RzenEmbed: Towards Comprehensive Multimodal Retrieval
Written By. Weijian Jian, Yajun Zhang, Dawei Liang, Chunyu Xie, Yixiao He, Dawei Leng, Yuhui Yin
1. 문제정의
목표
이 논문이 풀려는 핵심 목표는 텍스트, 이미지, 비디오, 시각 문서(visual document)까지 아우르는 multimodal universal 임베딩을 학습해서, 다양한 멀티모달 검색/리트리벌 태스크에서 하나의 모델/임베딩 공간으로 좋은 성능을 내는 것.
기존 한계
기존 CLIP 계열/확장 방식이나 최근 MLLM 기반 임베딩들은 성능이 좋아졌지만, 주로 자연 이미지-텍스트에 집중되어 있고, 비디오(시간축)나 문서(레이아웃/구조) 같은 시각 모달리티에 대한 지원이 약하다고 지적. 그 결과 비디오/문서 검색에서 성능이 떨어지며 범용 시스템 구축을 막는다고 설명.
학습 관점의 한계점
- False negative / Hard negative 문제
- 배치 내에서 의미적으로 비슷한 샘플이 false negative가 존재한다면, 모델이 좋은 유사성을 벌점 주게 되어 학습이 망가짐.
- 반대로 쉬운 negative가 너무 많으면, 모델이 hard negative로부터 세밀한 차이를 배우지 못함.
- temperature τ를 고정/공유하는 문제
- 태스크마다 최적 스케일이 다른데(문서처럼 미세 구분이 필요한 태스크는 sharper 분포가 필요할 수 있음), 보통 τ를 고정하거나 공유해 비효율이 생김.
- 임베딩 프롬프트 설계의 영향
- MLLM 기반일수록 프롬프트가 임베딩 품질에 큰 영향을 주는데, 관련 전략이 없음.
2. Method
논문 기여는 한 줄로 요약하면:
Qwen2-VL 기반의 멀티모달 임베더를 만들되, 2-stage 학습 개선된 InfoNCE(false negative 제거 + hard negative 가중치) 테스크별 learnable temperature 임베딩 프롬프트 LoRA model souping 로 범용 검색 성능을 끌어올린 프레임워크입
2.1 아키텍처
백본: Qwen2-VL
아래의 이유로 선택했다고함.:
- 범용 임베딩을 위해 텍스트/이미지/비디오를 유연하게 처리
- 긴 컨텍스트도 다루기 가능
- 다양한 해상도 처리(Native Dynamic Resolution)
- 비디오 시간특성 처리를 돕는 멀티모달 RoPE(M-RoPE)
- instruction following에 대해 학습이 잘되어 있음(MLLM의 장점)
입력 형태
- Visual input: 이미지 또는 비디오(비디오는 일정 간격으로 프레임 샘플링)
- Text input: Instruction + Text 구조(태스크 지시 + 내용)
임베딩 추출 방식: EOS 마지막 토큰 hidden state
마지막 토큰(EOS)의 마지막 hidden state를 임베딩 벡터로 사용
2.2 Loss: InfoNCE 기반 + 2가지 핵심 개선
기본은 contrastive learning의 InfoNCE
논문은 표준 InfoNCE가 실전에서 두 가지 한계가 있다고 말함:
- false negative에 의한 노이즈 존재
- easy negative가 대다수라 세밀한 학습이 되기 힘듬
이를 해결하기 위해 아래 두 장치를 도입.
(A) False Negative Mitigation: Positive와 너무 비슷한 Negative 제거
NVRetriver의 PercPos를 인배치에 적용한 것 같음.
(B) Hardness-Weighted Strategy: hard negative의 기여를 키우기
negative 샘플을 동일 취급하지 않고, 쿼리와 더 비슷한(=더 어려운) negative일수록 가중치를 크게 줌.
- 가중치: $w_i = \exp(\alpha \cdot sim(q, k_i^-))$
- easy negaitve은 이미 잘 구분하니 학습 신호 약함 → 어려운 네거티브 데이터에 더 집중하도록 학습
2.3 전체 학습: 2-Stage Training
논문은 학습을 두 단계로 나눔.
Stage 1: Multimodal Continual Training - 기초 임베딩 능력 구축
이 단계의 목표는 기본적인 임베딩/정렬 능력을 심는 것. 여기서는 instruction fine-tuning을 의도적으로 피한다고 명시.
