Guiding Cross-Modal Representations with MLLM Priors via Preference Alignment
Written By. Pengfei Zhao, Rongbo Luan, Wei Zhang (APPLE)
배경 및 문제의식
1-1. 크로스모달 리트리벌과 모달리티 갭 문제
- CLIP류 모델은 대규모 이미지–텍스트 쌍으로 contrastive learning을 수행해 좋은 성능을 보이지만, 여전히 모달리티 갭(modality gap) 이 존재:
- 특히 미세한 의미 차이가 있는 negative들(예: 비슷한 각도/배경의 비행기 사진들)을 잘 구분하지 못함.
기존 연구들은 이 갭의 원인을
- 아키텍처 (dual encoder 구조)
- 입력 정보 불균형
등에서 찾고, 평균 임베딩 거리나 KL 기반 지표 등으로 측정해 왔음.
1-2. MLLM(멀티모달 LLM)의 잠재적 강점
이 논문이 새로 관찰한 점:
오프더셸프 MLLM(여기선 Qwen2-VL 계열)이 CLIP보다 더 잘 맞는 모달 정렬 특성을 보인다.
하지만 MLLM은 일반적으로
- embedding space를 직접 노출하는 구조가 아니고,
- logits 기반으로 생성/판단을 수행.
그래서 기존의 임베딩 기반 modality gap 측정 법으로는 MLLM과 CLIP을 공정하게 비교하기 어려움.
또한 최근에는 MLLM을 retrieval용으로 fine-tuning하는 시도(E5-V, MM-Embed, VladVA 등)가 있었지만:
- 생성용 아키텍처 → 리트리벌 아키텍처로 변환하는 과정에서
- 오히려 기존 MLLM의 alignment 능력이 약화되는 경향이 관찰됨.
정리하면:
- CLIP류는 모달리티 갭 + coarse negative 처리 문제
- MLLM은 본질적으로 alignment는 좋은데, retrieval용 fine-tuning하면 그 장점이 죽음
- 이를 공통 지표로 정량화할 방법도 부족했음
방법론
이 논문의 해결책은 크게 두 축.
- 모달리티 갭을 공통 기준으로 재정의하는 지표 (Wasserstein Distance 기반)
- MLLM의 alignment priors를 embedding 학습에 이전하는 새로운 학습 프레임워크 MAPLE
2-1. 통합 모달리티 갭 지표: Wasserstein Distance 기반 Δ_gap
(1) 기존 평균 임베딩 기반 측정의 한계
기존에는 텍스트와 이미지의 평균 임베딩 차이로 갭을 재봤음:
| $\Delta_{\text{gap}} = | \mu_{\text{text}} - \mu_{\text{img}} | $ 꼴. |
하지만:
- 분포 전체(distribution) 가 아닌 평균만 보는 지표
- logits 기반 MLLM에는 직접 적용 불가 (임베딩이 명시적으로 없으니까)
(2) Wasserstein Distance(WD) 도입
그래서 저자들은 유사도 분포 간의 1-Wasserstein Distance를 사용:
- $P_A, P_B$: 두 분포(cross-modal similarity, intra-modal similarity)
WD: 한 분포를 다른 분포로 옮길 때 필요한 최소 평균 이동량.
\[W(P_A, P_B) = \inf_{\gamma\in\Pi(P_A,P_B)} \mathbb{E}_{(s_a,s_b)\sim\gamma}[|s_a - s_b|]\]- 실제 구현에서는 유한 샘플의 empirical distribution이므로 두 분포에서 샘플을 각각 정렬한 뒤, 아래와 같은 형태로 계산 가능
(3) Winoground-style 데이터셋에서의 측정 방식
Winoground 계열 데이터(두 이미지 + 두 캡션, 총 4개 요소, 2개 정답 쌍)에서:
- $T_0, T_1$: 두 캡션 집합
- $I_0, I_1$: 두 이미지 집합
두 가지 WD를 봄:
- Distributional gap(dist-gap):
- $W(P_{T_0I_0}, P_{T_0T_0})$ 등
- “텍스트-이미지 유사도 분포”와 “텍스트-텍스트 유사도 분포”가 얼마나 비슷한가
- 작을수록 좋지만, 0에 가까워지면 representation collapse 위험
- Discriminative gap(disc-gap):
- $W(P_{T_0I_0}, P_{T_0I_1})$ 등
- 정답 쌍과 오답 쌍의 유사도 분포 간 거리
- 클수록 모델이 정답/오답을 잘 구분함
최종 통합 지표:
\[\Delta_{\text{gap}} = \frac{W_{\text{dist-gap}}}{W_{\text{disc-gap}}}\]- 분모는 커야(잘 구분), 분자는 작아야(분포 정렬) 하므로 Δ_gap이 작을수록 좋은 모델.
이 지표는
- CLIP(embedding 유사도) → 그대로 유사도값 사용
- Qwen2-VL(Yes/No alignment score) → Yes/No에 대한 softmax 값을 사용
모두에 적용 가능 → 아키텍처가 달라도 비교 가능한 모달리티 갭 지표를 마련.
