SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs
SoftCoT: Soft Chain-of-Thought for Efficient Reasoning with LLMs
Written by. Yige Xu, Xu Guo
연구 배경 및 문제점
- CoT 추론의 발전과 한계:
- CoT(Chain-of-Thought) 추론: 대규모 언어 모델(LLM)이 중간 추론 단계를 생성하여 복잡한 추론 작업을 해결하도록 돕는 방식.
- 기존 CoT 방식의 한계: 대부분의 기존 접근 방식은 ‘하드 토큰 디코딩(hard token decoding)’에 중점을 두어, 이산적인 어휘 공간 내에서 추론을 제한하며 항상 최적의 결과를 내지 못함.
- 하드 토큰 디코딩: discrete한 어휘 목록에서 가장 확률이 높은 하나의 단어(토큰)를 선택해서 문장을 만들어 나가는 방식
- 연속 공간 추론의 문제점: 최근 연속 공간 추론(continuous-space reasoning)을 탐색하는 시도들은 종종 전체 모델 미세 조정(full-model fine-tuning)을 요구하며, 이로 인해 ‘catastrophic forgetting’ 문제에 직면.
- LLaMA-3.1-8B, Qwen2.5-7B 같은 최신 모델은 zero-shot CoT가 이미 뛰어난데, 기존 continuous CoT 방법(Coconut 등)은 오히려 성능 저하 유발.
- SoftCoT의 제안 및 특징:
- 모델 수정 불필요: LLM을 수정하지 않고 연속 공간 추론을 위한 새로운 접근 방식을 제안.
- 경량 보조 모델 활용: 경량의 fixed assistant model을 사용하여 인스턴스별 ‘soft thought tokens’을 생성.
- projection 모듈을 통한 매핑: 생성된 soft thought tokens은 trainable projection module을 통해 LLM의 표현 공간으로 매핑.
- 성능 향상: 5가지 추론 벤치마크 실험 결과, SoftCoT는 supervised, parameter-efficient finetuning을 통해 LLM의 추론 성능을 향상.
- 오픈 소스 제공: 소스 코드는 [https://github.com/xuyige/SoftCoT]
SoftCoT 프레임워크
문제 정의
- CoT 추론의 두 단계
- 합리화 단계 생성:
질문 $Q = [q_1, q_2, \dots, q_{|Q|}]$ 이 주어지면, 모델은 합리화 단계
$R = [r_1, r_2, \dots, r_{|R|}]$ 를 자기회귀적으로 생성. - 답변 생성:
생성된 합리화 단계 $R$과 질문 $Q$를 바탕으로 답변
$A = [a_1, a_2, \dots, a_{|A|}]$ 를 자기회귀적으로 생성.
- 합리화 단계 생성:
- Hard-CoT와 Soft-CoT의 구분:
- Hard-CoT: 대부분의 최근 연구는 R에서 이산적인 하드 토큰을 생성하는 데 중점을 두며, 이를 “Hard-CoT”라고 함.
- Soft-CoT: 일부 최근 연구는 R의 연속 표현(잠재 공간)에 중점을 두며, 이를 “Soft-CoT”라고 함.
- 답변 정확도 계산:
- 답변 추출: LLM이 생성한 답변 A에서 수동으로 정의된 규칙(예: 정규 표현식 매칭)을 사용하여 $\hat{A}$를 추출.
- 정확도 계산: 추출된 $\hat{A}$를 정답 A와 비교하여 정확도를 계산.
SoftCoT 프레임워크 개요
- 프레임워크 구성: 입력 질문 Q가 주어지면, 프레임워크는 추론 단계 R과 최종 답변 A를 모두 생성.
세 가지 핵심 구성 요소: SoftCoT는 세 가지 핵심 구성 요소로 구성.
