OG-RAG: Ontology-Grounded Retrieval-Augmented Generation for Large Language Models
OG-RAG: Ontology-Grounded Retrieval-Augmented Generation for Large Language Models
Written by. Kartik Sharma, Peeyush Kumar, Yunqing Li
1. 연구 배경
LLM 한계
대규모 언어 모델(LLM)은 일반 지식에는 강하지만, 산업/전문 분야(농업, 의료, 법률 등)에서는
- 잘못된 정보(환각, hallucination)를 생성
- 기존 LLM은 질문응답, 검색 등 다양한 작업에 사용되지만, 특정 산업의 워크플로우나 전문 지식에 적응하는 데 한계가 있음.
- 예: 농업에서 토양 상태나 지역별 식물 요구 조건을 반영하지 못해 잘못된 관개 계획을 제안할 수 있음 .
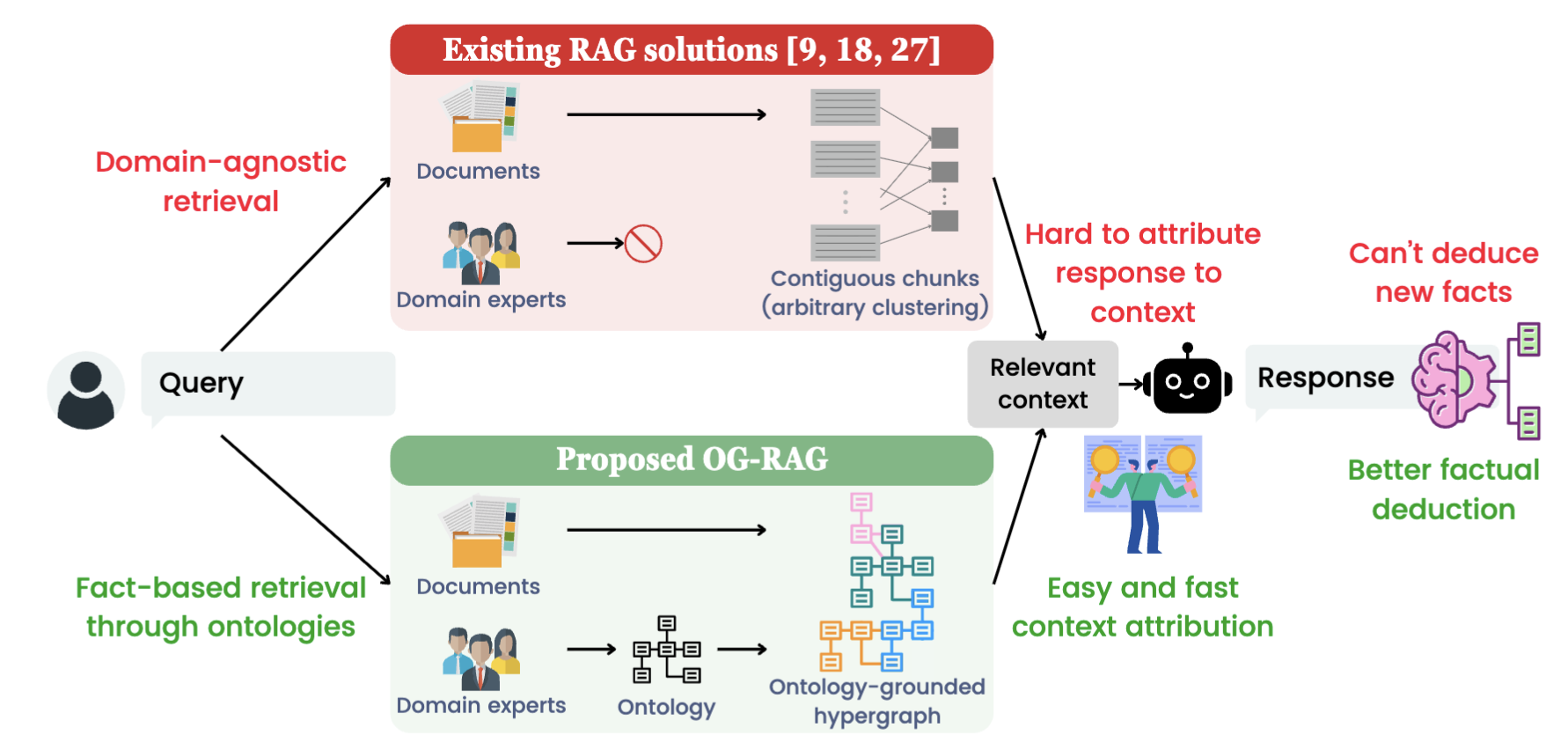
기존 해결책의 한계
- Fine-tuning: 비용이 크고 데이터 요구량이 많음
- 기존 RAG (Retrieval-Augmented Generation): 문서를 검색해 문맥으로 주지만,
- 구조화 부족 → 지식 관계 반영 어려움
- 응답 근거 추적이 어려움
2. OG-RAG 개념
- 온톨로지는 도메인 내 개체와 관계를 구조적으로 정의하여, 복잡한 지식과 관계를 체계적으로 표현함.