2-2. MAPLE 전체 개요
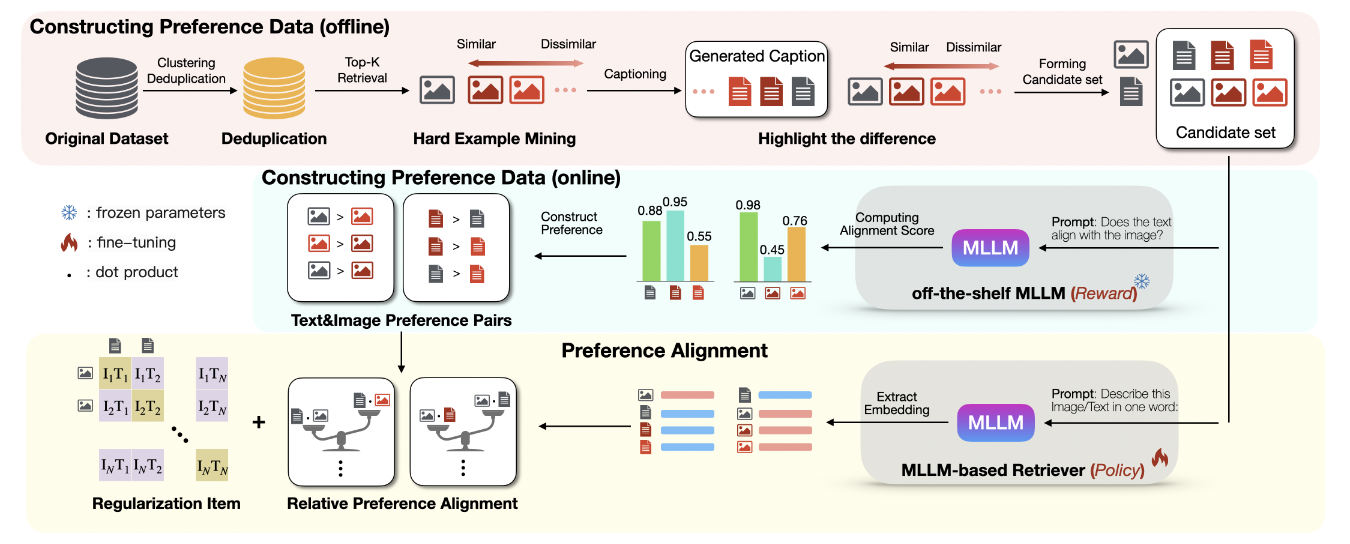
MAPLE (Modality-Aligned Preference Learning for Embeddings) 의 핵심 아이디어:
MLLM이 가지고 있는 세밀한 이미지–텍스트 선호(prior)를
리트리벌 임베딩 모델(policy)에 preference alignment 방식으로 전이하자.
구성 요소는 두 가지:
- Preference Data Construction
- 오프라인: hard negative 후보 준비
- 온라인: MLLM이 각 후보에 alignment score를 부여 → pairwise / listwise preference data 생성
- Preference Alignment (RPA Loss)
- Direct Preference Optimization(DPO)을 임베딩 학습용으로 변형
- 임베딩 similarity를 policy logit처럼 사용
2-3. MLLM 기반 Retriever 아키텍처
policy model은 프리트레인된 MLLM(Qwen2-VL-2B / 7B) 를 기반으로 함.
변경점은 두 가지:
- Causal mask → bidirectional attention
- 원래 MLLM은 autoregressive이지만, 리트리벌에서는 전체 input context를 동시에 보는 것이 유리함.
- 마지막 hidden state들의 mean pooling으로 임베딩 추출
- 텍스트 / 이미지 모두 “
Describe this text in one word:” 스타일의 프롬프트로 인코딩한 뒤, 마지막 layer의 hidden states 평균을 임베딩으로 사용.
- 텍스트 / 이미지 모두 “
이렇게 하면 dual encoder CLIP 구조처럼 텍스트/이미지 임베딩을 얻되, 내부는 여전히 shared MLLM backbone.
2-4. Preference Data Construction
2-4-1. Offline Stage: Candidate Generation
- 이미지 임베딩 추출 & Deduplication
- 전체 이미지 데이터(OpenImages human-verified subset)에서 DINOv2 임베딩 추출.
- SemDeDup로 근접 중복을 제거:
- 클러스터 수: 50,000
- epsilon=0.07을 써서 같은 클러스터 내에서 지나치게 유사한 샘플 제거
- Hard negative 검색
각 anchor 이미지 $x_i^{img}$에 대해 코사인 유사도로 top-K(논문 예시는 K=3) 이웃 $x̂_j$를 가져와 candidate set 구성:
\[C_i^{img} = \{x_i^{img}\} \cup \{\hat{x}_j^{img}\}_{j=1}^K\]이웃들은 시각적으로 anchor와 비슷하지만 다른 의미를 가질 가능성이 큰 hard negative.
