SCAR: Data Selection via Style Consistency-Aware Response Ranking for Efficient Instruction-Tuning of Large Language Models
SCAR: Data Selection via Style Consistency-Aware Response Ranking for Efficient Instruction-Tuning of Large Language Models
Written by. Zhuang Li1, Yuncheng Hua2
1. 연구 배경과 문제의식
- 동기: 기존 연구는 적은 수의 고품질 데이터로도 대규모 데이터보다 성능이 더 좋을 수 있다고 밝혔지만, “스타일 일관성”의 정의가 데이터 품질에 영향을 미친다는 연구는 없었음.
- 핵심 아이디어: 훈련 데이터 내 응답 스타일의 일관성이 LLM 성능 향상에 결정적인 영향을 미친다는 점에 주목.
- 목표: 사람이 수작업으로 데이터를 큐레이션하지 않고도 스타일 일관성이 높은 데이터를 자동으로 선택하여 효과적인 SFT(supervised fine-tuning)를 구현.
2. 핵심 요소: 응답 스타일의 두 구성요소
SCAR가 주목하는 응답 스타일(style)은 두 가지 요소로 구성:
2.1. Linguistic Form (언어적 형식)
- 문법적 구조와 레이아웃을 중심으로 한 비의미적 요소들.
- 특징 예시:
- 문장 구조
- 기능어 사용 (예: 접속사, 전치사)
- 구두점 패턴
- 문단 나눔, 목록, 헤더 등
- GPT 기반 응답은 bullet point 등을 일관되게 사용하는 반면, 인간 응답은 다양성이 큼.
2.2 Instructional Surprisal (지시 기반 놀라움도)
- 주어진 instruction에 대해 응답이 얼마나 예측 가능한지를 측정.
- 예: “정렬 알고리즘을 설명하라” → GPT는 대부분 quicksort나 mergesort를 제시하지만, 인간은 때때로 StoogeSort나 독창적 해법 제시 → surprisal 높음
- 계산 방식:
- 언어모델 기반 perplexity(PPL): 낮을수록 예측 가능함
- 임베딩 기반 유사도: instruction과 응답 간의 의미적 거리
SCAR는 이 두 요소의 일관성(consistency) 을 기준으로 데이터를 선별.
3. SCAR 모델 개요
- 목적: 높은 스타일 일관성과 품질을 가진 instruction-response 쌍을 랭킹하여 선택.
- 핵심 기법:
- 신경망 기반 랭커: Linguistic form과 Instructional surprisal를 분리하여 벡터화 후 Multi-layer Perceptron으로 점수화.
- Triplet Loss: direct, referenced, human 응답 간 유사도 제약을 통해 학습 안정화.
- 품질 필터링: GPT 기반의 평가로 응답이 일정 수준 이상의 품질(도움됨, 정확성)을 가져야 랭킹 점수를 부여.
3.1 학습 데이터 구성
SCAR의 학습 데이터는 instruction에 대해 세 가지 응답이 포함된 집합:
- yd: direct 응답 (GPT가 직접 생성)
- yr: referenced 응답 (인간 응답을 GPT가 리라이팅)
- yh: 원본 인간 응답
3.2 랭킹 목적 함수:
직접 응답(direct) > referenced > 인간 응답(human) 이라는 우선 순위를 학습하도록 설계됨.
- 품질(quality) 측면에서는 인간 응답이 더 나은 경우도 있음
- SCAR도 이 점을 인정하지만(사람 응답이 내용적으로 더 정확하고 깊이 있는 경우가 많음)
- 하지만 style이 너무 다양해서 fine-tuning 시 모델이 헷갈릴 수 있음
- 학습 목표: 스타일 일관성 + 품질이 높은 응답에 더 높은 점수를 주도록 훈련
수식:
\[L_r = \sum_{(a,b) \in P} \max\left(0, \alpha - R_\theta(x,a) + R_\theta(x,b)\right)\]여기서 Rθ(x,y)는 응답의 style score, α는 마진.
- 조건부 품질 필터 f(x,y)>σ도 적용: 품질 낮은 응답은 무시함
- GPT-3.5나 GPT-4 같은 LLM에게 다음을 평가하게 함:
- Helpfulness (도움이 되었는가?)
- Correctness (사실이 맞는가?)
- 두 점수를 평균 → f(x,y)
- 기준치 σ는 실험마다 다르지만 일반적으로 2점 수준
- GPT-3.5나 GPT-4 같은 LLM에게 다음을 평가하게 함:
3.3 스타일 표현 분리 학습 (Disentangled Representation Learning)
SCAR는 style의 두 구성요소를 독립적으로 표현:
- vp (linguistic form vector): 응답 자체의 token 시퀀스에서 추출한 surface-level 표현
- vc (instructional surprisal vector): instruction-response 쌍을 MLP를 통해 의미적 연관도로 표현
결합된 표현:
\[R_\theta(x, y) = \text{MLP}_r\left([v_p; v_c]\right)\]Linguistic Form 벡터 vp 생성
\[\mathbf{v}_p = \text{MaxPool}(V_y)\]- 입력: 응답 y
- 사용 모델: RoBERTa-base 또는 CodeT5p
추출 방식: 응답의 토큰 임베딩을 max-pooling → 스타일 요소 추출
이 벡터는 구두점, 문장 길이, layout feature 등 응답의 표면적인 언어 스타일을 반영
Instructional Surprisal 벡터 vc 생성
\[\mathbf{v}_c = \text{MLP}_c\!\left(\left[ V_x^{[\text{CLS}]}; \, V_y^{[\text{CLS}]} \right]\right)\]- 입력: instruction x, 응답 y
- 사용 모델: RoBERTa-base 또는 다른 sentence encoder
- 처리 방식:
- 즉, instruction과 response 각각의 [CLS] 벡터를 concat → 또 다른 MLP로 통과
- 이 구조는 instruction과 응답의 의미적 유사도 / surprisal 수준을 학습하도록 설계
3.4 Representation Regularization (triplet loss)
- 학습 중 표현 공간에서의 구조를 유지하기 위해 다음과 같은 제약을 추가:
이 loss는:
- 언어적 형식은 direct와 referenced가 더 가까워야 함.
