MokA : Multimodal Low-Rank Adaptation for MLLMs
Written By. Yake Wei, Yu Miao, Dongzhan Zhou, Di Hu
1. 문제 정의
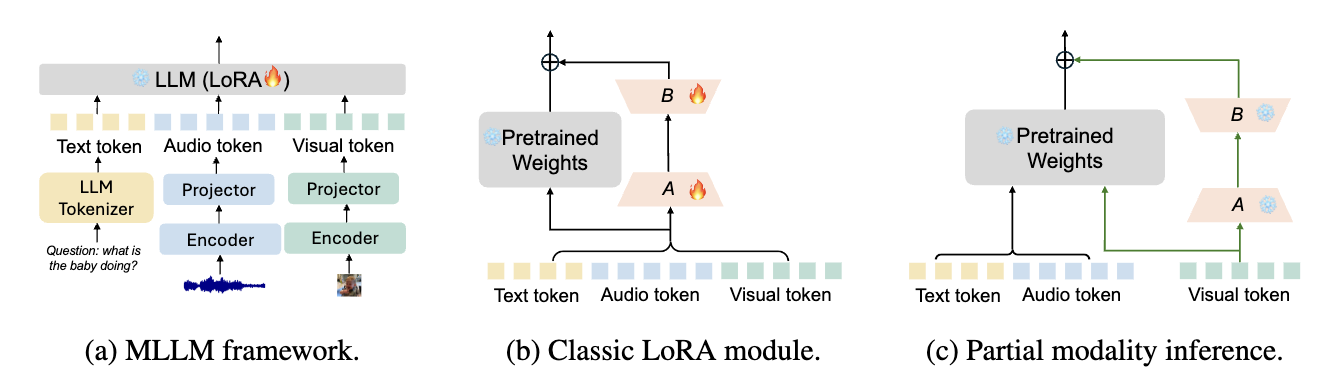
배경: MLLM의 PEFT가 LLM 방법을 그대로 가져오면서 생기는 문제
- MLLM(멀티모달 LLM)은 보통 비텍스트(이미지/오디오/스피치) 입력을 인코더로 특징 추출한 뒤, projector(Q-former/MLP 등) 로 LLM의 텍스트 임베딩 공간에 맞춰 토큰으로 만든 다음, 텍스트 토큰과 합쳐 LLM에 넣는 구조.
- PEFT(특히 LoRA)를 MLLM에 적용할 때도, LLM 백본은 freeze, LoRA만 학습하는 방식. 기존 LoRA는 모든 모달 토큰에 동일한 LoRA(A,B)를 공유
핵심 Observation: 공유 LoRA가 텍스트에 치우쳐서 비텍스트 토큰을 덜 활용
논문은 partial modality inference라는 실험 분석:
- 학습은 정상적으로(모든 모달 토큰이 LoRA를 통과) 해두고,
- 추론(prefilling 단계) 에서는 특정 모달의 토큰만 LoRA 경로를 통과시키고 나머지 모달 토큰은 LoRA 없이 프리트레인 가중치(W0)만 지나가게 함.
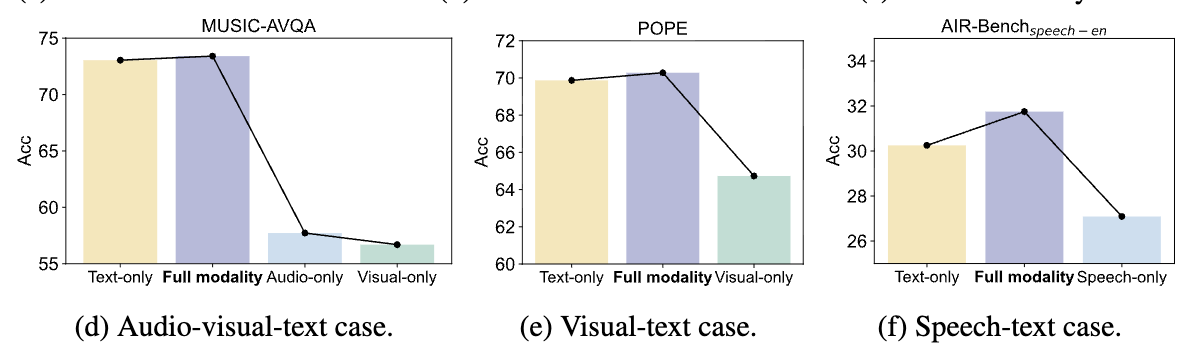
- Text-only LoRA 경로만 켜도 Full-modality와 성능이 꽤 비슷
반대로 Visual-only / Speech-only 로 LoRA 경로를 제한하면 성능이 크게 떨어짐
→ 학습된 공유 LoRA가 사실상 텍스트 토큰의 그래디언트에 의해 지배되어, 비텍스트 토큰의 적응(활용)이 약해진다는 해석 제시
논문의 관점 정리: MLLM 튜닝에는 두 가지가 모두 필요
- Unimodal adaptation(모달별 적응): 각 모달에서 고유 정보를 잘 압축/반영
- Cross-modal adaptation(교차모달 적응): 텍스트(instruction)와 비텍스트(context) 간 상호작용을 통해 필요한 단서를 강조
2. MokA = 모달별 A + (텍스트 중심) 교차어텐션 + 공유 B
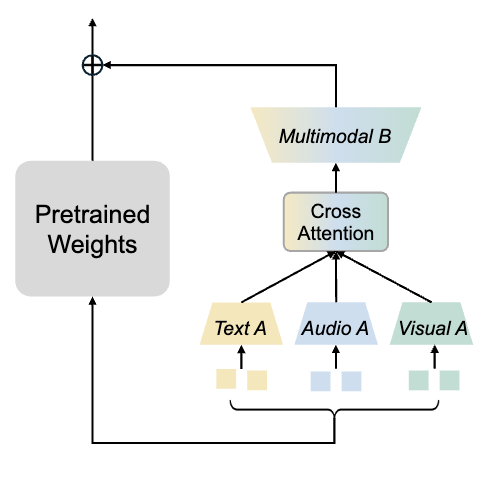
MokA는 LoRA의 저랭크 업데이트를 유지하되, A/B의 역할을 멀티모달에 맞게 재설계