- 비교형 캡션 생성
- MLLM(Qwen2.5-VL-72B)을 사용해 multi-image reasoning으로 “차이를 강조한 캡션” 생성.
- 프롬프트(요약):
- 두 이미지를 보고 각각에 대한 캡션을 생성하되, 둘 사이의 주요 시각적 차이를 강조
- Fig.4 예시처럼, “수상 비행기 vs 실내 박물관에 매달린 오래된 비행기” 같은 비교형 설명.
- 샘플링 전략:
- 각 anchor+hard negative 조합으로 여러 image pair를 만들고,
- temperature=0.7로 3회 반복 생성 → 다양한 표현 확보.
- 최종적으로 각 anchor에 대해:
- 이미지 후보 집합 $C_i^{img}$
- 텍스트 후보 집합 $C_i^{txt}$ (원래 caption + 생성 caption들)를 얻음.
2-4-2. Online Stage: Scoring & Structuring Preferences
온라인 학습 단계에서 reward model 역할을 하는 Qwen2-VL-7B 로 anchor–candidate 간 alignment score를 계산.
- Alignment score 계산
- Prompt:
"<image> Does the image align with the text <text>? Answer Yes or No"
- 이 프롬프트를 MLLM에 넣고, Yes/No 토큰의 logits $(l^{Yes}, l^{No})$을 얻음.
- softmax로 “Yes”의 확률을 alignment score로 사용: $\alpha_{ii} = \frac{\exp(l^{Yes}{ii})}{\exp(l^{Yes}{ii}) + \exp(l^{No}_{ii})}$
- Anchor 이미지 $x_i^{img}$ vs 모든 텍스트 후보 $x\in C_i^{txt}$ → $\alpha^{img2txt}_i$
- Anchor 텍스트$x_i^{txt}$ vs 모든 이미지 후보 $x\in C_i^{img}$ → $\alpha^{txt2img}_i$
- Prompt:
- 정렬 점수 기반 정렬(ranking)
- 각 anchor i에 대해 score vector $\alpha_i$를 내림차순 정렬:
- 인덱스 ${r_k}{k=0}^K$ : $\alpha{i, r_0} \ge \dots \ge \alpha_{i, r_K}$
- 이 순위를 기반으로 pairwise, listwise preference를 정의.
- 각 anchor i에 대해 score vector $\alpha_i$를 내림차순 정렬:
- Pairwise preference 구성
- 모든 $0 \le a < b \le K$에 대해: $P_i = {(x_{i,r_a}, x_{i,r_b}) }$
- 의미: anchor x_i 관점에서 후보 $x_{i,r_a}$는 $x_{i,r_b}$보다 선호된다 (alignment score가 더 크다).
- Listwise preference 구성
- rank list 전체 $(x_{i,r_0}, \dots, x_{i,r_K})$ 를 활용.
- 각 k(0~K-1)에 대해:
- $x_{i,r_k}$는 suffix ${x_{i,r_k}, \dots, x_{i,r_K}}$ 내에서 선호되는 top.
- 즉, 각 suffix마다 “가장 좋은” 후보를 정의하고, MLLM의 순위 전체 구조를 반영.
→ 이렇게 pairwise + listwise preference 데이터가 만들어지며, 이게 바로 RPA loss의 supervision signal이 됨.
2-5. Preference Alignment: DPO → RPA
2-5-1. DPO 기본 형태와 한계
DPO(Direct Preference Optimization) 원래 형태:
- 입력 x, 선호 응답 $y_w$, 비선호 응답 $y_l$
- 정책 $π_θ$, reference $π_w$
목표: $L_{\text{DPO}} = -\mathbb{E}\log \sigma\Big( \beta(\log\frac{\pi_\theta(y_w x)}{\pi_w(y_w x)} - \log\frac{\pi_\theta(y_l x)}{\pi_w(y_l x)}) \Big)$
여기를 그대로 retrieval에 적용하려면:
모든 (이미지,텍스트) 조합에 대한 π(y x)가 필요 → 조합 폭발 - $π_θ$(정책), $π_w$(레퍼런스), 별도 reward model까지 관리 → 메모리 부담
그래서 이 논문은 두 단계로 단순화 + 변형.
2-5-2. Reference 모델 제거 (DPO 단순화)
| 레퍼런스를 균일 분포 U로 두면, $\pi_w(y_w | x), \pi_w(y_l | x)$ 는 상수 취급 → log ratio에서 상쇄. |
단순화된 DPO:
\[L_{\text{DPO-simplified}} = -\mathbb{E}\big[ \log \sigma(\beta\log\pi_\theta(y_w|x) - \beta\log\pi_\theta(y_l|x)) \big]\]즉, “선호 응답의 log-확률이 비선호 응답보다 크도록 만드는” 형태.