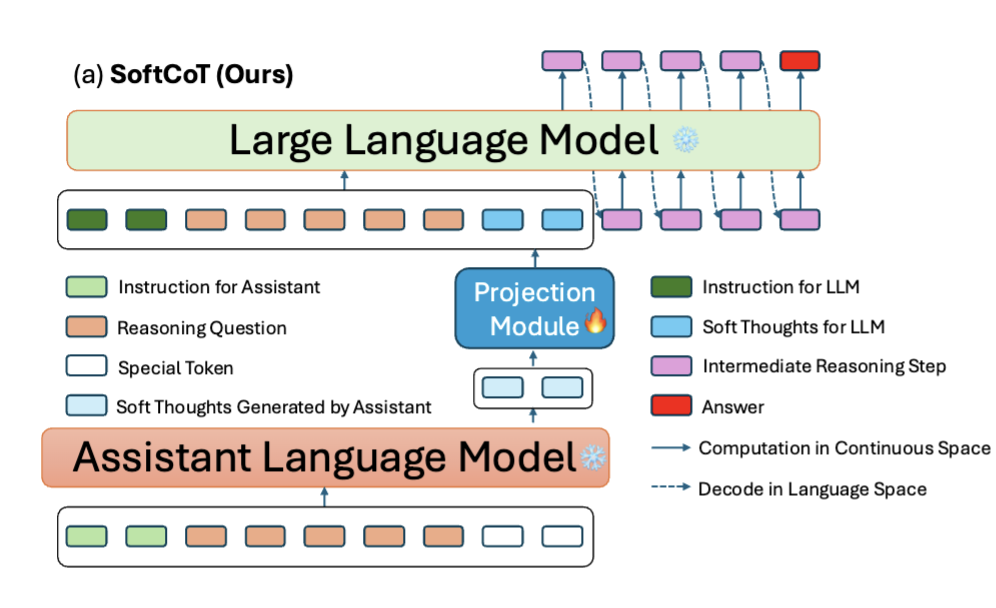
- soft thought token generation module
- 프롬프트 튜닝에서 영감: 프롬프트 튜닝 기술에서 영감.
- 보조 언어 모델 사용: SoftCoT에서는 assistant language model이 soft thought 토큰을 생성하며, 이 모델은 일반적으로 백본 LLM보다 작음.
- 예: LLaMA-3.2-1B-Instruct를 보조 모델로, LLaMA-3.1-8B-Instruct를 백본 모델로 사용.
- 기존 방식의 한계: 보조 모델은 백본 LLM의 입력으로 이산 토큰 시퀀스만 생성할 수 있으며, 이는 표현력에 대한 제약, 항상 최적의 프롬프트를 생성하지 못할 수 있음.
- 연속 soft thought 토큰 도입: 이러한 한계를 해결하기 위해, 더 표현력이 풍부하고 유연한 프롬프팅을 가능하게 하는 연속 soft thought 토큰을 도입.
- 표현 격차: 그러나 보조 모델과 백본 LLM 사이에 표현 격차가 존재하므로 중간 변환이 필요.
- projection module
- 격차 해소: 투영 모듈은 soft thought 토큰의 표현을 백본 LLM과 더 호환되는 공간으로 매핑하여 이 격차를 해소.
- 추론 과정 안내: 이는 soft thought 토큰이 추론 과정을 효과적으로 안내하도록 보장.
- CoT reasoning module
- 학습된 soft thought 토큰 및 단어 임베딩 활용: CoT 추론 모듈은 학습된 soft thought 토큰과 단어 임베딩을 모두 활용하여 중간 추론 단계 R과 최종 답변 A를 생성.
- 언어 모델링 목표로 훈련: 모델은 언어 모델링 목표를 사용하여 훈련되며, 합리화 단계와 답변 범위에 걸쳐 학습 가능한 매개변수를 최적화.