- Unimodal matrix A (모달별 A)
- Task-centric cross-attention (텍스트-비텍스트 상호작용을 명시적으로 강화)
- Shared multimodal matrix B (공유 B로 통일 공간에 투영)
2.1 MokA의 목표 수식: unimodal update + cross-modal update를 동시에 만들기
논문은 멀티모달 입력을 모달별로 $x^{m_1},…,x^{m_n}$이라 하면,
- 모달별 업데이트 $\Delta W_i x^{m_i}$ (unimodal)
전체를 섞어서 만드는 $\Delta W_{cross}[x^{m_1};…;x^{m_n}]$ (cross-modal)
가 forward에 동시에 존재해야 한다고 주장.
MokA는 이걸 A/B를 “모달별/공유”로 나누고, 그 사이에 cross-attention을 넣어 구현.
2.2 Unimodal matrix A: A를 모달별로 분리해서, 각 모달이 독립적으로 저랭크 압축
입력 시퀀스 정의
오디오-비전-텍스트 예시로 입력 토큰 시퀀스: $x = [x^a_1,…,x^a_{N_a};\;x^v_1,…,x^v_{N_v};\;x^t_1,…,x^t_{N_t}]$
간단히 $x=[x^a;x^v;x^t]$로.
핵심 설계
기존 LoRA는 A 하나로 모든 모달을 압축했는데, MokA는
- $A_a, A_v, A_t$ 처럼 모달별로 다른 A 정의.
- 각 모달 토큰은 자기 모달의 A로만 저랭크 공간으로 매핑.
$Ax = [A_a x^a;\; A_v x^v;\; A_t x^t]$
압축(저랭크 표현) 단계에서부터 모달 간 간섭을 차단하여 unimodal 정보를 보존/학습시키려는 목적.
2.3 Task-centric cross-attention: 텍스트(질문/지시) 기반으로 비텍스트 토큰을 업데이트
여기가 MokA의 멀티모달 핵심.
왜 텍스트 중심인가?
인스트럭션 튜닝 데이터에서 텍스트 토큰은 대개 task description(질문/지시) 이고, 오디오/비전/스피치는 컨context/evidence. 예: <audio> <visual> Please answer the question: ...
따라서 “질문과 관련 있는 비텍스트 단서”를 잘 끌어내려면 텍스트-비텍스트 결합을 명시적으로 강화하는 게 필요.
왜 ‘저랭크 압축(A) 후’에 cross-attention을 넣나?