2-5-3. Relative Preference Alignment (RPA) 정의
| 이제 log π_θ(y | x) 대신 정책 모델의 임베딩 유사도를 사용. |
- anchor 임베딩 $z_{\text{anchor}}$, candidate 임베딩 $z_{\text{candidate}}$
- similarity: $s = \beta (z_{\text{anchor}} \cdot z_{\text{candidate}})$
즉, RPA는 MLLM이 정한 preference 순서를, embedding similarity 순서가 따라가도록 만드는 목적 함수
(a) Pairwise RPA
텍스트 anchor $x_i^{txt}$와 pairwise preference $(x_{i,r_k}^{img}, x_{i,r_l}^{img})$ (k < l)에 대해:
- 모델 similarity: $s^{txt2img}{ik} = \beta(z_i^{txt}\cdot z{i,r_k}^{img})$
- MLLM alignment score: $\alpha^{txt2img}{i,r_k}, \alpha^{txt2img}{i,r_l}$
Pairwise RPA loss (text→image):
\[L^{txt2img}_{\text{RPA-Pairwise}} = -\frac{1}{N}\sum_i\sum_{0\le k<l\le K} (\alpha_{i,r_k}^{txt2img} - \alpha_{i,r_l}^{txt2img}) \cdot \log\sigma\big( s^{txt2img}_{ik} - s^{txt2img}_{il} \big)\]- 선호도의 차이(α 차이)가 클수록 가중치를 크게 → MLLM이 “차이가 크다”고 보는 pair에 더 강한 신호.
이미지 anchor에 대한 image→text loss도 대칭적으로 정의하고,
최종 pairwise RPA loss:
\[L_{\text{RPA-Pairwise}} = \frac{1}{2}(L^{txt2img}_{\text{RPA-Pairwise}} + L^{img2txt}_{\text{RPA-Pairwise}})\](b) Listwise RPA
Listwise는 PRO(Preference Ranking Optimization)에서 영감을 받아,
“각 suffix에서 top-ranked가 되도록” 하는 softmax 최적화를 사용.
텍스트 anchor 기준:
- ranked candidates: $(x_{i,r_0}^{img}, \dots, x_{i,r_K}^{img})$
- 각 k에 대해 suffix ${r_k, \dots, r_K}$ 를 고려
- 모델 similarity $s^{txt2img}_{ij}$
가중치:
\[w^{txt2img}_{ik} = \frac{1}{K-k} \sum_{l=k+1}^K (\alpha^{txt2img}_{i,r_k} - \alpha^{txt2img}_{i,r_l})\]→ “해당 k 후보가 뒤에 있는 모든 후보보다 얼마나 선호되는지” 의 평균 margin.
Listwise RPA loss (text→image):
\[L^{txt2img}_{\text{RPA-Listwise}} = -\frac{1}{N}\sum_i\sum_{k=0}^{K-1} w^{txt2img}_{ik} \cdot \log \frac{\exp(s^{txt2img}_{ik})}{\sum_{j=k}^K \exp(s^{txt2img}_{ij})}\]image→text도 마찬가지로 정의하고,
최종 listwise RPA loss:
\[L_{\text{RPA-Listwise}} = \frac{1}{2}(L^{txt2img}_{\text{RPA-Listwise}} + L^{img2txt}_{\text{RPA-Listwise}})\]실험적으로는 Listwise > Pairwise가 일관되게 더 좋은 성능을 보임.
(이유: 전체 순위 구조를 한 번에 반영하기 때문이라고 저자들이 해석)
2-6. Contrastive Regularization & Expanded Negatives
2-6-1. Contrastive regularizer와 최종 Loss
RPA만 사용하면 MLLM의 선호에 과도하게 맞추다가 representation collapse나 general retrieval 성능 저하 위험.
그래서:
원래 anchor pair $(x_i^{img}, x_i^{txt})$에 대해
CLIP-style symmetric InfoNCE contrastive loss $L_{\text{contrast}}$ 를 계산.
- 최종 objective: $L= \lambda L_{\text{RPA}} + (1-\lambda)L_{\text{contrast}}$
- λ가 클수록 RPA를 강조(세밀 분별↑, general R@1은 희생)
- λ를 적절히 tuning해서 두 성능 사이의 trade-off를 맞춤.
2-6-2. Expanded Negative Pool
MLLM은 batch를 크게 키우기 어렵기 때문에,
hard negative 후보 K개를 추가 negative로 활용해서 “effective batch size”를 키우는 전략을 씀.
- 한 디바이스당 anchor N개, hard negatives K개 → 총 N(1+K) 샘플
- 여러 디바이스에서 이를 모으고, duplicate 제거 후 contrastive loss 계산
이렇게 하면 추가 GPU 메모리 없이 더 많은 negative를 사용 가능.