- OG-RAG는 온톨로지 기반 하이퍼그래프를 구축해, LLM이 정확하고 개념적으로 근거 있는 맥락을 활용하도록 함.
- 알고리즘 순서:
- 문서 → 온톨로지 매핑 → 하이퍼그래프 구성 → 최적 컨텍스트 검색 → LLM 응답 생성
3. OG-RAG
① 온톨로지 정의
- 온톨로지(Ontology): 특정 도메인의 개체(Entity), 속성(Attribute), 관계(Relation)를 체계적으로 정리한 지식 구조.
예 (농업):
1 2 3
(Crop, name, Soybean) (Crop, growing_zone, Madhya Pradesh) (Crop, seed_variety, JS 335)
- 틀 정의
- 농업(Agriculture): AI가 초안을 만들고, 전문가가 검수·수정
- 뉴스(News): 기존 SNaP(Simple News and Press Ontology) ontology를 가져와 불필요한 속성 제거 후 사용
! 결국 사람이 정의하거나 기존 틀을 가공하는 형태
② 문서 → 온톨로지 매핑
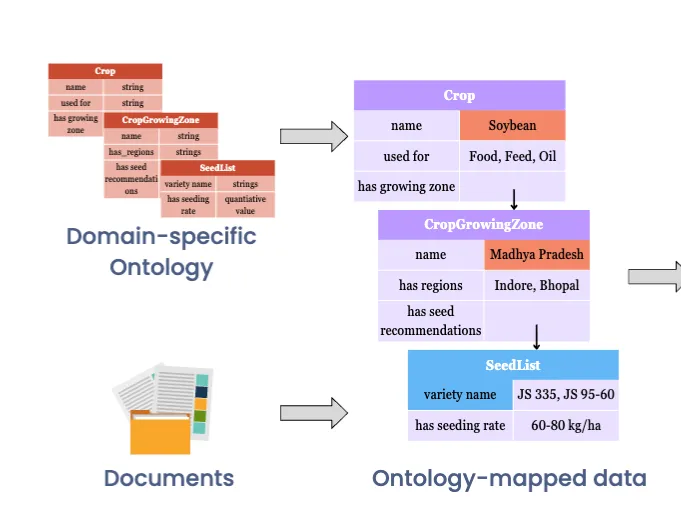
- 문서 속 텍스트를 온톨로지 구조에 맞게 변환
- 방법
- LLM 기반 추출 → 문서를 읽고 JSON-LD로 구조화
논문이 제시한 프롬프트:
1 2 3 4 5 6 7 8
Here is a context definition for wheat crop cultivation ontology. Context Definition: {ontology schema} ––––––––- Generate a JSON-LD using the following data and the above context definition for crop cultivation ontology. Use ‘@graph’ object namespace for the data in JSON-LD. Be comprehensive and make sure to fill all of the data. ...- 온톨로지 구조(개체·속성 정의)를 LLM에 제공하고, LLM이 문서의 텍스트를 읽어서 그 구조에 맞는 JSON-LD 형태의 데이터를 생성.