- 이미 저랭크 공간에 내려왔으니,
- cross-attention을 여기서 수행하면 계산량이 줄고(토큰 차원/특징 차원 관점),
- unimodal 정보가 분리된 상태에서 교차모달 결합을 추가 단계로 주입 가능.
cross-attention의 방향
- MokA는 비텍스트 토큰을 Query로, 텍스트 토큰을 Key/Value로 두는 형태
- 즉 텍스트 정보를 비텍스트 토큰에 주입
수식: 오디오/비전 각각 텍스트로부터 attention을 받는다
- 오디오 쪽: $(A_a x^a, A_t x^t, A_t x^t)=\text{softmax}\left(\frac{(A_a x^a)(A_t x^t)^\top}{\sqrt{N_t}}\right)A_t x^t$
- 비전 쪽도 동일하게: $(A_v x^v, A_t x^t, A_t x^t)=\text{softmax}\left(\frac{(A_v x^v)(A_t x^t)^\top}{\sqrt{N_t}}\right)A_t x^t$
- 그리고 residual로 강화: $A_a x^a \leftarrow A_a x^a + \lambda_a Att_{a,t,t} \quad / A_v x^v \leftarrow A_v x^v + \lambda_v Att_{v,t,t}$
- 여기서 $\lambda_a,\lambda_v$는 cross-modal 하이퍼파라미터.
최종:
\[Ax = [A_a x^a + \lambda_a Att_{a,t,t};\; A_v x^v + \lambda_v Att_{v,t,t};\; A_t x^t]\]
왜 Wq/Wk/Wv를 안 쓰나?
보통 attention에는 Q/K/V linear 프로젝션이 있는데 MokA는 기본 형태에선 이를 생략.
이유:
- 이미 $A_i$ 자체가 projection 역할을 한다고 보고,
- Key/Value projection을 공유하는 전략이 효율적이며(예: Linformer 등),