2-7. 학습 세팅 및 구현 디테일
Appendix B.2 기준:
- Policy model: Qwen2-VL-2B / 7B
- Reward model: Qwen2-VL-7B (Yes/No alignment scoring)
- LoRA:
- Rank r=32, Alpha=32
- LLM의 attention/projection layer만 LoRA 적용
- vision encoder & connector는 freeze
- 학습 하이퍼파라미터:
- Optimizer: AdamW
- Base LR(LoRA): 5e-4
- τ(contrastive temperature), β(RPA scale)는 learnable 파라미터
- 초기값: τ=0.07, β ≈ 14.29(=1/0.07)
- LR schedule: Linear warmup + cosine decay
- Warmup ratio: 전체 step의 2.5%
- Epoch: 8
- Batch / GPU:
- 2B: 96
- 7B: 48
- Image resolution: 384×384
- 인프라 & 최적화:
- 32× A100 80GB
- bfloat16 mixed precision
- gradient checkpointing
- FlashAttention 사용
- 전체 학습 약 32시간
실험 결과
3-1. 데이터셋 및 평가 설정
학습 데이터
- OpenImages v4 human-verified subset 기반
- SemDeDup 클러스터링 후 stratified sampling으로 약 70만 개 인스턴스 사용.
평가 데이터
- General retrieval
- MS-COCO
- Flickr30K
- 지표: Text/Image R@1
- Fine-grained retrieval
- Winoground (400 인스턴스)
- 조합적 비주얼-언어 compositionality 평가
- NaturalBench (1,200 인스턴스)
- Winoground를 확장한 자연 adversarial 샘플
- MMVP (135 인스턴스, 9 카테고리)
- Orientation, Count, Color, Text, Viewpoint 등
- BiVLC (2,933 인스턴스)
- Replace / Swap / Add 세 가지 변환 유형으로 text-to-image retrieval compositionality 평가
- Winoground (400 인스턴스)
각 인스턴스 (x0_img, x1_img, x0_txt, x1_txt)에 대해:
- Image score:
- 각 텍스트가 올바른 이미지를 더 높게 매기는지
- Text score:
- 각 이미지가 올바른 텍스트를 더 높게 매기는지
둘 다 만족해야 1점으로 계산.
3-2. 메인 결과
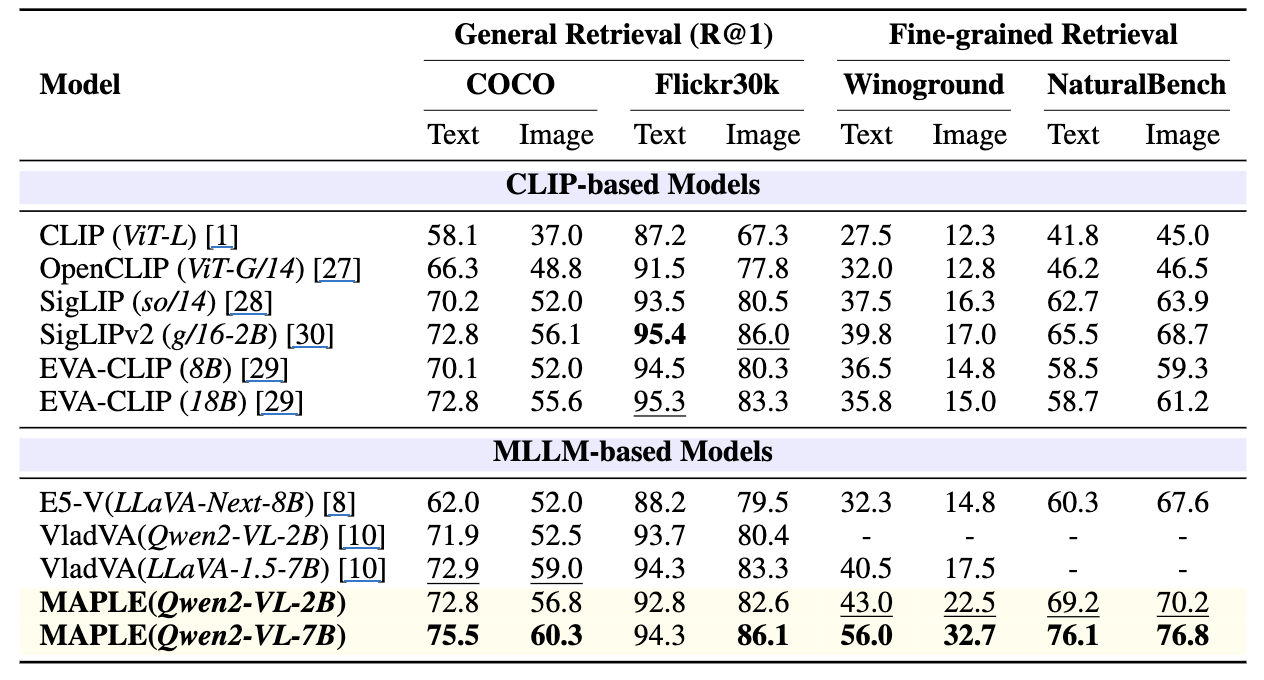
결과:
- MAPLE(Qwen2-VL-7B)가 전반적으로 최고 성능
- Fine-grained:
- Winoground: 기존 최고였던 VladVA보다 큰 폭 향상
- 비슷한 파라미터 규모인 Qwen2-VL-2B에서도 MAPLE(2B)이 기존 VladVA(2B)와 동급~우수한 성능.
