Improving Document Retrieval Coherence for Semantically Equivalent Queries
Improving Document Retrieval Coherence for Semantically Equivalent Queries
Written By. Stefano Campese, Alessandro Moschitti, Ivano Lauriola
1. 문제 정의
- 핵심 문제의식
- Dense Retrieval(DR) 모델은 일반적으로 질의와 문서를 각각 임베딩한 뒤, 두 벡터의 유사도로 관련 문서를 검색하는 구조임
- 기존 DR 학습은 대체로 “주어진 질의에 대해 정답 문서를 상위에 올리는 것”에 최적화되어 있으나, 의미는 같고 표현만 다른 질의들에 대해 같은 문서를 안정적으로 반환하는 능력, 즉 검색 일관성(coherence) 측면은 충분히 다뤄지지 않았다는 문제의식임
- 논문이 지적하는 실제 문제
- 같은 의미를 가진 질의라도 표현이 조금만 바뀌면 검색 결과 상위 문서 집합이 크게 달라질 수 있음
- 예를 들어, “federal prevailing wage가 무엇인가”와 “Can you explain the concept of federal prevailing wage?”는 의미상 거의 동일하지만, DR 모델은 서로 다른 문서를 상위에 반환할 수 있음
- 이런 현상은 모델이 의미 자체보다 표면 어휘 변화에 민감하다는 점을 보여주는 증거임
- 왜 중요한 문제인지
- 사용자는 검색 결과가 만족스럽지 않을 때 질의를 여러 번 바꿔 재검색하는 경향이 있음
- 논문은 과거 검색엔진 연구를 인용하며, 상당수 검색 트래픽이 실제로는 질의 재작성에서 발생할 수 있음을 상기시킴
- 따라서 질의 표현 변화에 취약한 검색기는 사용자 경험 저하, 검색 파이프라인 재실행 비용 증가, 시스템 효율 저하로 이어질 수 있음
- 정확도와의 관계
- 논문은 “낮은 sensitivity = 높은 coherence”로 보고 있음
- 의미적으로 같은 질문을 서로 다르게 처리한다는 것은 일반화(generalization)가 부족하다는 의미이므로, coherence 개선은 단순한 안정성 문제를 넘어 정확도 향상과도 연결될 수 있음을 주장함
- 즉, coherence는 부가적으로 필요한 것이 아니라 모델 품질의 중요한 측면이라는 것임
- 기존 접근의 한계
- 기존 연구는 주로 다음 두 방향이었음
- 질의 증강(query augmentation): 동의적 질의들을 더 만들어 학습 데이터에 추가하는 방식
- 질의 재작성(query rewriting): LLM 등으로 질의를 더 검색 친화적인 형태로 바꾼 뒤 검색하는 방식
- 그러나 논문은 단순 증강만으로는 일관된 성능 개선이 어렵고, query rewriting은 외부 생성 모델이 필요해 지연과 비용이 증가한다는 한계를 지적함
- 이에 따라 저자들은 검색 모델 자체의 loss에 coherence를 직접 주입하는 방향을 제안함
- 기존 연구는 주로 다음 두 방향이었음
2. 해결방법
2-1. 기본 아이디어
- 제안 목표
