Smurfs: Multi-Agent System using Context-Efficient DFSDT for Tool Planning
Smurfs: Multi-Agent System using Context-Efficient DFSDT for Tool Planning
Written by. Junzhi Chen, Juhao Liang, Benyou Wang
1. 개요
Smurfs
- 대규모 언어 모델(LLM)이 외부 도구(tool)를 효과적으로 사용하여 복잡한 문제를 해결할 수 있도록 지원하는 다중 에이전트 시스템(Multi-Agent System, MAS)
- 기존의 DFSDT를 기반으로 하되, 그 단점을 극복하고 문맥 효율성과 안정성을 높인 구조를 가짐
2. DFSDT(Deep-First Search Decision Tree)란?
목적:
DFSDT는 LLM이 복잡한 다단계 문제를 툴을 이용해 풀기 위해 설계된 계획 프레임워크.
동작 방식:
- 문제 해결을 깊이 우선 탐색(DFS) 방식으로 수행
- 툴 사용이 실패하거나 잘못된 방향임을 인식하면 “롤백(rollback)” 하여 이전 상태로 돌아가 다른 해결 경로를 탐색
- Finish Tool이라는 특별한 툴을 통해 모델이 스스로 “문제를 끝냈다”고 판단
예시:
질문:
“파리의 호텔 10개를 추천하고, 각 호텔의 평점과 리뷰를 알려줘.”
DFSDT 방식:
- Step 1: [호텔 검색 도구]를 사용해 파리의 호텔 리스트 검색
- Step 2: [리뷰 API]를 호출하여 각 호텔에 대한 리뷰 수집
- 문제 발생: 일부 호텔에 대한 리뷰가 없음 → 롤백하여 다른 호텔 리스트 재선택
- Step 3: 리뷰가 다 수집되면 Finish Tool을 호출하여 종료
문제: 이러한 방식은 매우 유연하지만 모델의 롤백 결정, 문맥 관리, 종료 시점이 전적으로 모델의 판단에 의존
3. DFSDT의 주요 한계점
논문에서는 DFSDT의 세 가지 근본적인 한계를 다음과 같이 지적:
1. 롤백 불안정성
- 롤백 결정이 모델 자체에 의해 이뤄져, 성능이 낮은 모델은 오류를 반복하거나 너무 멀리 롤백함.
- 예: 같은 툴을 계속 호출하거나, 불필요하게 처음부터 다시 시작.
2. 문맥 중복 (Redundant Context)