예시 (문장 → 구조화): “Soybean is cultivated in Madhya Pradesh, and the recommended variety is JS 335.”
1 2 3 4 5
{ "Crop": "Soybean", "GrowingZone": "Madhya Pradesh", "SeedList": ["JS 335"] }
③ 하이퍼그래프(Hypergraph) 생성
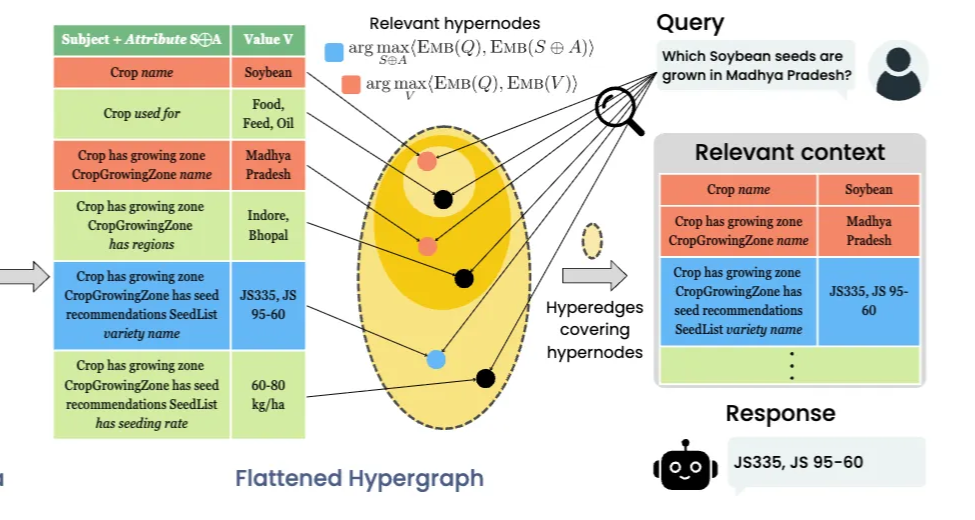
- 단순 그래프와 달리, 여러 개체를 동시에 연결 가능
- 하이퍼노드: (속성, 값) 쌍
- 예: (Crop⊕name, Soybean)
- 하이퍼엣지: 관련된 하이퍼노드들의 집합
- 예: {Soybean, Madhya Pradesh, JS 335}
- 하이퍼엣지 구성 방법
- 기본 아이디어
- 하이퍼엣지(hyperedge) = 여러 개체·속성이 서로 연결된 하나의 fact cluster
- 일반 그래프는 두 노드만 연결 가능하지만, 하이퍼엣지는 세 개 이상 노드도 동시에 연결 가능.
- OG-RAG에서는 문서에서 뽑아낸 ontology-mapped data (factual blocks)를 flatten해서 하이퍼엣지로 만듬.
- 온톨로지-문서 매핑 결과
- 예시) “Soybean은 Madhya Pradesh에서 재배되며, 추천 품종은 JS 335이고 파종량은 60–80 kg/ha이다.”