데이터를 3종으로 구성.
- Unimodal (T→T): 텍스트 검색(예: MS-MARCO, NQ, HotpotQA, TriviaQA 등)
- Cross-modal
- T→I: LAION의 텍스트-이미지
- LAION 캡션 품질을 높이기 위해 CogVLM-19B로 recaptioning해 더 길고 세밀한 설명을 만들고, 이것이 정렬 강화 + 노이즈 제거 역할을 한다고 설명.
- T→VD: 텍스트-비디오 설명(ShareGPT4V) → 이건 현재 우리에겐 필요없음
- T→I: LAION의 텍스트-이미지
- Fused-modal (IT→I): 이미지+차이 설명 텍스트 → 타겟 이미지 (MegaPairs)
- 입력: source image / difference description (텍스트)
- 출력: target image
- 예: 이미지 A: 빨간 자동차 / 텍스트: “same car but blue” / 정답: 파란 자동차 이미지
마지막으로 공개 데이터는 중복/노이즈/저품질 이미지를 정리하는 클리닝을 수행. → 다른 일반적 논문들처럼 구체적 방법은 공개 안함
- 중복 제거 / 노이즈 제거
- blurry / corrupted / low-res 이미지 제거
Stage 2: Fine-Tuning - 다양한 시나리오/인스트럭션에 적응
여기서는 instruction-formatted 데이터를 섞어 복잡한 태스크/시나리오 학습.
- MMEB-v2 train set + 여러 공개 멀티모달 retrieval/QA 데이터로 구성
- 배치 구성은 중요한 포인트:
- (분류 제외) 배치 하나가 단일 데이터셋에서만 샘플되도록 해서, 배치 안에 hard negative가 더 “농축”되게 만들었다고 함 → 다른 테스크가 같은 배치에 있으면 easy negative가 될 확률이 높아서 그런듯
이 단계에서 커버하는 태스크 범위:
- 이미지: 분류, QA(객관식/주관식), retrieval, grounding
- 시각문서(VisDoc): 시각 문서 검색
- 비디오: 비디오 retrieval, moment retrieval, 비디오 분류, 비디오 QA
각 데이터셋은 overfitting 방지를 위해 10만 샘플로 제한.
비디오/분류에서의 Stage 2의 추가 데이터 전략 2가지 - 현재엔 무시해도됨
- 이미지 분류 데이터셋 병합
- 분류 데이터셋은 클래스 수가 작아(similarity matrix 구성 시) false negative가 대량으로 생기기 쉬우므로, 여러 분류 데이터셋을 하나로 합친 새 데이터셋을 만들어 false negative를 줄입니다.
- 비디오 데이터 난이도 상승
- MMEB-v2 비디오가 짧고 프레임 유사도가 높아 “쉽다”고 보고,
- 긴 비디오를 여러 클립으로 분할해 같은 원본에서 나온 클립끼리 자연스럽게 hard negative가 되게 함
- 1–3분짜리 롱폼 비디오와 전체 설명을 추가해 장기 시간 의존/전역 문맥을 학습시킴
2.4 Task-Specific Learnable Temperature - τ를 테스크별로 학습
InfoNCE의 τ는 보통 수동 튜닝인데, 논문은 이를 학습 가능한 값으로 바꾸고, 더 나아가 태스크별 τ_t를 둠. 태스크 7개: 이미지 분류, 이미지 QA, 이미지 검색, grounding, 문서 검색, 비디오 검색, 비디오 QA
- 양수 제약을 위해 re-parameterization: $\tau_t = \exp(\theta_t)$
2.5 Embedding Prompt - Generative MLLM을 Discriminative Embedder로
Qwen2-VL은 생성형으로 사전학습된 백본이라 그대로 contrastive에 쓰면 성능 다운됨. 이를 프롬프트로 교정.
시스템 프롬프트: 아마 EOS 토큰을 쓰므로 하나의 단어로 의미를 압축하려고한듯? (토큰은 아니고 word임)
Given an image, summarize the provided image in one word. Given only text, describe the text in one word
representation prompt:
- 텍스트 쿼리: “Represent the given text in one word.”
- 멀티모달 쿼리: “Represent the given image in one word.”