- DFSDT는 툴을 사용할 때마다 모든 이전 히스토리(생각, 행동, 입력, 툴 응답)를 참조함.
- 이로 인해 모델이 집중을 잃고, 연산 비용 증가 및 정확도 하락 발생.
3. 조기 종료(Premature Termination)
- Finish Tool을 너무 일찍 선택하는 문제 발생.
- 복잡한 다단계 문제에서 하위 문제만 해결하고도 전체 문제 해결로 착각하여 종료함.
4. Smurfs는 어떻게 DFSDT의 문제를 해결했는가?
핵심 개선 요약:
| DFSDT 문제 | Smurfs의 해결 방식 |
|---|---|
| 롤백 불안정성 | 룰 기반 롤백 (Rule-based) 사용하여 오류 발생 시 툴 삭제 및 재계획, 실패 시 한 단계만 되돌아감 |
| 문맥 중복 | 로컬 메모리/글로벌 메모리 분리, 각 에이전트가 자신에게 필요한 문맥만 참조 |
| 조기 종료 | Planning Agent를 통해 전체 문제를 하위 문제로 분해, 각 서브태스크에 대해 판단 |
| 전통적 단일 모델 판단 | 다중 에이전트 구조 도입: 계획 → 실행 → 응답 → 검증을 각기 다른 에이전트가 수행 |
5. Smurfs 구조
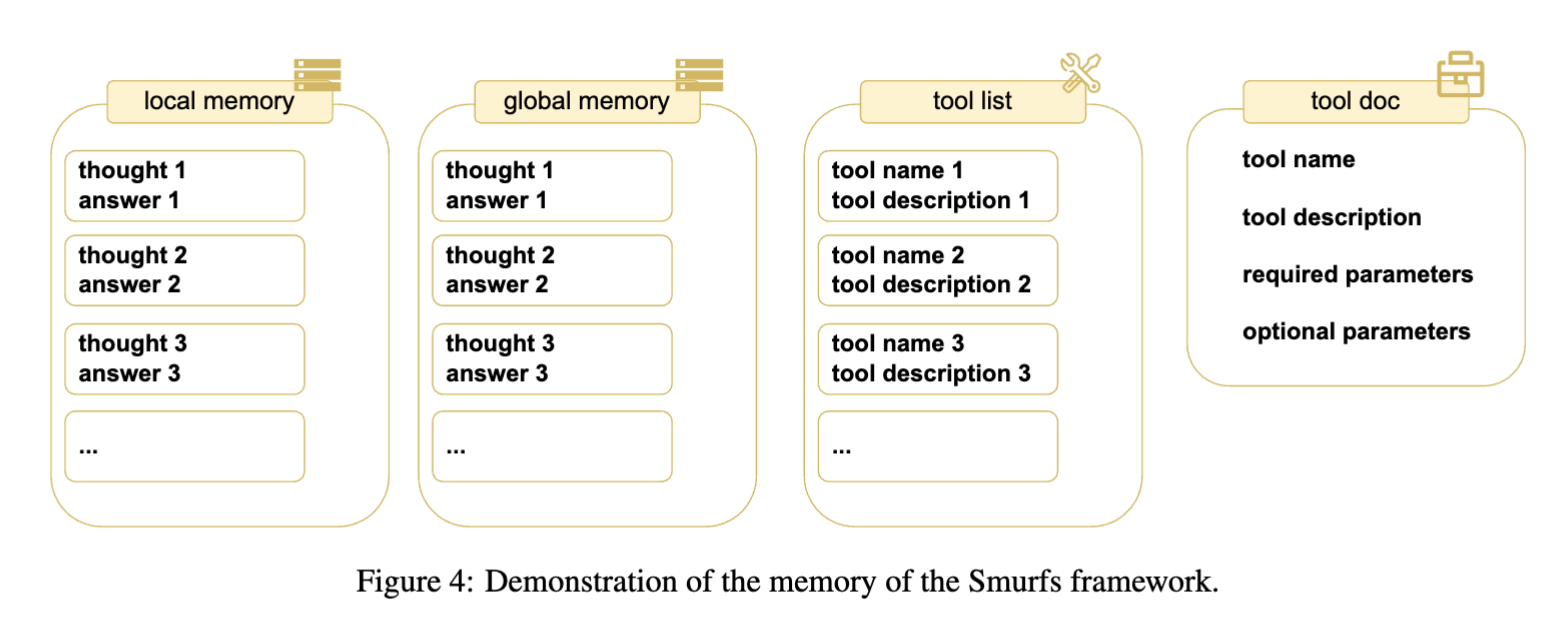
아래는 각 에이전트의 역할과 Smurfs의 시스템:
- Smurfs는 두 가지 메모리 체계를 사용하여 문맥을 효율적으로 유지
| 메모리 종류 | 역할 | | — | — | | 로컬 메모리 | 현재 해결 중인 서브 문제의 thought-answer 쌍 저장 | | 글로벌 메모리 | 전체 작업 과정 추적, 최대 반복 초과 시 최종 응답 생성에 활용 |
- Smurfs는 총 4종의 에이전트로 구성:
- Planning Agent
- Executor Agent
- Answer Agent
- Verifier Agent
- 이 에이전트들은 DFSDT 기반 탐색 및 롤백을 수행
- 각자 맡은 역할에 따라 분산된 문맥과 정확한 판단을 통해 안정성과 효율을 극대
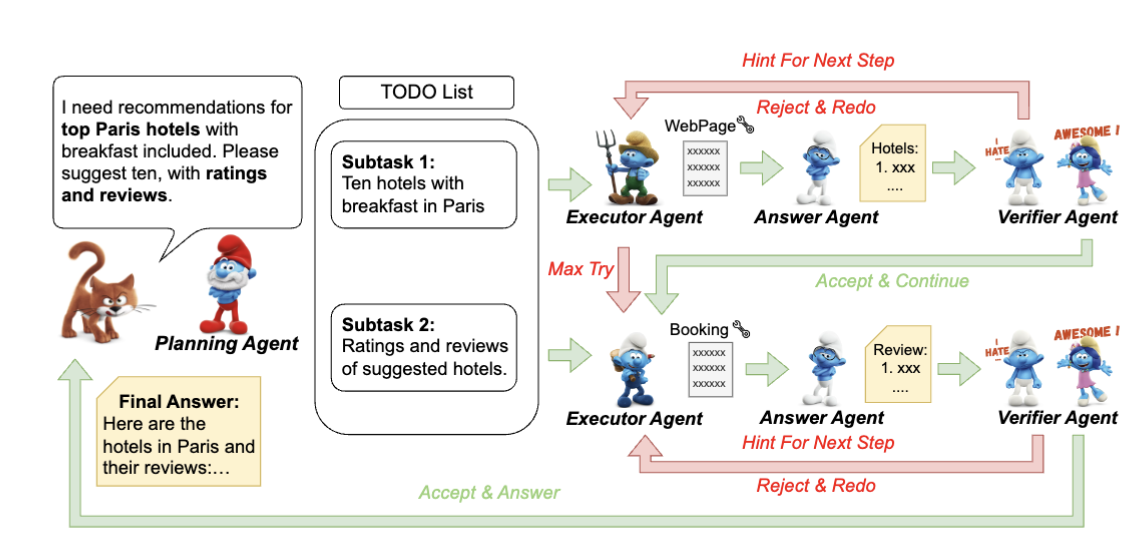
1. Planning Agent
- 사용자의 복잡한 요청을 작은 서브태스크로 분할 (ex. 호텔 추천 → 호텔 목록, 리뷰 수집).