- $\mathcal{L} = - \sum \log P(R, A \mid I_{\text{assist}}, Q, T_{\text{soft}})$
- R: reasoning 단계 (중간 추론 문장들)
- A: 최종 정답
- $T_{\text{soft}}$: 보조 모델이 생성하고 projection 모듈로 변환된 soft thought tokens
- $I_{\text{assist}}$: task-specific instruction
- Q: 질문
- $\mathcal{L} = - \sum \log P(R, A \mid I_{\text{assist}}, Q, T_{\text{soft}})$
- soft thought token generation module
SoftCoT의 Prompt Tuning for CoT Reasoning
- 기본 아이디어
- 전통적인 prompt tuning은 사전학습된 LLM에 대해 고정된 학습 가능한 텍스트 벡터(prompt)를 추가하여 성능을 개선.
- SoftCoT는 이 개념을 확장하여, 각 문제 인스턴스에 맞는 instance-specific prompt를 생성하고 이를 연속 공간에서 표현.
즉, SoftCoT에서는 prompt tuning이 다음 2가지 구성으로 분해:
\[p = p_{\text{task-specific}} + p_{\text{instance-specific}}\\\]- Prompt 구성
- (1) Task-specific Prompt ( $p_{\text{task}}$)
- 모든 문제 인스턴스에 공통 적용되는 고정된 지시문
예: 수학 문제 해결을 위한 계산 방식 설명
“For complex problems (3 steps or more): Use this step-by-step format…”
- (2) Instance-specific Prompt ( $p_{\text{inst}}$ )
- 보조 모델이 문제 Q를 기반으로 동적으로 생성하는 soft thought tokens
- 이 부분이 SoftCoT의 핵심이며, discrete token이 아닌 continuous latent vector로 표현됨
- 보조 모델을 활용한 Prompt 생성 과정
보조 모델 입력:
\[x_{\text{assist}} = \text{concat}(I_{\text{assist}}, Q, [\text{UNK}]_{1:N})\]- $I_{\text{assist}}$: assistant 모델을 위한 지시문
- QQQ: 문제 질문
- $[\text{UNK}]_{1:N}$: soft thought를 생성하기 위한 자리 표시자
보조 모델은 이 입력을 처리하고, 마지막 레이어의 hidden state에서 soft thoughts를 추출:
\[t_{\text{assist}} = h_{\text{assist}}[|I| + |Q| + 1 : |I| + |Q| + N]\]
- (1) Task-specific Prompt ( $p_{\text{task}}$)
- LLM 입력 구성
보조 모델의 soft tokens을 projection 모듈을 통해 변환한 후, LLM의 입력으로 다음과 같이 사용:
\[x_{\text{LLM}} = \text{concat}(I_{\text{LLM}}, Q, T_{\text{soft}}), \quad T_{\text{soft}} = \text{Linear}_{\theta}(t_{\text{assist}})\]- 이 입력은 LLM의 추론을 유도하는 프롬프트 역할을 함.
- Prompt Tuning의 목적 수식
프롬프트 튜닝은 다음과 같은 최적화 문제로 공식화됨:
\[\hat{y} = \text{LLM}(P_p(x)), \quad p^* = \arg\min_p \mathcal{L}(\hat{y}, y)\]- Pp(x): prompt p를 포함한 입력 시퀀스
- y: 정답 (reasoning step과 answer)
- $\mathcal{L}$: negative log-likelihood loss
실험
데이터셋
- 실험 데이터셋: 수학적 추론, 상식 추론, 상징적 추론의 세 가지 추론 범주에 걸쳐 5가지 추론 데이터셋
- 수학적 추론: GSM8K, ASDiv, AQuA
- 상식 추론: StrategyQA
- 상징적 추론: BIG-benchmark의 DateUnderstanding
- ASDiv-Aug 데이터셋 생성:
- 목적: LLaMA-3.1-8B-Instruct가 잘 훈련된 LLM이므로, 모델이 새로운 인스턴스를 접하도록 ASDiv 데이터셋을 증강.
- 방법: 각 인스턴스를 5번 복제하고, 질문의 숫자 값을 무작위로 선택된 대체 값으로 추출 및 대체.
- 예: “하루에 사과 6개 먹기”는 6을 7, 8, 12, 18 등으로 무작위로 대체하여 여러 번 복제.