학습 입력은 아래와 같은 구성:
<system prompt> <query> <representation prompt>
2.6 Model Souping - LoRA 어댑터 평균
여러 LoRA 어댑터를 태스크별로 따로 쓰는 대신, 여러 LoRA의 low-rank weight를 가중 결합/융합해서 하나의 평균적인 값을 가지는 LoRA로 만든 뒤 base model에 합쳐 단일 모델로 배포하는 접근 목적은:
- 서로 보완적인 지식을 합쳐 성능/안정성 개선
- 여러 어댑터를 따로 유지하는 오버헤드 감소
3. 실험
3.1 학습 데이터 규모/구성
학습은 2단계로 진행되며,
- 1단계: 총 5M 엔트리로 기초 임베딩 능력
- 텍스트 검색 데이터 약 30만
- LAION-2B에서 200만(원본+CogVLM 생성 캡션 포함)
- MegaPairs에서 250만
- 2단계: MMEB v2 train 중심 + mmE5-synthetic + VideoChatFlash에서 40만 비디오 클립 추가
3.2 학습 설정 - 하이퍼파라미터/인프라
- AdamW, 1 epoch fine-tuning
- LoRA를 비전 인코더와 LLM의 모든 linear layer에 적용, rank=64
- lr 2e-4 cosine decay, global batch size 768, weight decay 5e-2
- hardness 가중치 계수 α=9, false negative threshold δ=0.95
- 이미지/비디오 최대 입력 토큰 1280, bf16 + grad checkpointing
- 16× NVIDIA A800 80GB
3.3 메인 결과: MMEB-V1 / MMEB-V2
MMEB-V1 (기존 MMEB)
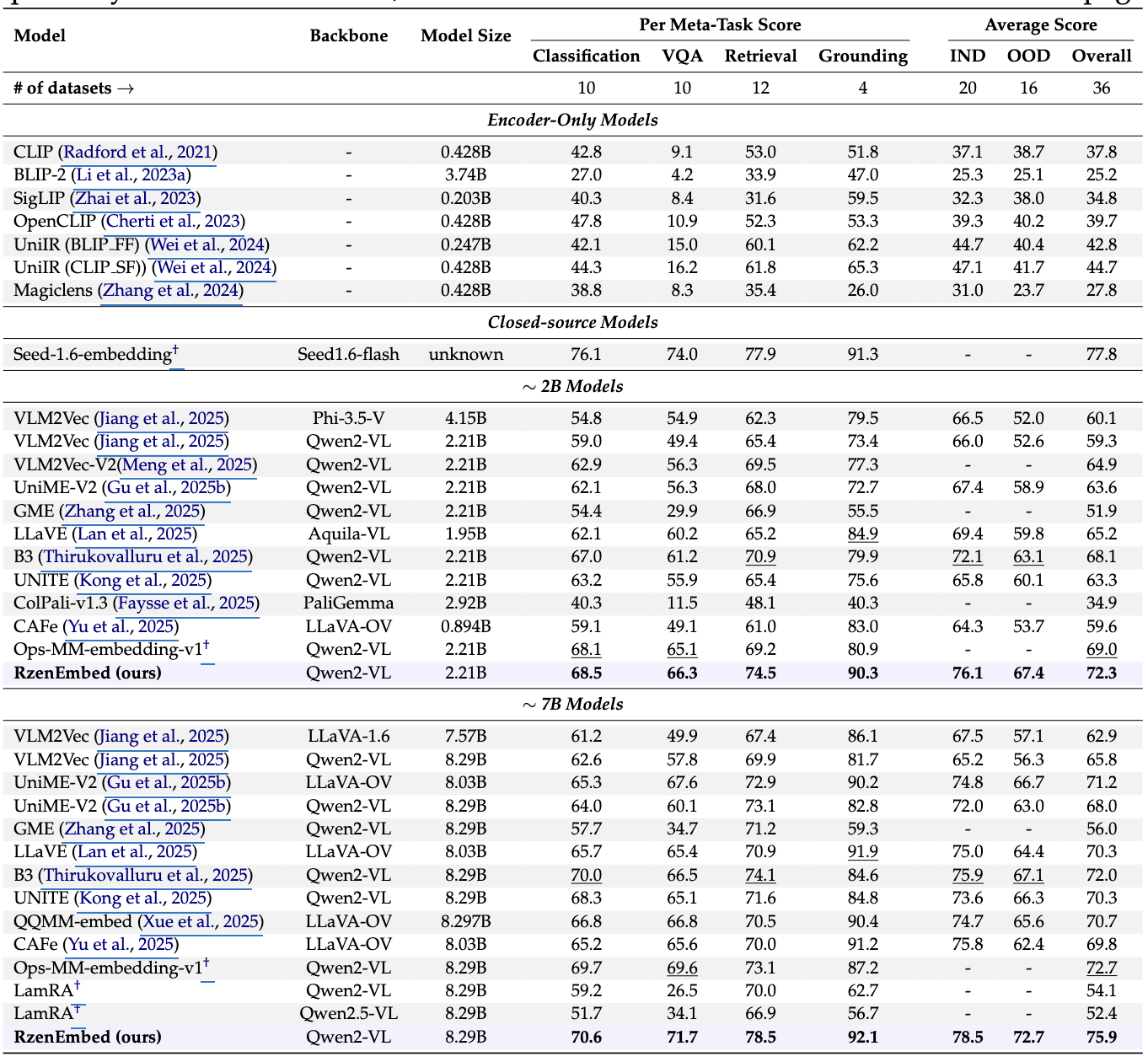
2B/7B 스케일 모두에서 강한 성능을 보고하며, 2.21B와 8.29B 모델 모두 높은 overall을 달성
MMEB-V2 (비디오/시각문서 강화 벤치)
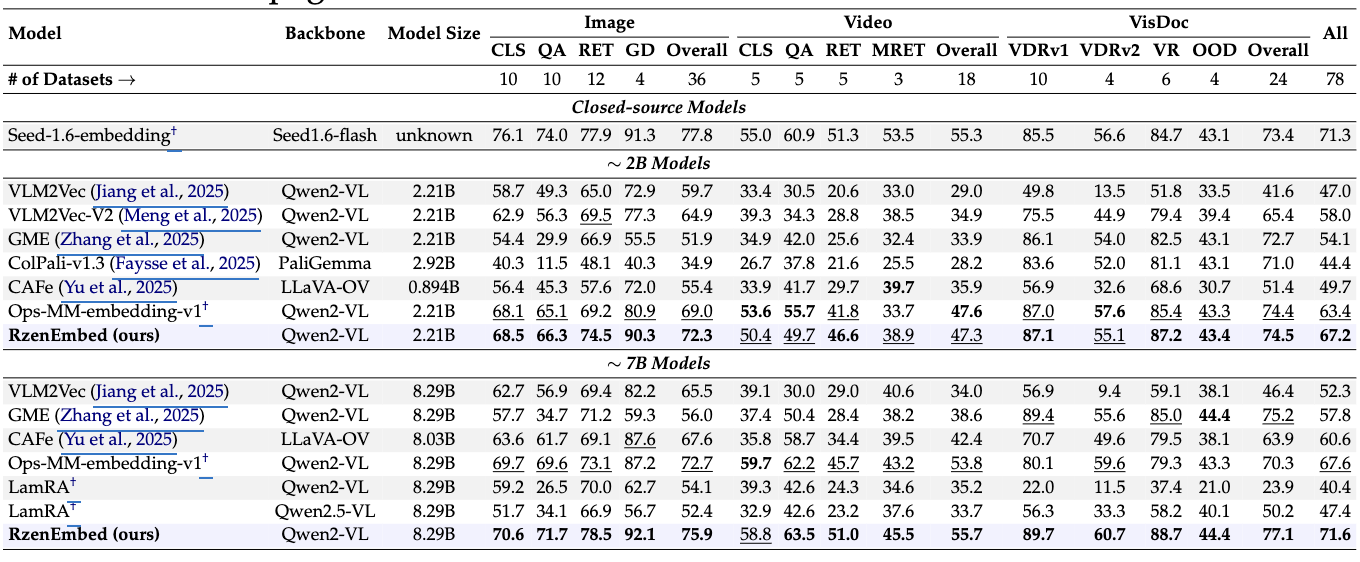
RzenEmbed가 이미지/비디오/시각문서 전반에서 우수하며, 같은 스케일의 다음 최고 모델 대비 2B는 +3.4%, 7B는 +4.0% overall 개선, 7B 모델이 closed-source Seed-1.6-embedding보다 Video/VisDoc 서브태스크에서 앞섬.