→ MLLM priors 기반 preference alignment가 특히 fine-grained 벤치마크에서 큰 효과를 보임.
3-3. Ablation: Loss 구성
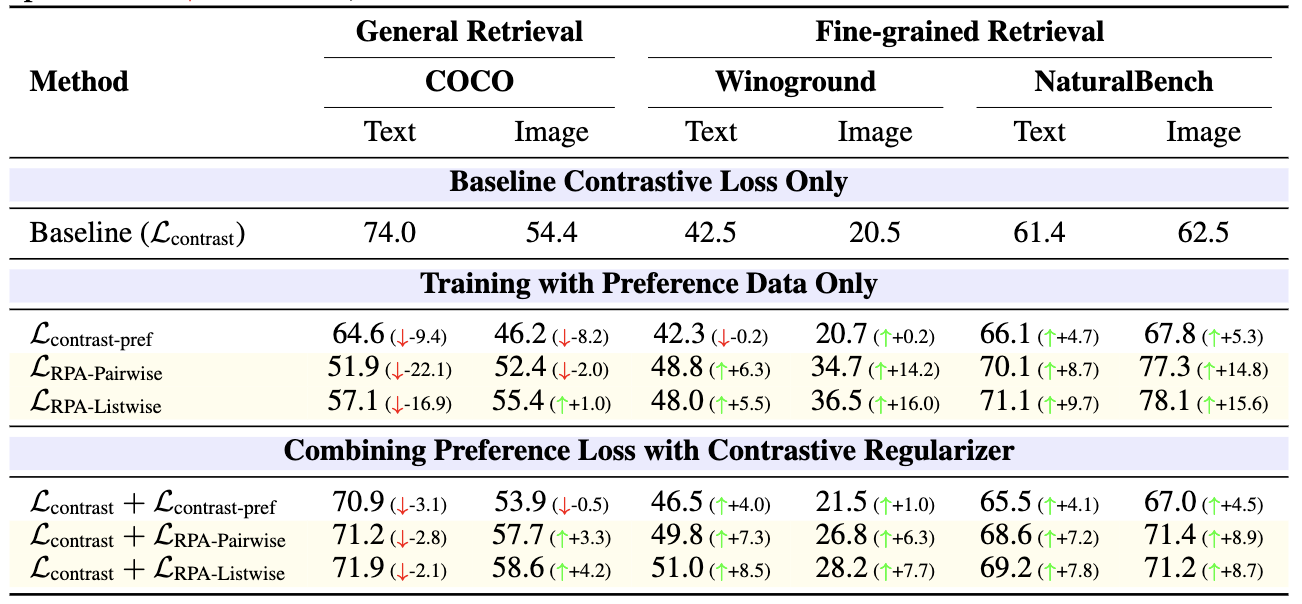
결론:
- preference 정보 자체가 굉장히 유용하지만,
- general retrieval을 유지하려면 contrastive regularizer가 필수.
- RPA > 단순 contrastive on preference
- listwise RPA > pairwise RPA
3-4. Expanded Negatives & RPA 조합
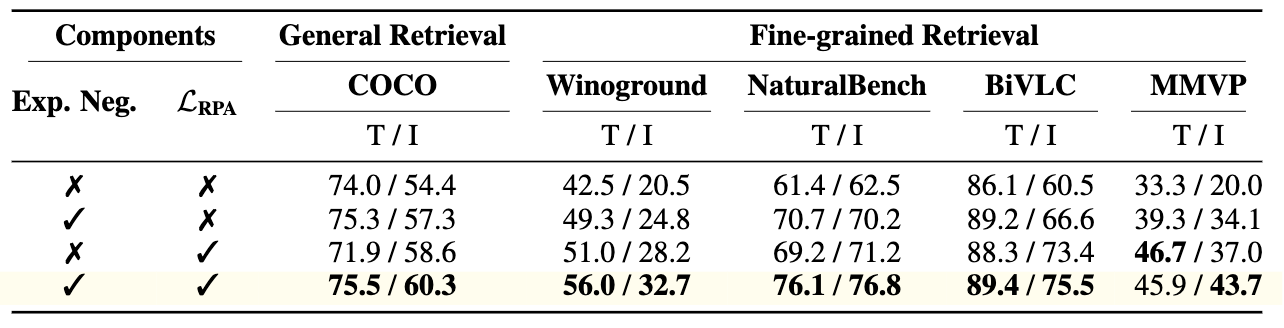
- hard negative를 contrastive에 활용하는 전략과
- RPA listwise를 결합했을 때 균형 잡힌 최고 성능.