- 의미적으로 동등한 질의들에 대해 DR 모델이 가능한 한 같은 문서 집합, 더 나아가 비슷한 순위 리스트를 반환하도록 학습시키는 방법 제안임
- 핵심은 단순히 “관련 문서를 잘 찾는가”뿐 아니라, “질의 표현이 달라도 같은 검색 결정을 내리는가”까지 학습 목표에 포함시키는 것임
- 기존 MNR loss의 확장
- 기존 DR 학습에서 많이 쓰이는 Multiple Negative Ranking(MNR) loss를 기반으로 하되,
- 여기에 의미적으로 같은 질의들 간의
- 임베딩 정렬
- 문서와의 상대 유사도 구조 정렬
- 을 추가로 강제하는 Coherence Ranking (CR) loss를 설계한 것임
2-2. 질의 동치성 정의
- 논문은 먼저 질의 동치 집합(cluster) 개념을 정의함
- 어떤 질의 집합 C $\subseteq$ Q에 속한 두 질의 $q_i$, $q_j$가 의미적으로 동등하다는 것은 다음을 만족하는 경우임
- 여기서 “동등”의 의미는
- 동일한 정보를 가지며
- 그 답이 상호 교환 가능해야 한다는 것임
- 이를 라벨링 함수 $l(q, a)$로 더 엄밀하게 쓰면 다음과 같음
- 의미는 다음과 같음
- 어떤 답변 a가 $q_i$에 대해 정답이면, $q_j$에 대해서도 정답이어야 함
- 반대로 $q_j$에 대해 정답이면 $q_i$에 대해서도 정답이어야 함
- 즉, 질문의 문장 표면은 달라도 요구하는 정답 공간은 동일해야 한다는 정의임
2-3. 검색 일관성(coherence) 정의
- DR 모델을 $\delta$라고 하고, 문서 컬렉션을 D라고 할 때
- 질의 q에 대해 topk 검색 결과를 다음과 같이 정의함
subject to
\[\delta(q, d_{qi}) \ge \delta(q, d_{q(i+1)}) \quad \forall d_{qi} \in D\]- 해석하면 다음과 같음
- $\delta(q,d)$는 질의와 문서 간 유사도 점수임
- 그 점수 순으로 내림차순 정렬한 상위 k개 문서 리스트가 $\psi_{\delta,D}(q,k)$ 임
- 이후 같은 클러스터의 질의 $q_i, q_j$ 에 대해 두 검색 결과 리스트의 유사도를 비교함
- 즉 coherence는 개념적으로 다음과 같음
- 여기서 $\sigma$는 두 랭킹 리스트 유사도를 계산하는 함수이며, 논문은 주로
- RBO (Rank-Biased Overlap)
- Spearman correlation
- 을 사용함
- 값이 높을수록 같은 의미의 질의들에 대해 더 비슷한 검색 결과를 낸다는 뜻이며, 곧 낮은 민감도(sensitivity)를 의미함
2-4. Coherence Ranking Loss의 수식
논문의 핵심 수식은 다음과 같음
\[L_{CR}(q, d^+, D^{-}, C) = \lambda_1 \frac{1}{|C|}\sum_{q_i \in C} | \mathbf{q} - \mathbf{q_i} |_2^2+\lambda_2 \sum_{q_i \in C}\sum_{d \in D^-}\big(m(q,d^+,d)-m(q_i,d^+,d)\big)^2+MNR(q,d^+,D^-)]\]여기서
\[m(q,d^+,d)=s(q,d^+)-s(q,d)\]이며, s는 코사인 유사도임. 굵은 기호는 임베딩 벡터를 의미함.