- 이 증강은 모델의 암기된 데이터에서 패턴을 인식하는 능력보다는 추론 능력을 평가하기 위해 설계.
- 오픈 소스: ASDiv-Aug는 [https://huggingface.co/datasets/xuyige/ASDiv-Aug] 공개.
Baseline
- Zero-Shot CoT:
- SFT 후 모델이 성능 저하를 겪는지 평가하는 데 사용.
- Zero-Shot CoT-Unk:
- [UNK] 토큰 추가: LLM이 CoT 추론을 수행하도록 튜닝되지 않은 프롬프트를 나타내기 위해 일부 [UNK] 토큰을 직접 추가.
- soft thought token에 대한 효과를 평가.
- 이전 연구에서는 [UNK]를 “pause token”으로 사용하여 추론 품질을 높이는 효과가 있었음.
- Zero-Shot Assist-CoT:
- 보조 모델의 하드 토큰 생성 후 프롬프트 토큰으로 활용
- 하드 토큰 프롬프트와 비교하여 소프트 thought token의 효과 평가
- Coconut:
- 연속 잠재 공간 추론: LLM이 이전 단계의 은닉 상태를 다음 단계의 입력 임베딩으로 반복적으로 공급하여 연속 잠재 공간에서 추론하도록 훈련하는 방법을 제안.
- LoRA Fine-Tuning:
- 전통적인 방법(LoRA)과 비교하여 LLM에 soft thought를 추가하는 것의 효과를 검증.
실험 결과 및 논의
주요 결과
