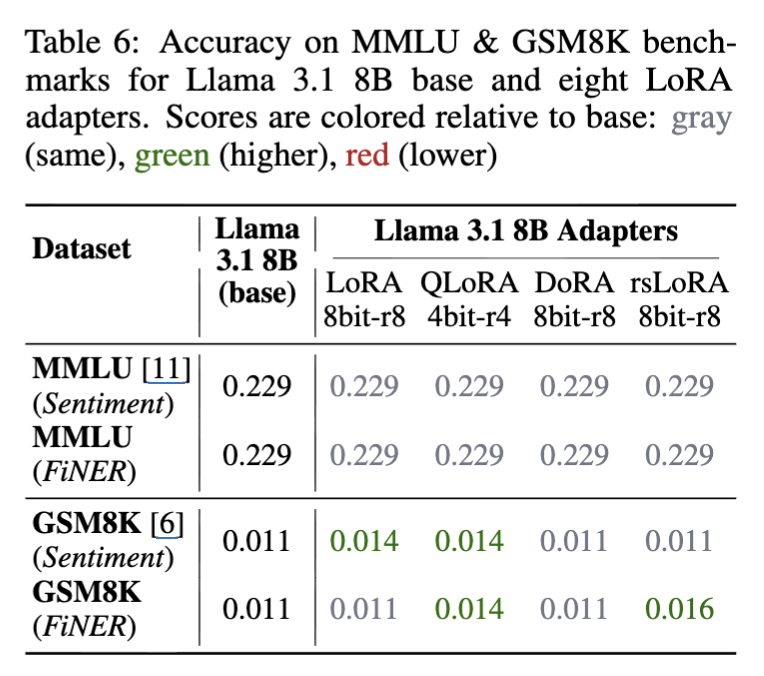
- 도메인 특화 작업에 대한 미세 조정이 사전 학습 지식을 잊게 하는지 조사하기 위해, 8개의 LoRA 어댑터(감성 및 FiNER 작업, 4가지 LoRA 변형 모두 포함)와 Llama 3.1 8B Instruct 기본 모델을 MMLU 및 GSM8K 두 가지 도메인 외 벤치마크에서 평가.
- 결과: MMLU 정확도는 모든 어댑터와 기본 모델에서 동일했으며, GSM8K 점수는 같거나 더 높았음.
- 결론: 테스트된 랭크(4 및 8)에서 LoRA는 Catastrophic Forgetting을 보이지 않음.
- 오히려 GSM8K 성능의 약간의 개선은 교차 도메인 지식 전달을 시사.
- 즉, 금융 데이터에 대한 미세 조정이 모델의 수치 추론 능력을 향상시킬 수 있음.
결론 및 향후 계획
- LoRA 기반 금융 LLM 파인튜닝이 비용효율성과 성능 측면에서 매우 효과적
- FinLoRA는 학계와 산업에 표준 벤치마크 역할 수행 가능
- 향후 더 많은 LoRA 변종과 평가 지표 추가 예정
This post is licensed under CC BY 4.0 by the author.