- 무엇보다 텍스트 토큰을 바꾸지 않고 비텍스트 쪽만 강화하려는 목적이 큼.
2.4 Shared multimodal matrix B: 공유 B로 모든 모달을 동일 공간으로 다시 올려 정렬
\[BAx = [B(A_a x^a + \lambda_a Att_{a,t,t});\; B(A_v x^v + \lambda_v Att_{v,t,t});\; BA_t x^t]\]2.5 학습/구현 세팅 요약
- 전체 구조는 일반 MLLM과 동일: non-text encoder → projector(Q-former + 2-layer MLP) → LLM 입력 토큰 결합.
- 비전 인코더: CLIP ViT/L-14, 오디오 인코더: BEATs, 스피치 인코더: Whisper.
- 2-stage 학습:
- Pre-training: LLM은 freeze, projector만 학습(모달-텍스트 정렬).
- Instruction-tuning: projector + MokA만 학습(LLM freeze).
- 저랭크 rank는 기본 4로 사용.
3. 실험 결과
논문은 3가지 대표 멀티모달 시나리오에서 평가.
- Audio-Visual-Text (AVL): MUSIC-AVQA, AVE
- Visual-Text (VL): MMEpercep, MMBench, POPE, SEED-Bench
- Speech-Text (SL): MMAUmini-speech, AIR-Benchspeech-en
3.1 AVL: MUSIC-AVQA / AVE
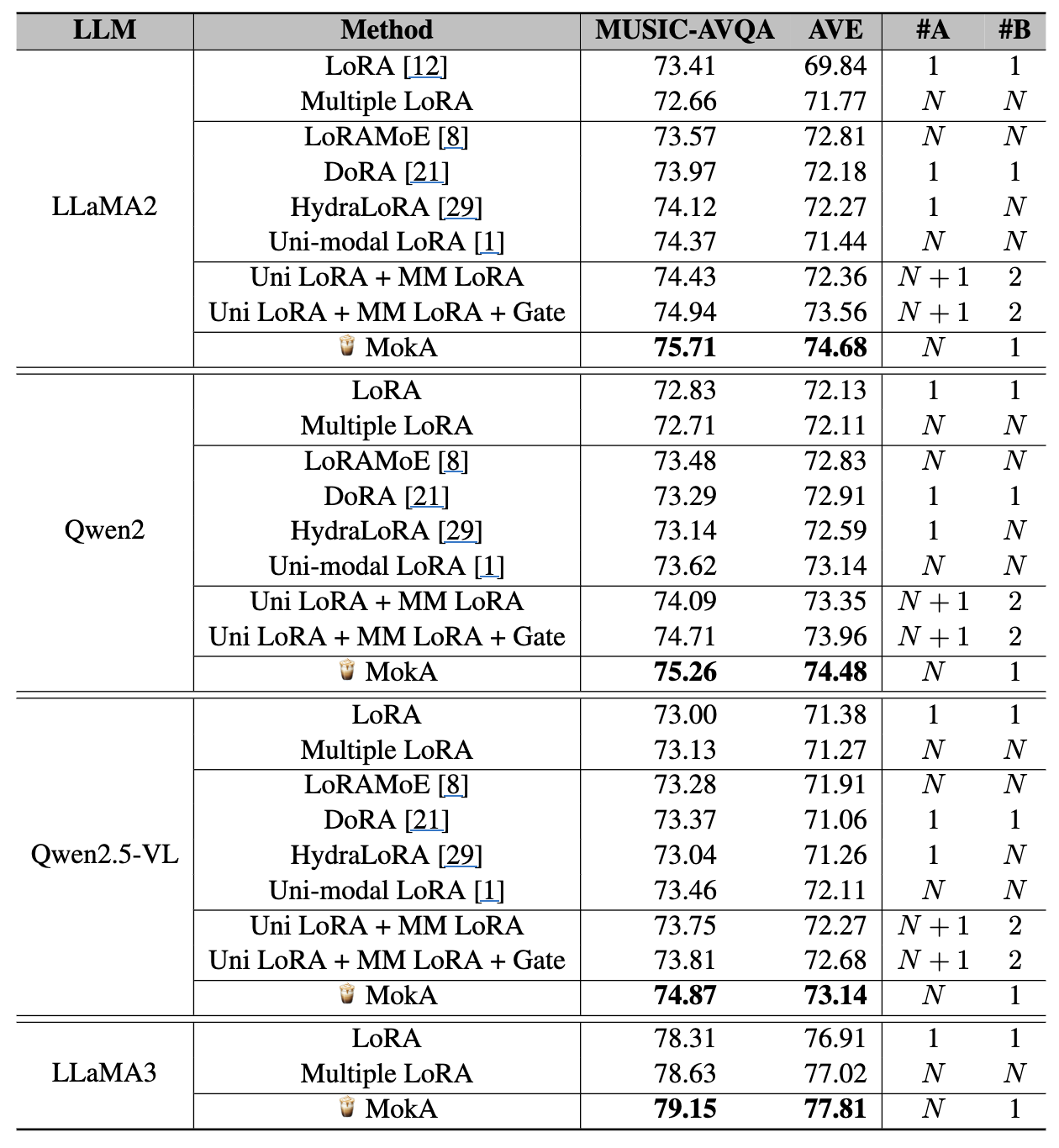
LLaMA2 기준
- LoRA: 73.41 / 69.84
MokA: 75.71 / 74.68 (둘 다 큰 폭 개선)
또한 단순히 파라미터만 늘린 Multiple LoRA(모달별 A,B를 늘림)는 오히려 성능이 떨어질 수 있다는 점을 강조(개수 증가 ≠ 성능 증가).
