Negative Matters: Multi-Granularity Hard-Negative Synthesis and Anchor-Token-Aware Pooling for Enhanced Text Embeddings
Negative Matters: Multi-Granularity Hard-Negative Synthesis and Anchor-Token-Aware Pooling for Enhanced Text Embeddings
Written by. Tengyu Pan, Zhichao Duan, Zhenyu Li
1. 연구 배경
- 텍스트 임베딩 모델은 문장을 벡터로 변환해 의미적 유사도를 계산하는 데 핵심적 역할.
- 일반적으로 (query, positive, negative) 구조로 contrastive learning으로 학습되며, 특히 hard negative의 품질이 모델 성능을 크게 좌우.
- 기존 연구에서 LLM을 활용한 synthetic data 생성이 활발했지만, 효과적인 hard negative 생성은 여전히 도전 과제.
2. 주요 기여
- MGH (Multi-Granularity Hard-negative) Synthesis
- LLM을 활용하여 서로 다른 유사도 수준(High, Medium, Low) 의 hard negative를 한 번에 생성.
- Negative 샘플을 난이도별로 구성하여 coarse-to-fine curriculum learning 적용.
- 모델이 점진적으로 미묘한 의미 차이를 학습하도록 유도.
- ATA (Anchor Token Aware) Pooling
- 기존 mean pooling / last token pooling의 한계를 극복.
- LLM의 정보 집약 패턴(aggregation pattern) 을 활용해 anchor token에 더 높은 가중치 부여.
- 추가 파라미터 없이 성능 향상.
3. 방법론
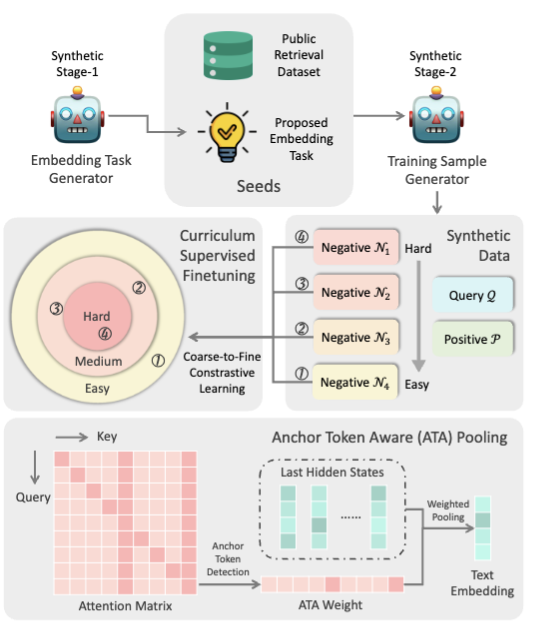
3.1 MGH Data Synthesis
- Stage 1 (Task Brainstorming): LLM을 이용해 다양한 매칭 task(비대칭: short-long, long-long / 대칭: STS 등) 생성.
- 실제로 임베딩 학습에 유용한 쿼리-문서 태스크를 먼저 정의하는 것.
- 기존 한계
- 대부분의 기존 연구에서는 단일 유형의 태스크(예: STS, FAQ 검색 등)에만 기반
- 결과적으로 생성되는 negative 샘플의 다양성과 일반화 성능 부족
- 논문의 해결책
- LLM에게 태스크 자체를 생성
- 생성 데이터
- 비대칭 (Asymmetric Tasks)
- 하위 유형:
- Short → Long
- Long → Short
- Long → Long
- Short → Short
설명 예시 쿼리와 정답 문서가 다른 구조 검색어는 짧고, 정답 문서는 길고 설명적 Semantic match지만 Paraphrase는 아님 “Who is Elon Musk?” → “Elon Musk is a business magnate…” - 비대칭 (Asymmetric Tasks)
- 대칭 (Symmetric Task)
설명 예시 Query와 문서가 거의 동일한 의미 Semantic Textual Similarity (STS) 의미적 재표현 “The earth orbits the sun.” ↔ “The sun is orbited by the earth.” - 프롬프트 설계
- “Brainstorm a list of potentially useful text retrieval tasks. Each one should specify what the query is, and what the desired documents are.”
Stage 2 (Triplet Generation): (query, positive, negative) 샘플을 생성하되, negative는 4단계 유사도 수준으로 정렬. (예: High → Medium → Medium-low → Low)
- Curriculum 학습: 학습 과정에서 쉬운 negative부터 점점 어려운 negative로 훈련.
1
2
3
4
5
6
7
8
9
10
{
"query": "QUERY_TEXT",
"positive_example": "POSITIVE_EXAMPLE_TEXT",
"hard_negative_examples": [
{"similarity_level": "high", "text": "..."},
{"similarity_level": "medium", "text": "..."},
{"similarity_level": "medium", "text": "..."},
{"similarity_level": "low", "text": "..."}
]
}
3.2 ATA Pooling
- Attention Matrix에서 anchor token을 감지하고, 가중치 재분배.
- Anchor weight 계산 공식:
- 핵심은 anchor token(정보가 집약된 토큰) 을 강조해 문장 벡터 생성.
4. 실험
4.1 데이터
- Synthetic data: GPT-4o + DeepSeek-V2로 생성, 총 180M 토큰 소모 (비용 한계 때문에).
- Retrieval dataset: 공개 데이터셋 (약 150만 쌍, 다국어 포함).