- 이 문장을 온톨로지 틀에 맞춰 다음과 같은 JSON-LD 형태로 LLM이 생성:
1 2 3 4 5 6 7 8
{ "Crop": "Soybean", "GrowingZone": "Madhya Pradesh", "SeedList": { "Variety": "JS 335", "SeedingRate": "60-80 kg/ha" } }
- Flattening
- 이 JSON 구조는 중첩되어 있어서 그대로 쓰기 어려움
따라서 FLATTEN 알고리즘을 통해 중첩 구조를 키-값 쌍으로 flatten
Algorithm 1: FLATTEN(F)
- 입력: F = factual block (온톨로지 기반 JSON 데이터)
- 출력: 평탄화된 key-value 쌍 집합
- F의 (s, a, v)를 읽음 (s=subject, a=attribute, v=value)
- 만약 v가 nested 구조라면 → 재귀 호출
- v가 raw 값이면 → (s⊕a, v) 쌍을 생성
- 모든 쌍을 모아 hypernode 집합 반환
1 2 3 4
(Crop⊕name, Soybean) (Crop⊕growing_zone⊕name, Madhya Pradesh) (Crop⊕growing_zone⊕seed_variety, JS 335) (Crop⊕growing_zone⊕seeding_rate, 60-80 kg/ha)
- 하이퍼노드 & 하이퍼엣지 구성
- 하이퍼노드 (hypernode):
(속성 경로, 값)형태- 예:
(Crop⊕name, Soybean)
- 예:
하이퍼엣지 (hyperedge): 여러 하이퍼노드를 묶어 표현한 하나의 사실 단위
1 2 3 4 5 6
e1 = { (Crop⊕name, Soybean), (Crop⊕growing_zone⊕name, Madhya Pradesh), (Crop⊕growing_zone⊕seed_variety, JS 335), (Crop⊕growing_zone⊕seeding_rate, 60-80 kg/ha) }- 즉, e1이라는 하이퍼엣지는 “Soybean ↔ Madhya Pradesh ↔ JS 335 ↔ 60–80 kg/ha”라는 연결된 사실 집합을 표현.
- 하이퍼노드 (hypernode):
- 기본 아이디어
④ 질의 기반 검색 (OG-RETRIEVE)
- 관련 하이퍼노드 식별:
- 주어진 쿼리에 관련된 하이퍼노드 집합을 먼저 식별.
- 하이퍼노드는 키-값 쌍으로 표현되며, 쿼리가 용어의 속성(s)과 관련되거나 특정 값(v)을 가진 객체에 초점을 맞출 때 관련성이 있다고 간주.
- OG-RAG는 쿼리 관련 하이퍼노드 두 세트 탐색:
- NS(Q): 속성 용어(s⊕a)와 쿼리 Q 간의 유사성이 가장 높은 상위 k개 하이퍼노드.
- NV(Q): 값(v)과 쿼리 Q 간의 유사성이 가장 높은 상위 k개 하이퍼노드.
- 따라서 각 쿼리에 대해 2k개의 관련 하이퍼노드를 추출.
- 관련 하이퍼엣지를 컨텍스트로 형성:
- 관련 컨텍스트는 관련 하이퍼노드 N(Q) = NS(Q) ∪ NV(Q)를 최소한으로 포함하는 하이퍼엣지 집합을 greedy algorithm으로 품.
- 각 반복에서, 아직 커버되지 않은 가장 많은 노드를 커버하는 하이퍼엣지를 컨텍스트에 추가하고, 해당 노드들은 추가 고려 대상에서 제외.
- 이 과정은 L개의 하이퍼엣지를 얻거나 모든 관련 노드가 커버될 때까지 반복.
- Set Cover 문제: 보통 greedy는 근사(approximation)
- Matroid 구조: 특정한 조건에서는 greedy로 풀어도 최적 보장
- OG-RAG: 하이퍼엣지 선택 문제를 matroid로 모델링 → greedy 선택으로 최적성 확보
- 이러한 방식으로 컨텍스트는 주어진 쿼리와 관련된 최대 L개의 하이퍼엣지 컬렉션으로 구성.
- 하이퍼엣지로 정보를 조직함으로써 OG-RAG는 관련 사실들을 함께 그룹화하여 검색된 컨텍스트가 압축적이면서도 포괄적이도록 보장.
- 이는 정확한 LLM응답을 지원하는 데 필요한 모든 사실을 포착하면서 효율성을 최적화.
- 관련 컨텍스트는 관련 하이퍼노드 N(Q) = NS(Q) ∪ NV(Q)를 최소한으로 포함하는 하이퍼엣지 집합을 greedy algorithm으로 품.
- 검색 증강 생성 (Retrieval-Augmented Generation):
- 사용자 쿼리 Q와 위에서 찾은 관련 컨텍스트 CH(Q)가 주어지면, LLMM은 이 컨텍스트를 사용하여 쿼리에 답변하도록 프롬프트.