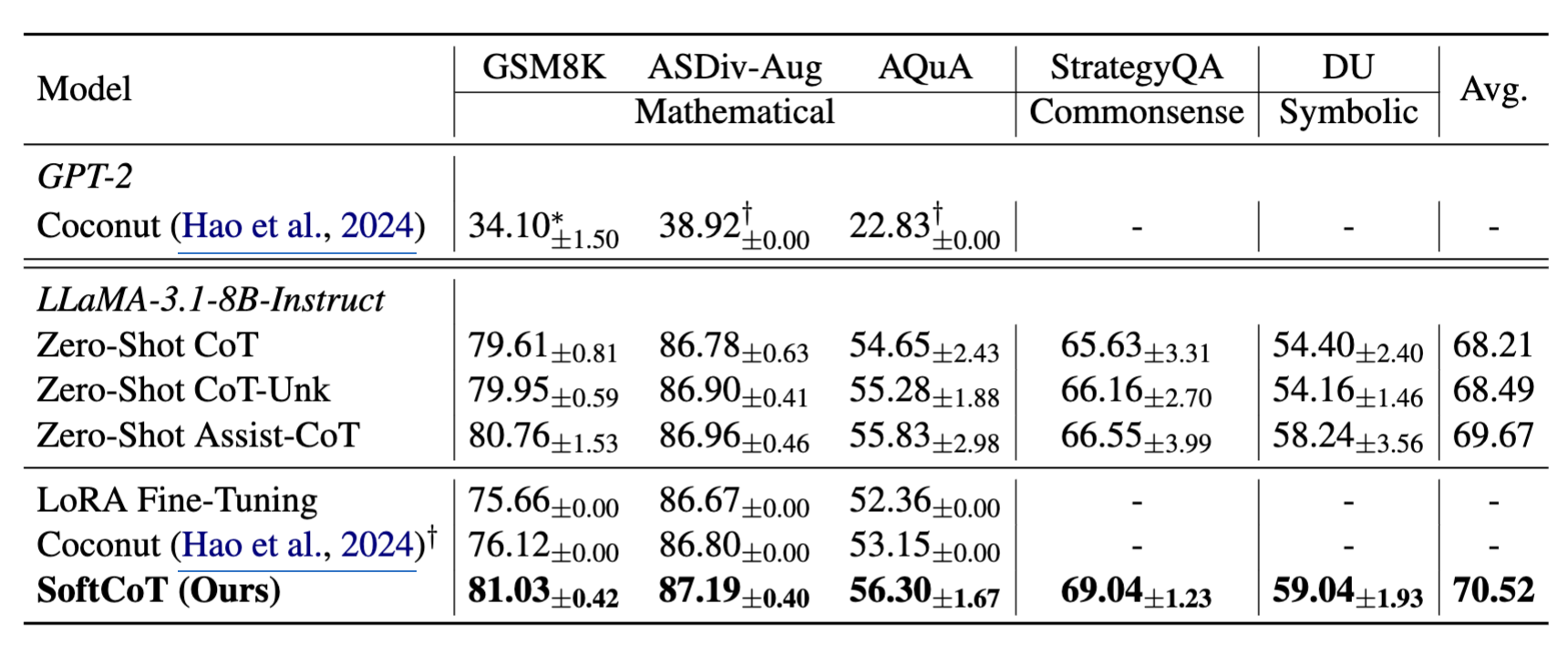
- 주요 성과 요약
- SoftCoT는 Zero-Shot CoT, Assist-CoT, LoRA, Coconut 등 모든 baseline보다 일관된 성능 향상
- Zero-Shot CoT보다 높은 정확도, Coconut/LoRA보다 재앙적 망각 문제 없이 안정적 추론 성능 유지
- 보조 모델 활용의 효과
- 하드 토큰을 생성하는 Zero-Shot Assist-CoT도 일정 수준의 향상은 보여줌
- 그러나 soft thought를 사용하는 SoftCoT가 더 적은 토큰 수로 더 높은 성능을 기록
LLM 백본 확장 실험 (Qwen2.5)
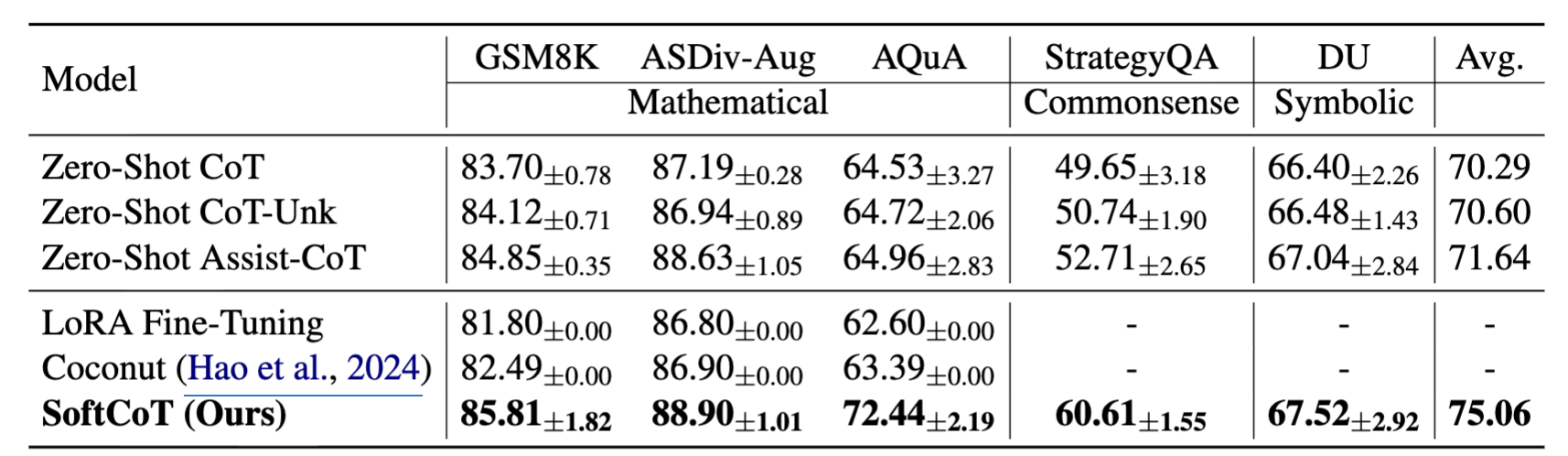
- SoftCoT는 LLaMA 외에도 Qwen2.5-7B 같은 최신 LLM에서도 효과적으로 작동
- 상식 reasoning처럼 원래 약한 영역에서 특히 큰 향상, 수학 영역에서도 성능 보존
- 훈련 데이터가 없는 Date Understanding에서도 다른 데이터셋 학습 후 zero-shot 전이 가능
모델 분석 및 추가 실험
사고 토큰 수 실험
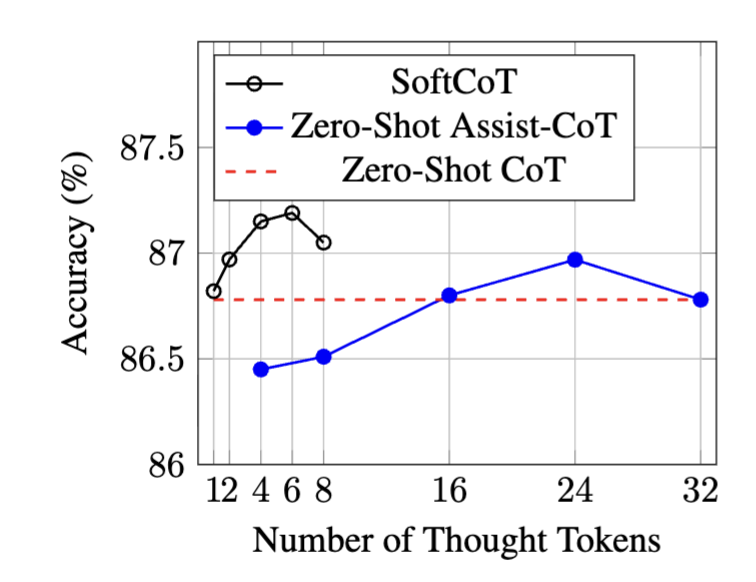
- SoftCoT는 단 6개의 soft thought tokens만으로 최적 성능
- Zero-Shot Assist-CoT는 24개 이상의 하드 토큰이 필요