3-5. 모달리티 갭 측정 결과
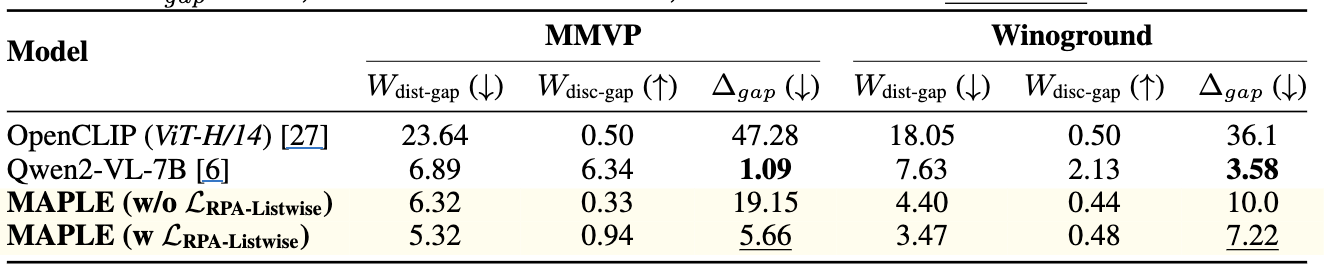
- MMVP / Winoground에서 Δ_gap 비교
관찰:
- 기본 Qwen2-VL-7B 자체가 모달리티 갭이 매우 작음 (alignment가 뛰어남)
- MAPLE w/ RPA는
- distributional gap을 줄이면서,
- discriminative gap을 적절히 유지/향상 → Δ_gap를 낮춘다.
또한 훈련 과정에서 Δ_gap이 어떻게 변하는지
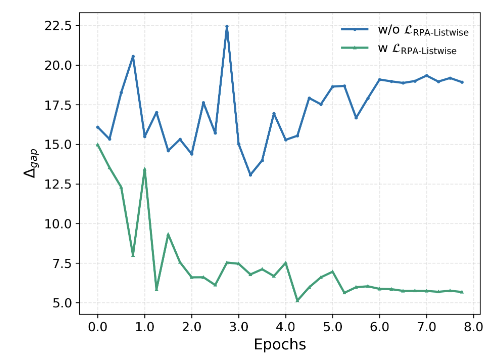
3-6. λ trade-off, Caption Sampling, Pattern-wise 분석
λ 변화에 따른 성능
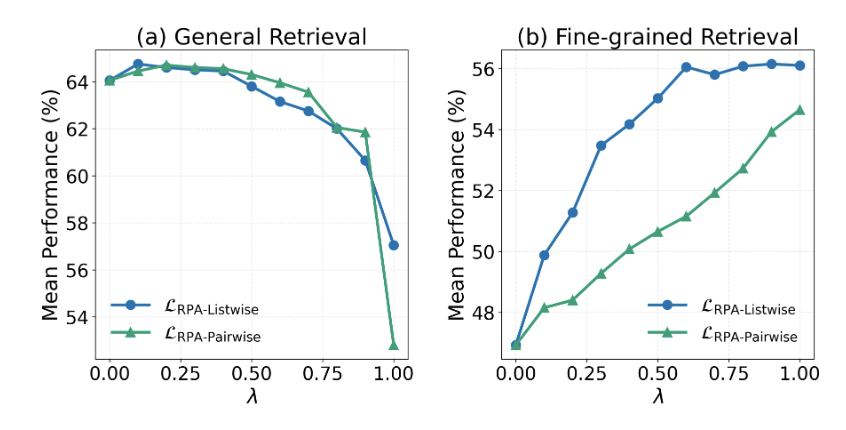
- λ(=RPA 비중)가 커질수록 fine-grained 성능은↑, general R@1은↓
- 적절한 중간값에서 전체 성능 균형이 가장 좋음.