4. 실험 및 결과
비교 대상 & 평가 지표
- 비교 대상:
- RAG (기본)
- RAPTOR (트리 기반)
- GraphRAG (그래프 기반)
- OG-RAG (제안 기법)
- 평가 지표 :
- C-Rec (Context Recall)
- 정의
- 검색된 컨텍스트(LLM에게 제공된 문맥) 안에, 실제로 정답에 필요한 사실(fact)이 얼마나 포함되었는지를 측정.
- 검색이 필요한 정보를 잘 가져왔는가?
계산 방식
\[C\text{-}Rec = \frac{\text{검색 컨텍스트에 포함된 정답 fact 개수}}{\text{전체 정답 fact 개수}}\]
- 정의
- C-ERec (Context Entity Recall)
- 정의
- C-Rec의 특수 버전으로, 정답에 필요한 엔티티(Entity)만 추적.
- 정답에 등장하는 특정 엔티티들이 검색 컨텍스트에 얼마나 포함되었는가?
계산 방식
\[C\text{-}ERec = \frac{\text{검색 컨텍스트에 포함된 정답 엔티티 개수}}{\text{전체 정답 엔티티 개수}}\]
- 정의
- A-Corr (Answer Correctness)
- 정의
- LLM이 생성한 최종 답변이 정답과 얼마나 일치하는지를 F1-score로 측정.
- 계산 방식
- F1 score
- 정의
- A-Sim (Answer Similarity)
- 정의
- 답변과 정답의 의미적 유사도를 평가.