4.2 모델 세팅
- Base model: Mistral-7B-Instruct-v0.2 → causal attention → bidirectional 변환.
- 학습: InfoNCE loss, 배치 크기 64, gradient accumulation 8, H100 GPU에서 32시간.
4.3 성능 평가
- MTEB benchmark (56개 task, classification/retrieval/STS 등 포함).
결과:
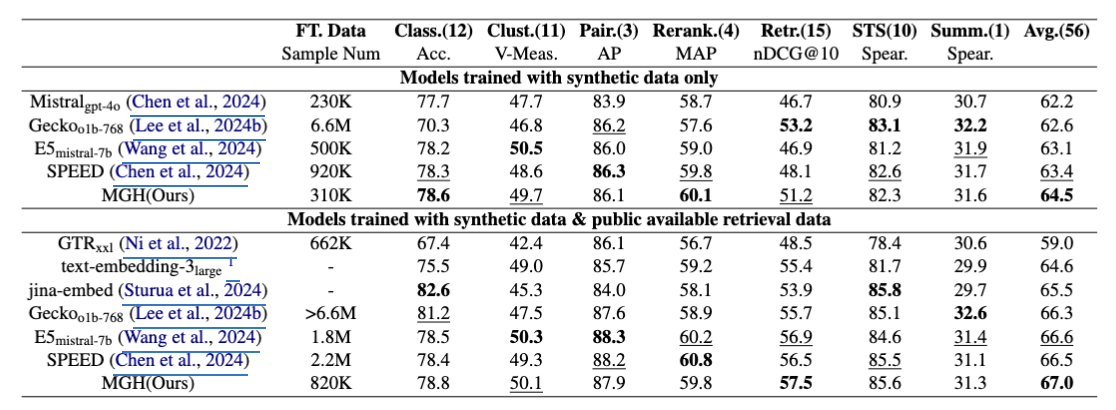
- MGH(Ours) 가 synthetic-only, full-data setting 모두에서 상위권.
- 합성 데이터만 사용한 경우
- MGH(본 논문 제안 기법)은 평균 점수 64.5로 가장 높음
- 특히, Rerank에서 두드러진 성능을 보임.
- 합성 + 공개 검색 데이터 함께 사용 시
- MGH는 67.0으로 최고점을 기록, 이전 최고 모델들보다 미세하게 우월함.
- 검색(Retr.) 태스크에서는 MGH가 57.5로 가장 우수
- MGH는 상대적으로 적은 샘플 수(310K 또는 820K)로도 높은 성능을 달성, 효율성도 같이 강조.
5. 분석 및 Ablation
5.1 Curriculum Learning 효과
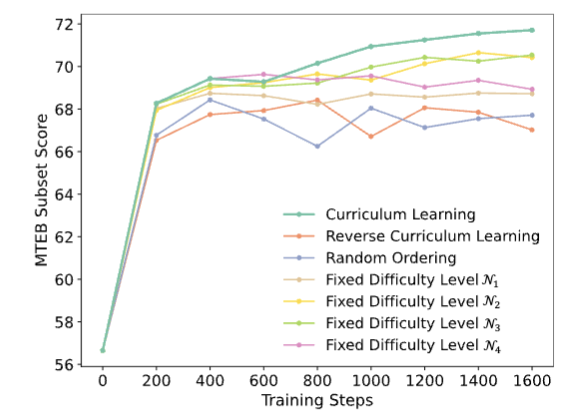
- Negative 난이도별 순차 학습이 성능/안정성 모두 최고.
- Random, Reverse curriculum, Fixed 난이도 모두 성능 저하.
5.2 Pooling 비교
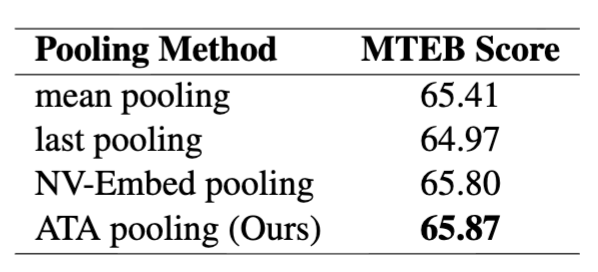
- ATA가 가장 좋은 성능
5.3 Negative 샘플 난이도 분석

- 난이도가 높을수록 query와 더 유사 → 의도한 coarse-to-fine 구조 검증.
5.4 Case Study

- Query: “Sodium의 라틴어 이름은?”
- Positive: Natrium → Na 기호 유래.
- Hard negatives:
- N1: Kalium (K 기호) → 매우 헷갈림.
- N2: 잘못된 Sod 유래.
- N3: Hydrogenium.
- N4: Sodium의 일반적 용도 설명.
6. 결론 및 한계
- 결론:
- MGH → hard negative를 난이도별로 생성, curriculum learning 효과 검증.
- ATA → anchor token 기반 pooling으로 추가 성능 향상.
- MTEB에서 state-of-the-art 달성.
- 한계:
- Synthetic data 규모 제한 (180M 토큰). 더 큰 데이터 실험은 못함.
핵심 인사이트
- 단순히 hard negative를 “생성”하는 수준을 넘어서, 난이도별 구조화 가 성능 안정성에 결정적. → 이를 curriculum learning에 활용
- Pooling 개선도 추가 파라미터 없는 lightweight 방식으로 성능 향상을 보여 의미 있음.
- 특히 retrieval task에서 SOTA를 달성.
This post is licensed under CC BY 4.0 by the author.