Qwen2 기준
- LoRA: 72.83 / 72.13
- MokA: 75.26 / 74.48
Qwen2.5-VL / LLaMA3도 실험
- Qwen2.5-VL은 LoRA 자체 성능이 높지만, MokA도 여전히 개선을 주는 것으로 보고(단, 다른 백본 대비 이득이 상대적으로 작을 수 있다고 해석)
- LLaMA3에서도 MokA가 개선
3.2 VL: 4개 벤치마크
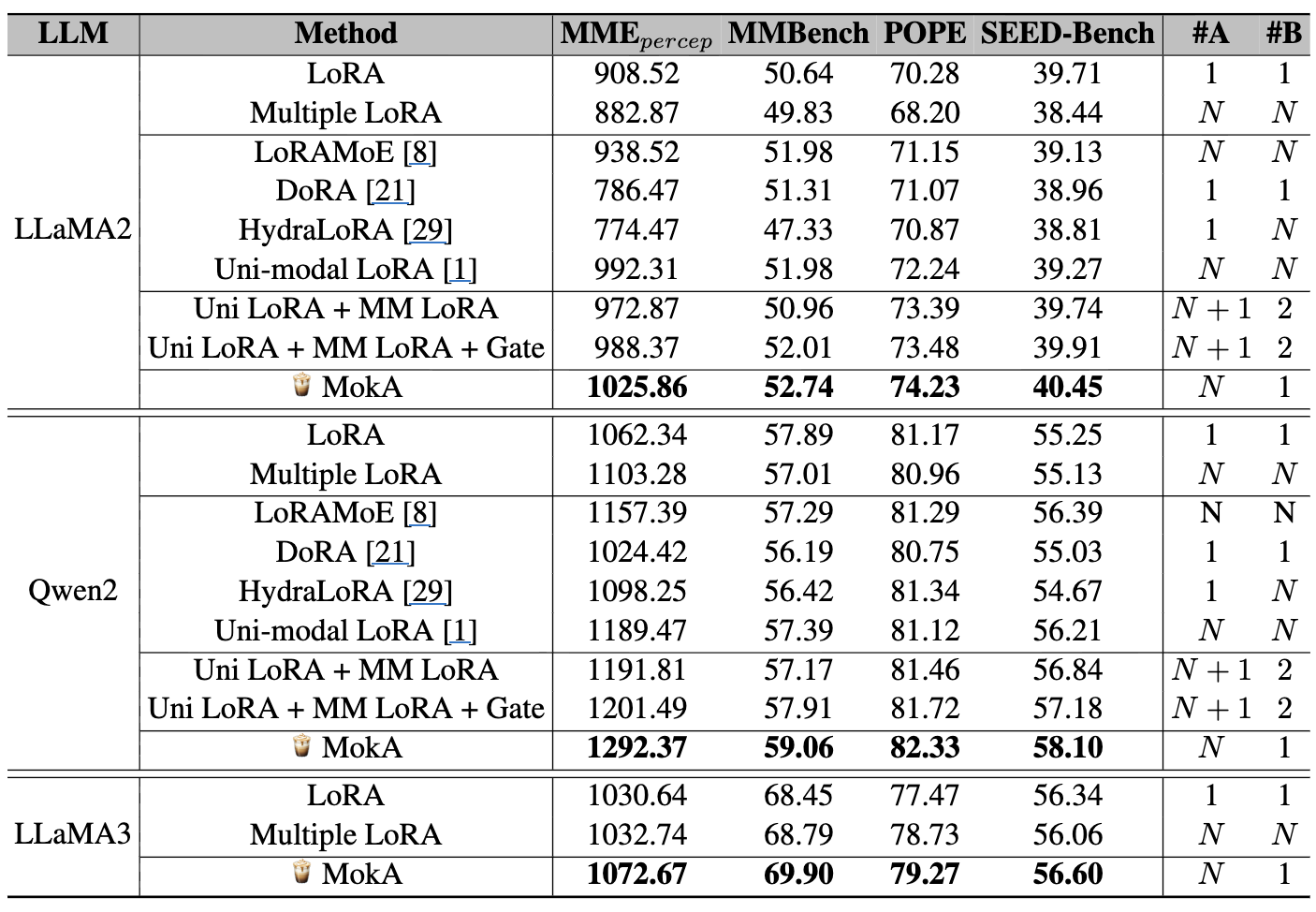
LLaMA2, Qwen2 상승
3.3 Speech-Text: MMAU / AIR-Bench
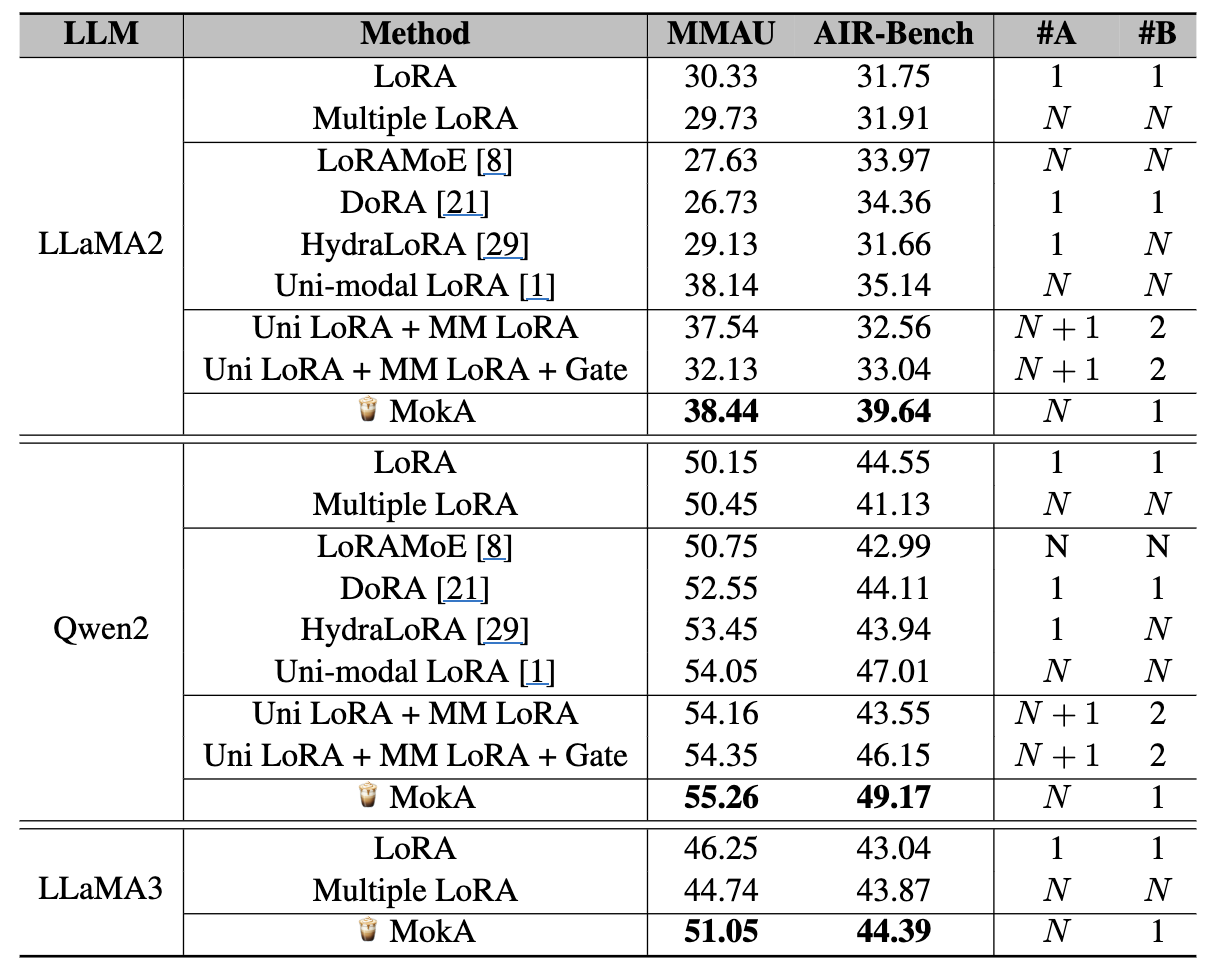
LLaMA2, Qwen2 상승
4. 추가 분석
4.1 Partial modality inference: MokA는 비텍스트도 쓸 수 있게 만듬
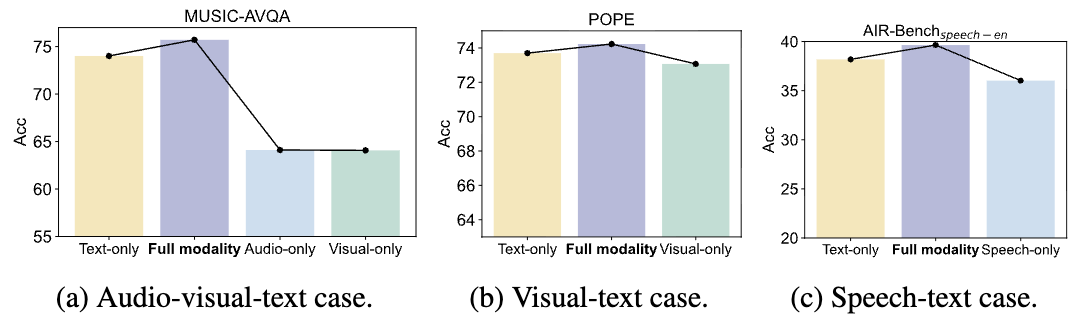
LoRA에서 관찰된 텍스트만으로도 성능이 비슷 / 비텍스트만 쓰면 급락 현상을 다시 보되,
- cross-attention은 텍스트/비텍스트가 같이 있어야 계산되므로,