2-5. 수식 구성요소 상세 설명
(1) MNR 항
- 마지막의 $MNR(q,d^+,D^-)$는 기존 DR에서 널리 사용하는 기본 학습임
- 하나의 질의 (q) 에 대해 정답 문서 $d^+$와는 유사도를 높이고 음성 문서 집합 $D^-$와는 유사도를 낮추는 것
(2) QEA: Query Embedding Alignment 항
- 첫 번째 항은
- 의미는 다음과 같음
- 같은 의미를 가진 질의 q와 $q_i$의 임베딩 벡터가 서로 가까워지도록 강제하는 항임
- 거리 측정에는 MSE를 사용함
- $\lambda_1$의 역할
- 이 항의 중요도를 조절하는 가중치임
- 너무 크면 모든 동치 질의를 과도하게 한 점으로 몰아 표현 다양성을 잃을 수 있고
- 너무 작으면 coherence 개선 효과가 약해질 수 있음
(3) SMC: Similarity Margin Consistency 항
- 두 번째 항은
- 먼저 내부 함수
의 의미부터 보면,
- 정답 문서 $d^+$와 질의 q의 유사도, 음성 문서 d와 질의 q의 유사도의 차이, 즉 positive-negative margin 임
- 따라서 SMC 항은 원래 질의 (q) 에서의 margin, 동치 질의 $q_i$에서의 margin이 서로 비슷해지도록 강제하는 항임
- 왜 중요한지
- 단순히 질의 임베딩끼리만 가깝게 하는 것만으로는 부족할 수 있음
- 실제 검색은 문서와의 상대적 점수 차이로 결정되므로,
- 동치 질의라면 정답 문서와 오답 문서 간 점수 차 구조 자체도 유지되어야 함
- SMC는 바로 이 부분을 정렬하는 장치임
2-6. 왜 QEA와 SMC를 둘 다 쓰는지
- QEA만 사용한 경우
- 질의 임베딩끼리만 가깝게 만들 수 있음
- 하지만 문서들과의 상대적 점수 구조까지 일치한다고 보장할 수는 없음
- SMC만 사용한 경우
- 문서 점수 차이를 맞출 수는 있지만, 질의 표현 자체가 벡터 공간에서 안정적으로 정렬된다는 보장은 약함
- 둘을 함께 사용할 때
- 질의 공간 정렬 + 질의-문서 관계 정렬이 동시에 일어남
- 그 결과 coherence와 relevance가 함께 좋아질 수 있다는 것이 논문의 핵심 주장임
- 실제 ablation에서도 개별 항보다 결합된 전체 LCR이 더 좋은 성능을 보였음
2-7. 학습 데이터 구성 방식
- 각 원본 질의에 대해 Phi-3를 사용해 최대 10개의 의미 동등 질의를 생성함
- 생성 목표는 원 질문의 intent와 정답은 유지하면서, 스타일과 어휘는 다양화하는 것임
- 예를 들어 NQ 스타일, TriviaQA 스타일, WebQA 스타일 등 다양한 질문체를 모사함
- 이렇게 생성된 질의들은
- 단순 증강(Query Augmentation)
- query-query similarity 학습(LQQ)
- 제안 loss(LCR)
- 등에 활용됨
- 흥미로운 점
- 저자들은 100개의 랜덤 샘플에 대해 생성된 10개 변형 질의를 수동 검토했고, 정확성과 동치성 정확도 100% 라고 보고함
- 즉, 생성 질의 품질에 대한 최소한의 검증을 수행한 셈임
3. 실험
3-1. 데이터셋과 설정