3.4 Ablation
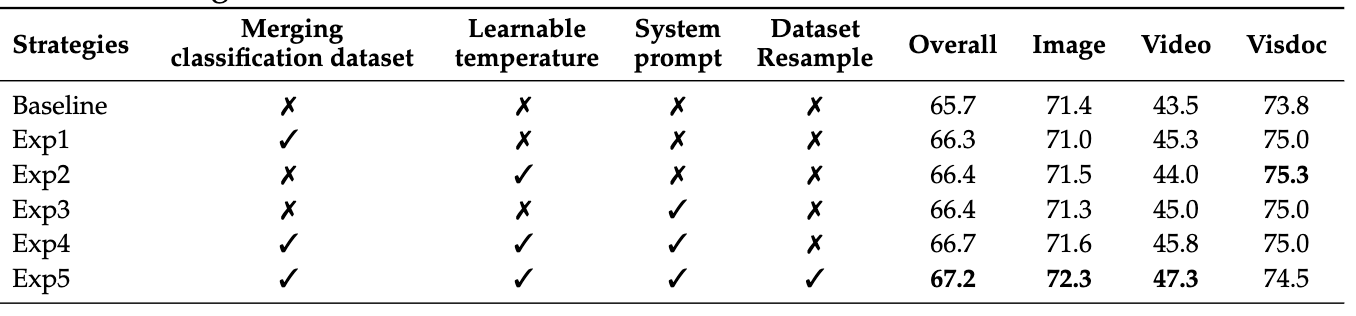
- 분류 데이터셋 병합(Exp1): overall 66.3, 특히 video/visdoc 개선
- learnable temperature(Exp2): overall 66.4, visdoc 75.3(표에서 가장 좋다고 설명)
- system prompt(Exp3): overall 66.4로 향상, 생성형→분별형 전환에 도움
- 프롬프트만 추가해서 학습해도 성능 많이 증가함
- dataset resampling 포함 전체 결합(Exp5): overall 67.2로 최고, 비디오 쪽이 더 빨리 수렴하는 불균형을 resampling으로 보정했다고 설명
- 문제 인식 : 비디오 태스크 loss가 너무 빨리 수렴
- 이미지/문서 태스크는 느리게 수렴
- → 전체 학습이 video 쪽에 끌려감
- 해결책: Dataset Resampling : 느리게 수렴하는 태스크(이미지 중심)를 더 자주 샘플링
- epoch는 동일하나 sampling probability만 조절
- 효과 : 각 태스크의 gradient 기여 균형, 전체 성능(특히 image/visdoc) 상승
- 문제 인식 : 비디오 태스크 loss가 너무 빨리 수렴
3.5 Model Souping 결과
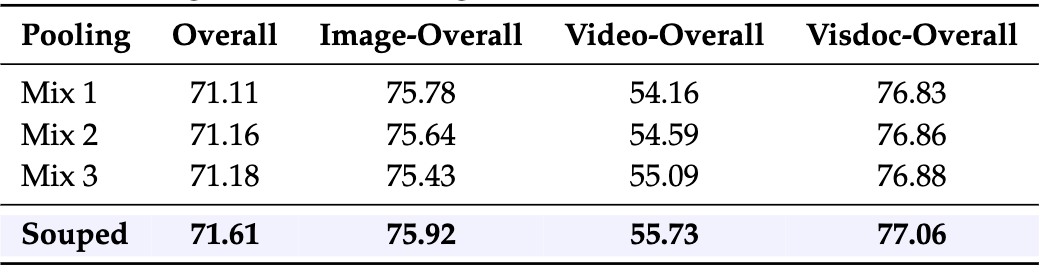
서로 다른 training mixture(또는 체크포인트/어댑터 조합으로 보이는 Mix1~3) 대비, Souped가 overall 71.61로 최고 성능을 보임.
4. 결론
논문 결론은 다음을 강조.
- 텍스트/이미지/비디오/시각문서까지 포괄하는 통합 임베딩 프레임워크 RzenEmbed 제안
- 성능 향상의 핵심은
- 2-stage 학습
- hardness-weighted InfoNCE + false negative mitigation
- learnable temperature, embedding prompt, model souping