- 여기서는 MokA w/o cross-attention(= 모달별 A + 공유 B만)으로 partial modality inference를 수행
4.2 Cross-modal interaction 모듈 변형 비교
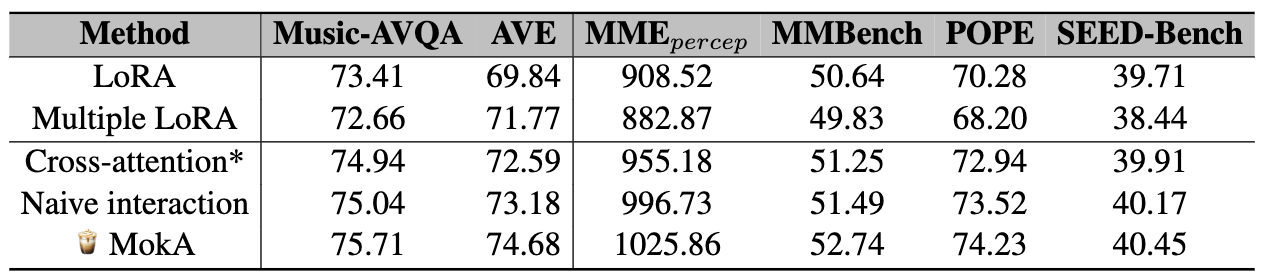
- cross-attention* (텍스트가 query가 되는 반대 방향), naive interaction (attention 없이 단순 매핑), MokA(원래 방식)
- 모두 LoRA보다 좋아지고, 그중 MokA가 가장 좋음.
- 특히 cross-attention*이 상대적으로 약한 이유로 텍스트 토큰 자체가 변형되면 LM 능력에 악영향 가능성
4.3 Ablation
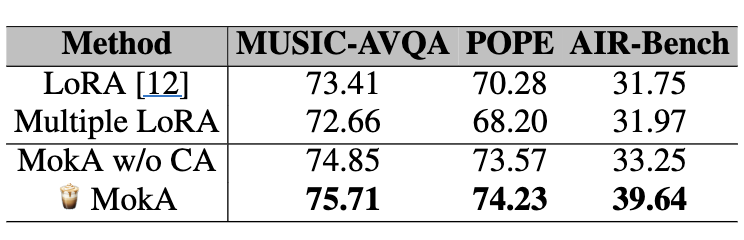
- MokA w/o CA(= unimodal A + shared B만): LoRA보다 좋음 → unimodal 강화만으로도 이득
- MokA(= + cross-attention): 추가 상승 → explicit cross-modal 강화의 이득
4.4 효율: 파라미터 증가 vs 성능