- soft token이 표현력에서 더 우수하며, 실험적으로 하드 토큰 수의 4~5배 효율성을 가짐
보조 모델 크기 실험
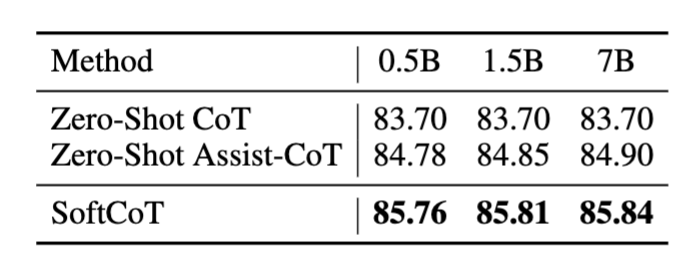
- 보조 모델의 크기를 키워도 성능 변화는 거의 없음
- 이는 보조 모델은 어디까지나 “문제 요약자” 역할만 수행하기 때문
Self-Consistency와의 결합

- SoftCoT는 self-consistency (다수의 reasoning path 생성 후 투표)와 완전히 독립적인 향상 효과
- 둘을 함께 사용하면 성능이 더 향상되며, 더 짧은 reasoning path로 더 정확한 결과 도출 가능
결론
- SoftCoT는 기존 CoT의 표현력 한계를 극복하고, reasoning 성능을 향상시키는 가볍고 효과적인 프롬프트 전략
- LLM의 본체를 고정하고, 보조 모델과 projection layer만 활용하여 catastrophic forgetting 없이 fine-tuning 가능
- 다양한 데이터셋과 LLM에서 일관되게 효과적이며, self-consistency나 domain transfer와도 잘 결합됨
한계
- 추론 경로를 완전히 대체하는게 아님
- soft thought 토큰은 확률 공간을 풍부하게 하는 역할.
This post is licensed under CC BY 4.0 by the author.