- 문자열이 다르더라도, 의미가 같으면 높은 점수를 부여.
- 계산 방식
- embedding similarity
- 정의
- A-Rel (Answer Relevance)
- 정의
- 답변이 질문(Query)와 얼마나 관련 있는지를 평가.
- 단순 일치가 아니라, 답변이 질문 의도를 충족하는지 (추론 포함).
- 측정 방식
- 임베딩 기반 유사도 + 사람 평가(human judgment)를 혼합
- 특히 multi-hop reasoning 상황에서 중요
- 정의
- C-Rec (Context Recall)
실험 데이터셋
- 농업 도메인: Soybean, Wheat (85개 문서, 인도 작물 재배 매뉴얼)
- 뉴스 도메인: Multi-hop RAG 데이터셋에서 149개 기사
결과
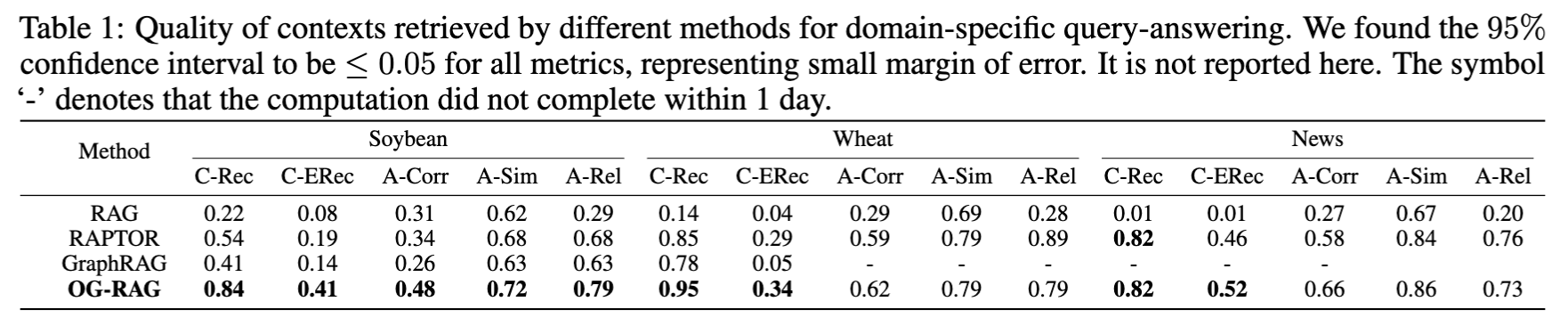
- OG-RAG은 C-Rec, C-ERec에서 큰 향상 → RAG 대비 정확한 사실 Recall +55%, 엔티티 Recall +110%
Answer 품질 비교
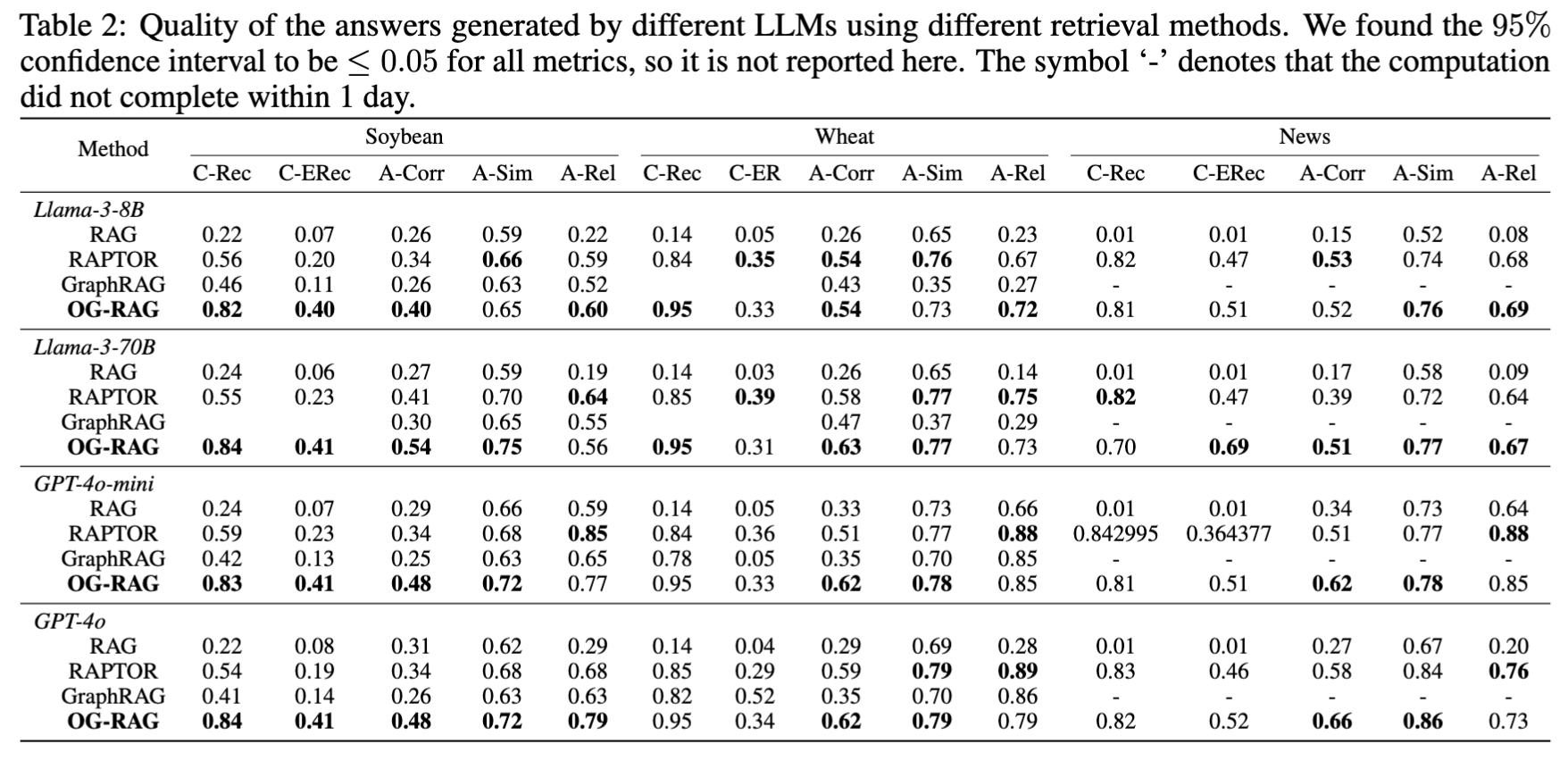
- OG-RAG이 정답 정확도(A-Corr) 평균 +40% 개선, 관련성(A-Rel)도 +16% 개선
- 단, 일부 경우(예: Wheat/GPT-4o)에서는 broader context로 인해 relevance가 살짝 낮음.