- 이를 통해 조기 종료 문제 해결.
- 기능: 사용자의 복잡한 질의를 여러 개의 작은 하위 문제(sub-tasks)로 나눔
- 핵심 아이디어: LLM이 조기 종료하지 않도록 하기 위한 “Least-to-Most Prompting” 전략 사용
- Least-to-Most Prompting: 복잡한 문제를 해결하기 위해, 문제를 더 쉬운 하위 문제로 분해한 후 그것들을 하나씩 순차적으로 해결해 나가는 단계적 문제 해결 전략
- 처음에는 간단한 하위 질문부터 해결하고,
- 그 결과를 활용하여 점점 복잡한 질문을 해결
- Least-to-Most Prompting: 복잡한 문제를 해결하기 위해, 문제를 더 쉬운 하위 문제로 분해한 후 그것들을 하나씩 순차적으로 해결해 나가는 단계적 문제 해결 전략
- 출력 형식: JSON 배열 형식으로 [“Task 1”, “Task 2”, …]
예시:
사용자 질문: “스타워즈 캐릭터 정보와 관련 영화가 스트리밍되는 OTT 플랫폼을 알려줘”
→ Tasks:
- 특정 캐릭터 정보 수집
- 스타워즈 영화 검색
- 해당 영화가 제공되는 OTT 플랫폼 식별
2. Executor Agent
- 툴을 선택하고 실행함.
- 툴 실패 시 룰 기반으로 툴 목록에서 제거하고, 해결이 안 될 경우 한 단계 롤백.
- 기능:
- 생각(Thought) 생성
- 툴 선택 (choose_tool)
- 입력 파라미터 생성
- 툴 호출 (call_tool)
- 핵심 특징: 매 스텝마다 로컬 메모리와 현재 툴 리스트만 참조 → 문맥 효율성 강화
- 롤백 전략:
- 툴 오류 발생 시 해당 툴을 툴 리스트에서 제거
- 리스트가 비면 상위 단계로 롤백하여 다른 계획 재수립
3. Answer Agent
- 툴 응답 중 필요한 정보만 간결하게 요약하여 문맥 압축(token compression) 수행.
- 기존 DFDS에서는 긴 문맥으로 인해 롤백 문제가 발생했었음
- 기능: 툴 실행 결과와 로컬 메모리를 바탕으로 요약된 응답을 생성
- 목적:
- 긴 응답으로 인해 발생할 수 있는 문맥 손실(lost-in-the-middle) 문제 방지
- 필요한 정보만 정제하여 메모리 효율 극대화
4. Verifier Agent
- 응답의 완성 여부를 판단.
- 미완성이면 힌트를 주고 다음 스텝 진행, 완성이면 다음 서브태스크로 넘어감.
- 기능: 현재 하위 문제가 완전히 해결되었는지 판단
- 출력:
- Status = 1 → 다음 sub-task로 넘어감
- Status = 0 → 힌트 제공 후 다음 스텝 진행
- 역할: DFSDT의 Finish Tool 기반 종료의 불안정성을 보완
5. 토큰 효율성: Token Compression 전략
Smurfs는 툴 응답과 히스토리 전체를 사용하지 않고, 각 단계에서 필요한 정보만 선택적으로 사용함으로써 다음을 달성:
- DFSDT 대비 토큰 사용량 최대 60.9% 절감
- 동일한 문제에 대해 더 적은 비용으로 동일 또는 더 나은 성능 확보
6. 효과
- 문맥 효율성 강화: 각 툴 사용 시 필요한 최소 문맥만 참조하여 “lost-in-the-middle” 문제 감소.