- MS-MARCO
- 8.8M passage 문서
- 학습 질의 약 495K
- query-document positive pair 약 523K
- 쿼리당 최대 5개의 hard negative 사용
- 공식 test label이 공개되지 않아 dev set을 dev/test로 나눠 사용함
- Natural Questions (NQ)
- 원래 132,803개의 질의
- hard negative 추출이 가능한 약 120K 질의 사용
- 쿼리당 10개의 hard negative 생성
- dev 3,000, test는 원래 split 사용
- 문서 수는 2,681,468 passage 수준임
- 질의 생성
- MS-MARCO와 NQ 각각에 대해 원본 질의마다 10개의 lexical variation 생성
- 생성 모델은 Phi-3 mini instruct 사용함
- 백본 모델
- 주력 실험은 MPNet 기반
- 일반화 실험은 MiniLM-v2-12L, ModernBERT-base까지 확장함
- 학습 세부 설정
- learning rate, batch size, $\lambda_1$, $\lambda_2$등을 validation으로 탐색
- optimizer는 AdamW
- 최대 15 epoch, early stopping 적용
- 8개의 NVIDIA H100 GPU 사용함
3-2. 비교 대상
논문은 다음 설정들을 비교함.
- Public checkpoint
- sentence-transformers 계열의 공개 사전학습 체크포인트 그대로 사용한 baseline임
- FT
- 대상 데이터셋에 대해 일반적인 MNR loss로 파인튜닝한 baseline임
- + Query Augmentation
- 생성된 질의를 단순히 학습 데이터에 추가한 방식임
- + LQQ
- query-document 학습과 별도로 query-query 유사성 학습을 멀티태스크로 수행한 방식임
- + LCR
- 제안하는 coherence ranking loss를 적용한 방식임
- Full
- LCR + query augmentation을 함께 적용한 방식임
- BM25 / SPLADE-v3
- lexical/sparse retrieval baseline으로 비교한 방식임
3-3. 평가 지표
- 정확도 관련
- P@1
- NDCG@10
- MRR@10
- MAP@100
- coherence 관련
- RBO@5
- Spearman@5
- coherence 평가는 원본 test query와 생성된 10개 변형 질의를 각각 모델에 넣고, top-5 랭킹 간 유사도를 측정하는 방식임
- 즉, 라벨과 무관하게 “동일 의미 질의 간 랭킹이 얼마나 비슷한가”를 직접 평가한 것임
3-4. 메인 결과
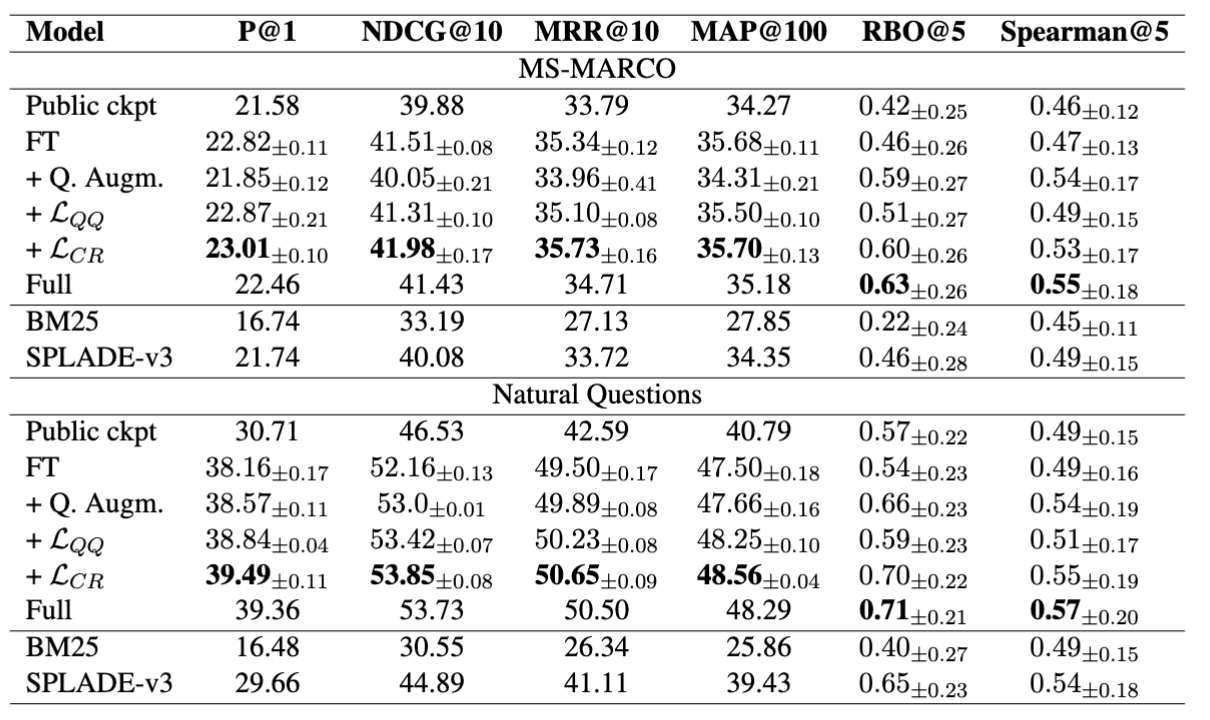
MS-MARCO,Natural Questions 결과
- relevance 성능도 소폭 상승함 하지만 더 눈에 띄는 점은 coherence가 크게 상승했다는 점임
- NQ에서는 정확도와 coherence가 모두 더 크게 개선됨 → 의미 동등 질의 간 top-ranked 문서 겹침이 상당히 증가했음을 의미함