- greedy로 노드를 가장 많이 포함한 하이퍼 엣지를 고르다보니 엄청 나게 많은 정보를 가진 엣지를 선택할 위험이 있고 이것때문인듯…
효율성 비교
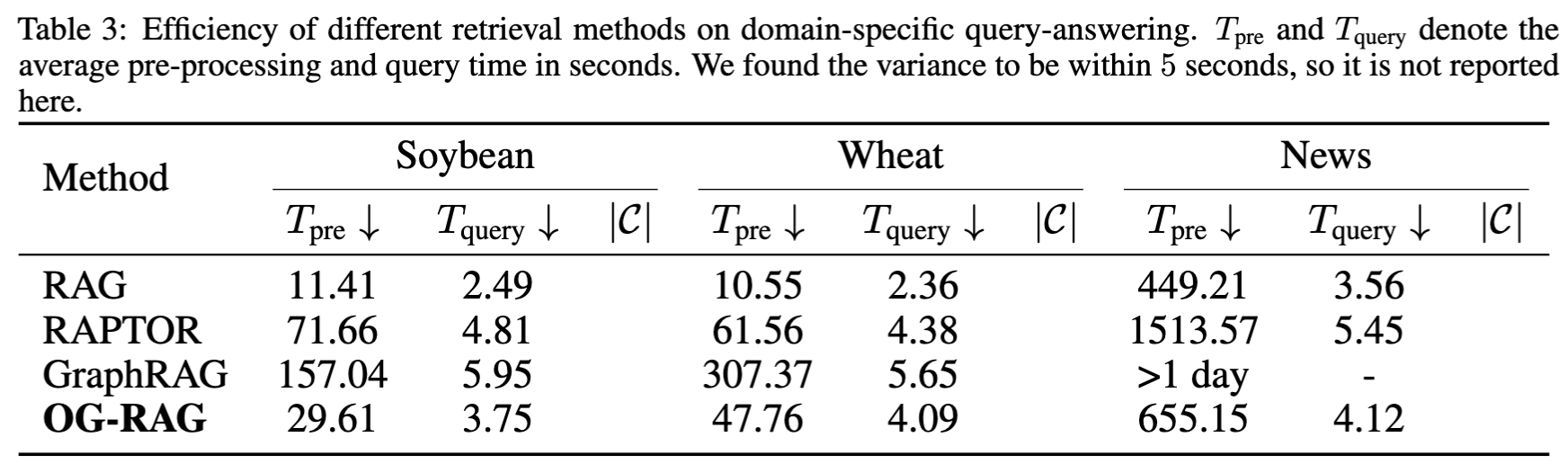
- OG-RAG은 RAG보다 쿼리당 평균 2초 정도만 느림, 그러나 RAPTOR/GraphRAG보다 훨씬 효율적
Context Attribution, 사용자 실험

- 사람이 답변의 근거를 추적하는 데 걸린 시간:
- RAG: 평균 61.15초
- OG-RAG: 평균 43.50초 (약 30% 빨라짐)
- 근거 적합성 점수(1~5):
- RAG: 2.67
- OG-RAG: 3.46
- 사람이 했을 때도 추론하기 더 적합한 정보를 제공해주는 거 같음.
5. 논문의 기여
온톨로지-하이퍼그래프 통합
→ 도메인 지식을 구조화하여 LLM에 제공
사실 기반 추론 강화
→ 단순 검색이 아니라, 여러 사실을 연결해 새로운 결론 유도
빠르고 정확한 근거 추적
→ 사용자가 LLM 답변의 출처를 쉽게 확인 가능
6. 한계와 Future Work
- 온톨로지 틀을 항상 사람이 정의해야 함 → 완전 자동화 필요
- 현재는 농업·뉴스 도메인만 검증
- 향후 자동 온톨로지 학습 기법 개발로 다양한 도메인 적용 가능
This post is licensed under CC BY 4.0 by the author.