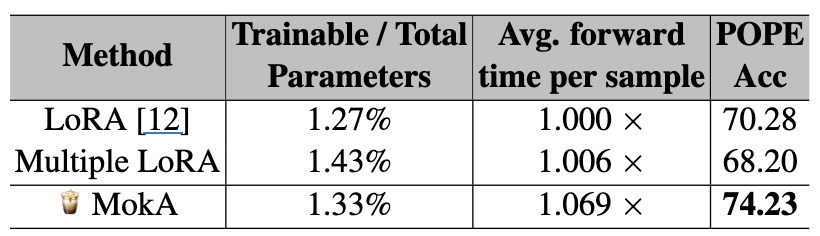
- POPE 기준 미세한 비용 증가로 의미 있는 성능 상승
5. Conclusion
- 기존 LoRA 기반 PEFT는 MLLM에서 모든 모달리티 토큰이 동일한 저랭크 업데이트를 공유함으로써, 학습이 텍스트 모달리티에 편향되고 비텍스트 정보 활용이 제한되는 한계를 가짐.
- 본 논문은 이를 해결하기 위해 MokA (Multimodal Low-Rank Adaptation) 를 제안하며, multimodal adaptation을 unimodal adaptation과 cross-modal adaptation 으로 분해
- MokA는 모달리티별 저랭크 행렬 A, 텍스트 중심 cross-attention, 공유 저랭크 행렬 B를 통해 멀티모달 정보를 효과적으로 통합
- 다양한 멀티모달 벤치마크와 여러 LLM 백본에 대한 실험을 통해, MokA가 기존 LoRA 및 그 변형 방법들보다 일관되게 우수한 성능을 보임을 확인
- 또한 MokA는 추가적인 파라미터 수와 연산 비용 증가가 매우 제한적이어서, 실용적인 파라미터 효율적 멀티모달 튜닝 방법임을 확인.