- 룰 기반 롤백: 모델이 아닌 규칙 기반으로 툴 실패 시 롤백하여 안정성 강화.
- 로컬/글로벌 메모리 시스템: 각각의 툴 사용 흐름을 정리하고, 최종 답변 생성 시 병합하여 사용.
6. 성능 평가
Open-ended Benchmark (StableToolBench)
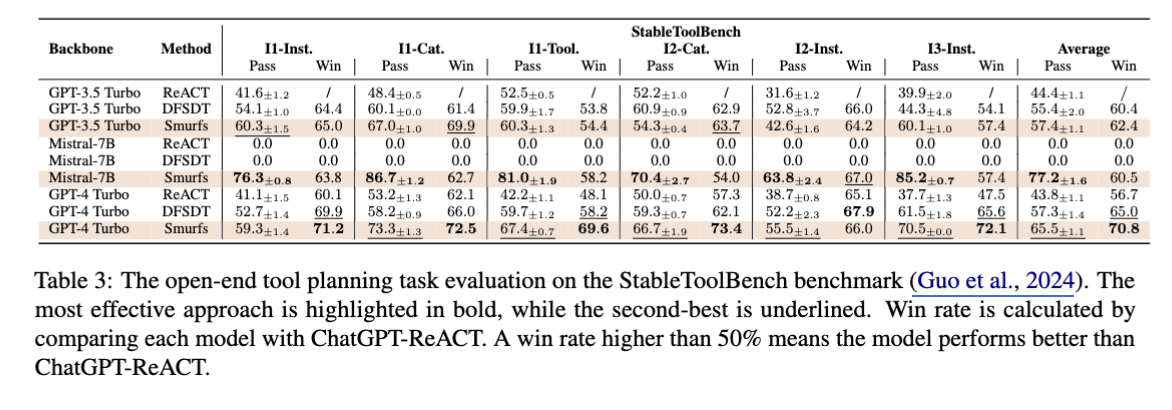
→ Smurfs는 Mistral-7B와 같은 약한 모델도 GPT-4 수준으로 향상시킴.
Closed-ended QA (HotpotQA)
- 대부분의 상황에서 학습된 시스템들보다 높은 정확도 달성.
- 특히 Llama-2 70B와 함께 사용 시 49.5% 정확도.
7. Ablation Study 결과
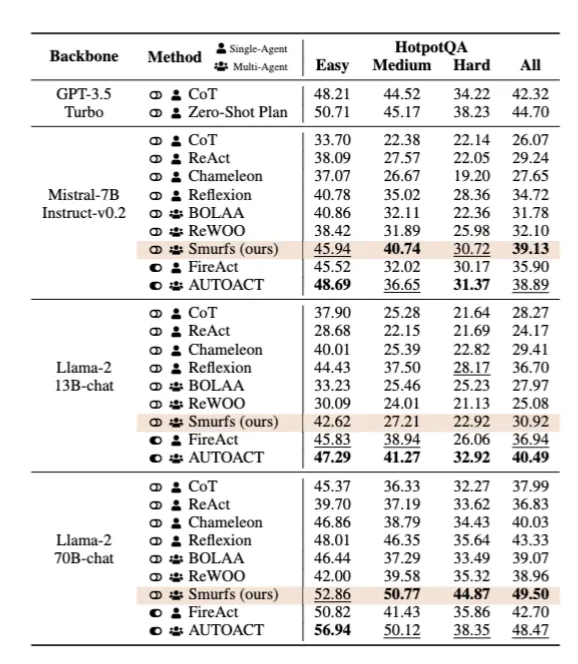
- Planning Agent 제거 시 성능 급감.
- Answer Agent는 GPT-3.5에서는 중요하지만, GPT-4에서는 큰 영향 없음.
- 결론: 약한 모델은 에이전트 분리 효과가 크며, 강한 모델은 전체 문맥 사용이 더 유리할 수 있음. 표 5, 페이지 8
8. 결론
- Smurfs는 복잡한 도구 계획을 훈련 없이 처리 가능한 통합 MAS 시스템으로 뛰어난 일반화 능력과 문맥 효율성을 증명.
- 특히 성능이 낮은 모델에서는 멀티 에이전트 구조가 큰 효과, 성능이 높은 모델은 단순 구조로도 충분하다는 가설 제시.
This post is licensed under CC BY 4.0 by the author.