- surprisal은 human과 referenced가 더 가까워야 함.
- 즉, 구조적으로 의미 있는 분리 표현을 유지하도록 유도.
3.5 최종 선택 방식
- 훈련 완료 후 unseen 데이터셋에 대해 SCAR 점수 계산
- 상위 k% 예제만 추출하여 LLM fine-tuning에 사용
- 결과적으로 전체 데이터의 0.7~25%만으로도 전체 데이터보다 성능이 나음
4. 실험 결과
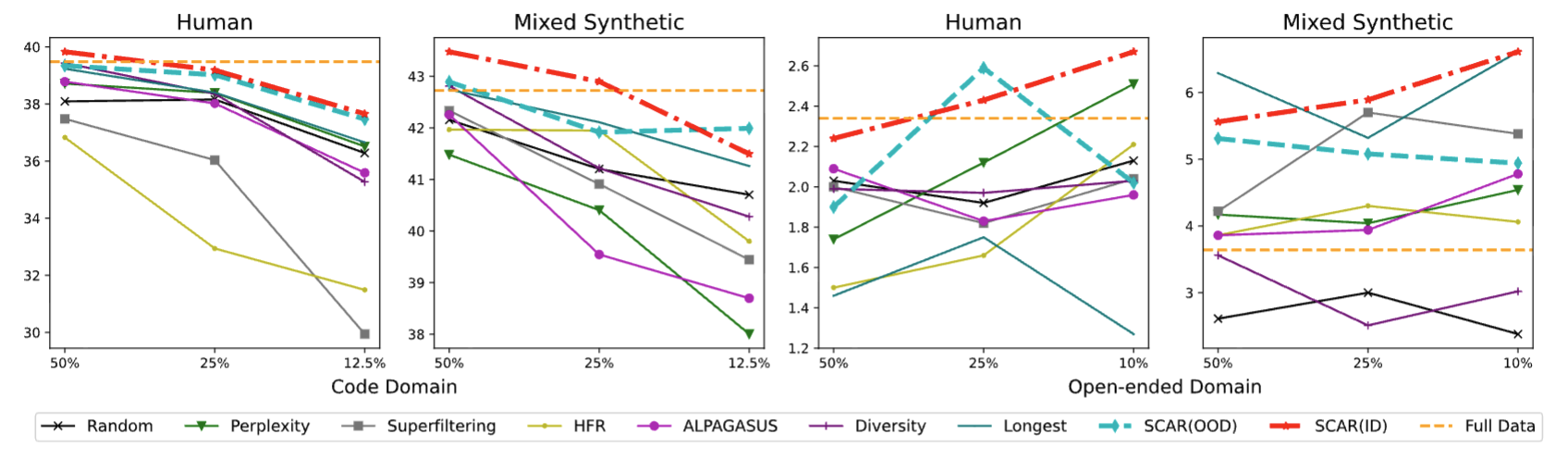
- 데이터 크기 축소 효과: 전체 데이터의 0.7%만 사용해도 풀셋과 동일하거나 더 나은 성능을 달성 (예: OLMO-7B, STARCODER-15.5B).
- 기존 방법과 비교 우위:
- SCAR는 RANDOM, PERPLEXITY, SUPERFILTERING, ALPAGASUS 등 다른 데이터 선택 기법보다 항상 우수하거나 동등한 성능을 보임.
- 코드 및 오픈 도메인 성능: HUMANEVAL, MULTIPL-E, ALPACAEVAL 등 다양한 벤치마크에서 우수한 결과.
5. 한계 및 고려사항
- 공정성 이슈: SCAR로 선택된 데이터가 일부 직업 및 인구 집단에 대한 편향을 줄이긴 했으나, 완전한 제거는 어려움.
- 어휘 다양성 감소: Type-Token Ratio가 낮아져 표면적 다양성은 줄어드나, MTLD 측면에서는 본질적인 어휘 깊이는 유지됨.
- 동일 LLM으로 생성된 스타일 일관 데이터에는 효과 제한: 예를 들어 GPT-3.5가 생성한 데이터만 있는 경우 SCAR의 효용성은 줄어듦.
6. 결론
- SCAR는 기존 데이터셋에서 고품질이고 스타일 일관된 소량의 예시만으로도 LLM을 효과적으로 fine-tune 할 수 있게 함.
- 데이터 수집·정제 비용을 대폭 줄이면서도 성능 저하 없이 instruction-tuning을 가능하게 하는 실용적 접근법임
This post is licensed under CC BY 4.0 by the author.