Query Augmentation과의 비교 해석
- 단순 Query Augmentation은 coherence 개선에는 강한 baseline이었음
- 그러나 relevance 측면에서는 일관적이지 않았음
- MS-MARCO에서는 NDCG@10이 오히려 하락, NQ에서는 상승
- 논문은 이를 데이터셋 규모와 분포 차이로 해석함
- 큰 데이터셋에서는 생성 질의가 테스트 분포와의 간극을 넓혀 악영향을 줄 수도 있고
- 작은 데이터셋에서는 추가 데이터 자체가 도움이 될 수 있다는 해석임
- 반면 LCR은
- 단순히 데이터를 늘리는 방식이 아니라
- 동치 질의들 간 구조적 일관성을 학습함으로써
- 두 데이터셋 모두에서 더 안정적인 향상을 보였다는 점이 강점임
3-5. Ablation Study
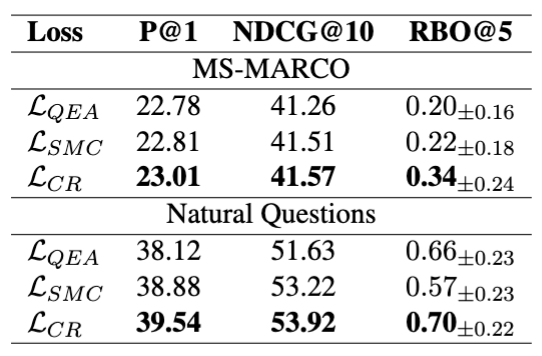
- 논문은 loss 구성요소를 나눠서 실험함
- LQEA: Query Embedding Alignment만 사용
- LSMC: Similarity Margin Consistency만 사용
- LCR: 둘 다 함께 사용
결과 요약
- 개별 요소만 써서는 전체 효과를 충분히 재현하지 못함
- 질의 임베딩 정렬과 마진 정렬이 함께 들어갈 때 비로소 강한 coherence 개선이 발생한다는 근거임
- 특히 논문은 “우리 loss는 MNR을 대체하는 것이 아니라 확장하는 것”이라고 강조함
3-6. 모델 일반화 실험

- MPNet 외에 MiniLM, ModernBERT에 대해서도 실험함
- 제안 방식이 특정 백본에만 맞춘 트릭이 아니라, 여러 encoder 아키텍처에서 작동할 가능성을 보여주는 결과임
3-7. Retrieve-and-Rerank 관점 실험
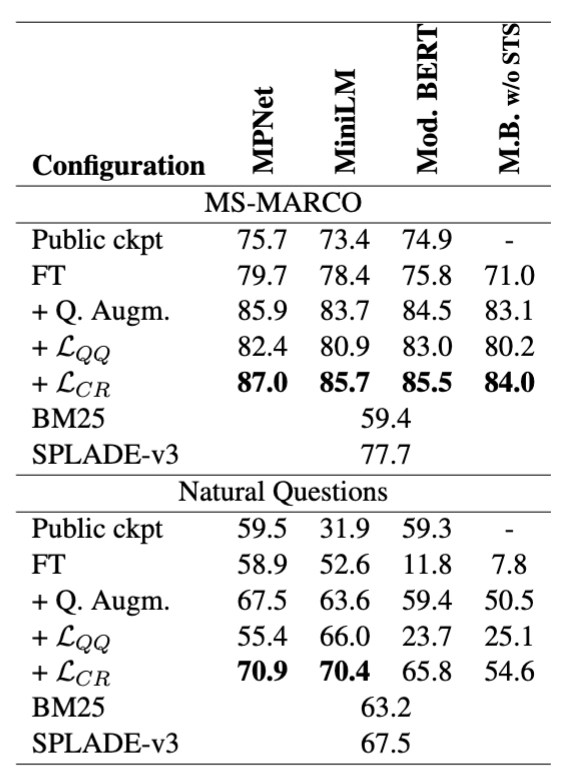
- top-50 retrieval 결과를 cross-encoder re-ranker가 다시 재정렬하는 시나리오를 실험함
- 이때 핵심 지표로 re-ranking opportunity를 정의함
- 개념
- 원본 질의 q에 대해 reranker가 최종적으로 고른 문서 $d^*$가 있을 때
- 동치 질의 $q_i$들에 대해서도 retrieval top-50 안에 그 $d^*$가 계속 포함되는가를 측정하는 지표임
- 수식 개념은 다음과 같음
- 해석
- 질의 표현이 달라져도 reranker가 “같은 최적 문서”를 다시 고를 기회가 유지되는지 보는 것임
- 결과
- retrieval coherence가 높아지면 reranker도 안정적으로 같은 좋은 후보를 다시 선택할 수 있게 됨을 시사함
3-8. complex retrieval 실험
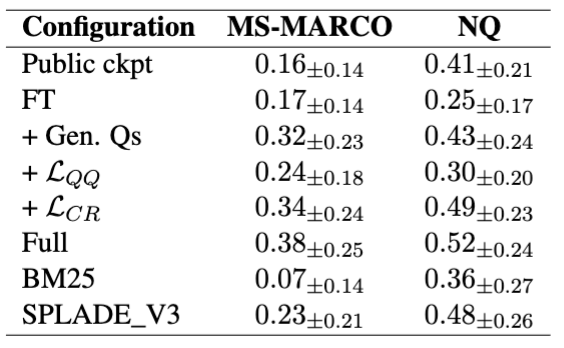
- 논문은 top-1 문서와 top-50 문서 간 retrieval score 차가 0.1 미만인 질의들을 별도 분석함
- 이런 질의들은 여러 문서가 비슷한 점수를 받는 순위 결정이 매우 어려운 케이스임
- 저자들은 이런 경우 coherence가 특히 중요하다고 가정함
- 결과