Caption sampling 전략 A/B/C
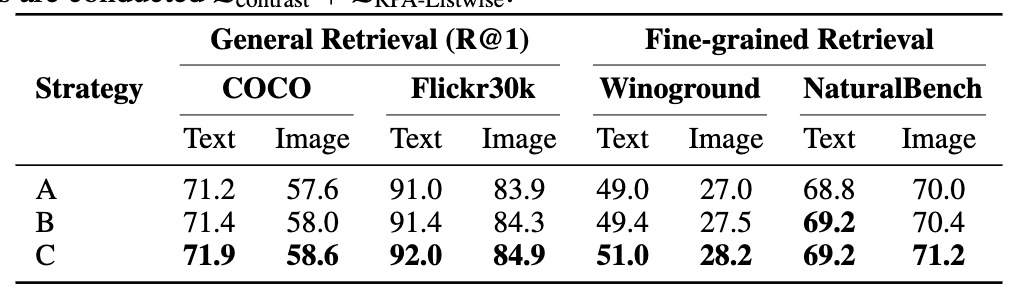
- A: 각 pair에서 첫 caption만 사용
- B: 첫 3개 캡션 중 랜덤 1개
- C: 전체 6개 캡션 pool에서 샘플링
- C가 항상 best → caption diversity가 성능에 기여
MMVP(9 category)
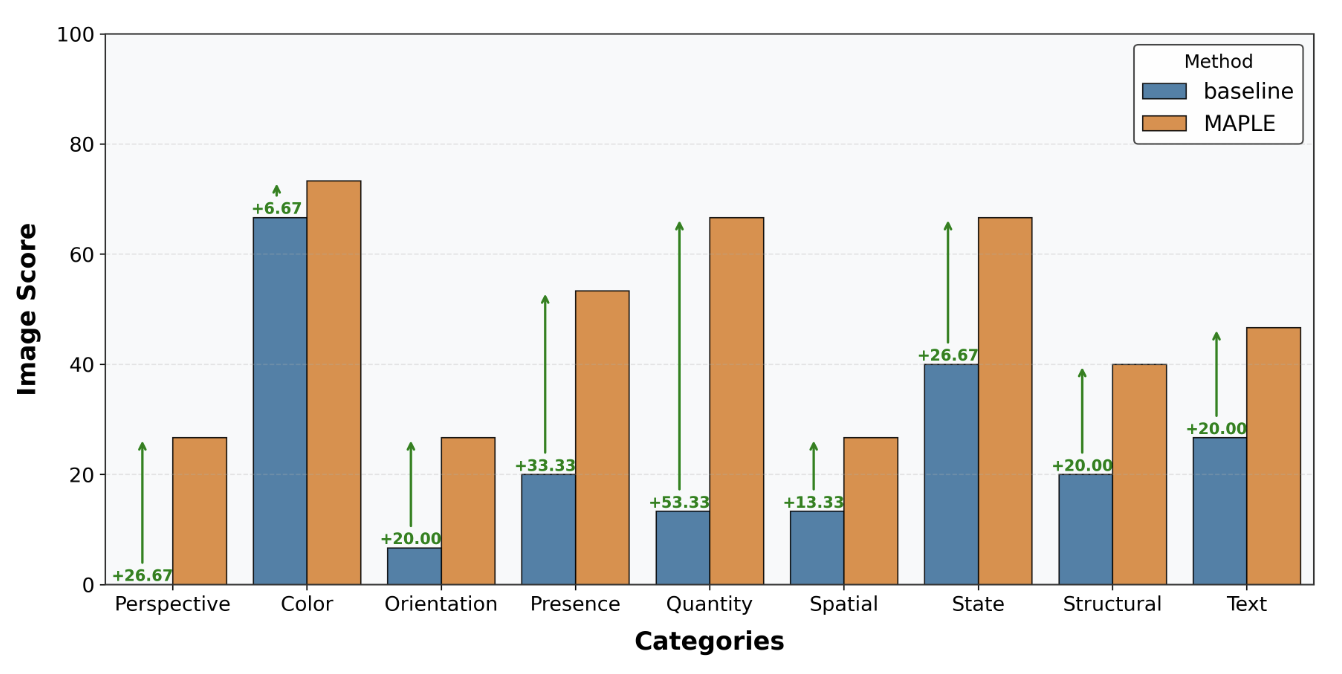
- baseline은 Color, State 패턴에서 상대적으로 강하지만 다른 패턴은 약함
- MAPLE은 Orientation, Count, Text, Viewpoint 등 난이도 높은 패턴에서 특히 큰 향상
Qualitative Retrieval 예시 (어펜딕스 Fig.9 참고)
- preference alignment 전/후 ranking 비교 → 세밀한 조건(“without the dog”, 숫자 22 등)을 더 잘 반영하는 것을 확인.
결론
4-1. 논문의 핵심 메시지
- MLLM은 생각보다 강력한 cross-modal alignment 능력을 내재적으로 갖고 있다.
- 이를 WD 기반 Δ_gap 지표로 정량화해 보여줌.
- 이 alignment prior를 그대로 죽이지 말고, 오히려 embedding 기반 retriever에 전이할 수 있다.
- 그 수단으로 MAPLE을 제안:
- MLLM을 reward 모델로 보고 alignment score를 통해 자동 preference data 생성
- DPO를 임베딩 학습에 맞게 변형한 RPA loss로 fine-grained alignment 수행
- contrastive loss를 regularizer로 넣어 general retrieval도 유지
- 다양한 벤치마크에서, 특히 fine-grained retrieval 성능이 크게 향상됨을 실험으로 입증.
4-2. 한계 및 향후 과제
논문에서 명시한 한계:
- MLLM의 편향(bias)이 그대로 transfer될 수 있음
- reward model이 MLLM이므로, 그 안의 사회적/시각적 bias가 preference로 반영될 위험.
- 단순 retrieval 중심으로 검증
compositional retrieval(복합 쿼리), multi-hop reasoning 기반 retrieval 등
더 복잡한 시나리오에 대한 검증이 부족.
향후 방향(저자 관점):
- MLLM alignment priors를 다른 멀티모달 representation learning 문제에 확장
- human preference + MLLM preference hybrid, 혹은 여러 MLLM ensemble 활용
- caption generation/data curation을 더 정교하게 설계해 추가 성능 향상