- 어려운 질의일수록 작은 점수 차이로 랭킹이 크게 뒤바뀌므로, 질의 표현 변화에 훨씬 취약해짐
- LCR이 이런 상황에서 특히 큰 효과를 보였다는 점은 실용적으로 매우 중요함
- 논문은 MS-MARCO에서 FT 대비 LCR/Full의 coherence 향상이 매우 크다고 강조함
3-9. Query Reformulation과의 비교
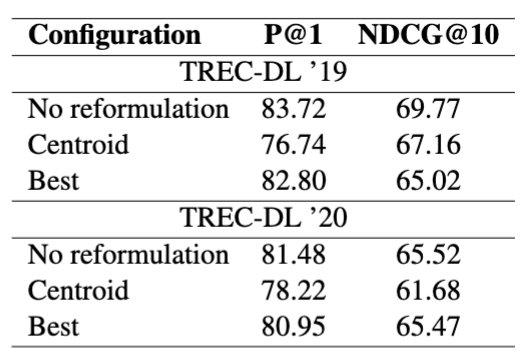
- 저자들은 query rewriting 자체는 연구 범위 밖이라고 선을 긋지만, 보완적으로 train-free 방식 몇 가지를 실험함
- 결과
- 단순 rewrite 결합만으로는 좋은 retrieval coherence/accuracy를 만들기 어렵다는 의미
- 반대로 모델 내부의 학습 목적을 바꾸는 접근의 타당성을 뒷받침하는 결과로 볼 수 있음
4. 결론
- Dense Retrieval 모델은 의미적으로 같은 질의라도 표현 차이에 따라 검색 결과가 크게 달라지는 coherence 문제를 갖고 있음
- 기존의 일반적 파인튜닝(MNR + hard negative)은 relevance는 높일 수 있어도 coherence는 충분히 보장하지 못함
- 제안 방식의 의의
- 논문은 coherence를 손실함수에 직접 반영하는 Coherence Ranking Loss를 제안함
- 이 loss는
- 동치 질의 임베딩 간 거리 축소
- 동치 질의와 동일 positive/negative 문서 사이 margin 구조 일치
- 기존 MNR 기반 relevance 최적화
- 를 동시에 수행함
- 즉, “같은 의미면 같은 검색 결정을 하도록” 모델을 구조적으로 학습시키는 접근임
- 실험적으로 확인된 점
- MS-MARCO, Natural Questions, BEIR, TREC-DL 등 여러 벤치마크에서 coherence 향상 확인됨
- MPNet, MiniLM, ModernBERT 등 다양한 백본에서도 유사한 경향 확인됨
- 단순 coherence만 오른 것이 아니라 relevance 지표도 함께 개선되는 경우가 많았음
- 실무적 시사점
- 사용자가 질의를 조금 바꿔도 검색 결과가 덜 흔들리는 모델 구축 가능성 제시
- retrieve-and-rerank, RAG 같은 후속 파이프라인에서도 안정적인 후보 문서 제공 가능성 시사
- 특히 비슷한 점수의 문서가 많은 복잡 질의에서 일관성 강화 효과가 더 중요할 수 있다는 통찰 제공임
- 논문의 한계
- retrieval coherence가 end-to-end RAG 품질에 얼마나 크게 연결되는지는 제한적으로만 탐색함
- 정확도 개선 폭 자체는 절대값 기준으로 매우 큰 편은 아님
- 다만 저자들은 이 연구의 1차 목표가 “정확도 극대화”가 아니라 “coherence 개선”이며, 여러 데이터셋과 모델에서 일관된 추세를 보였다는 점을 강조함
- 한 줄 요약
- 이 논문은 “질의 표현이 달라도 같은 의미라면 같은 문서를 검색해야 한다”는 원칙을 DR 학습목표에 직접 넣어, 검색 일관성과 정확도를 함께 끌어올리는 방법을 제안한 연구임
This post is licensed under CC BY 4.0 by the author.