U-MARVEL: Unveiling Key Factors for Universal Multimodal Retrieval via Embedding Learning with MLLMs
Written By. Xiaojie Li, Chu Li, Shi-Zhe Chen, Xi Chen
1. 문제 정의
Universal Multimodal Retrieval (UMR)은
- 질의(query) 와 후보(candidate) 가 텍스트/이미지/텍스트+이미지 등 다양한 모달리티 조합을 가질 수 있음
- instruction에 따라 검색 목표가 달라지는 instruction-guided 통합 검색을 목표로 함.
하지만 최근 MLLM 기반 UMR 방법들(LamRA, MM-Embed, GME, UniME, VLM2VEC 등)은 대부분 대조학습(contrastive learning) 을 쓰면서도,
- 임베딩을 어떤 방식으로 뽑아야 하는지,
- decoder-only MLLM을 임베딩 모델로 어떻게 적응시키는지,
- InfoNCE 학습에서 배치/러닝레이트/온도/하드네거티브 같은 디테일이 왜/어떻게 성능에 영향을 주는지,
- recall-then-rerank 구조를 단일 모델로 distill할 수 있는지
같은 요인이 체계적으로 분석되어 있지 않음.
따라서, 이 논문은 UMR에서
- MLLM 임베딩 학습의 key factors을 실험적으로 분해해 밝히고
- 그 결과를 묶어 U-MARVEL이라는 통합 학습 레시피/프레임워크를 제안.
2. Method
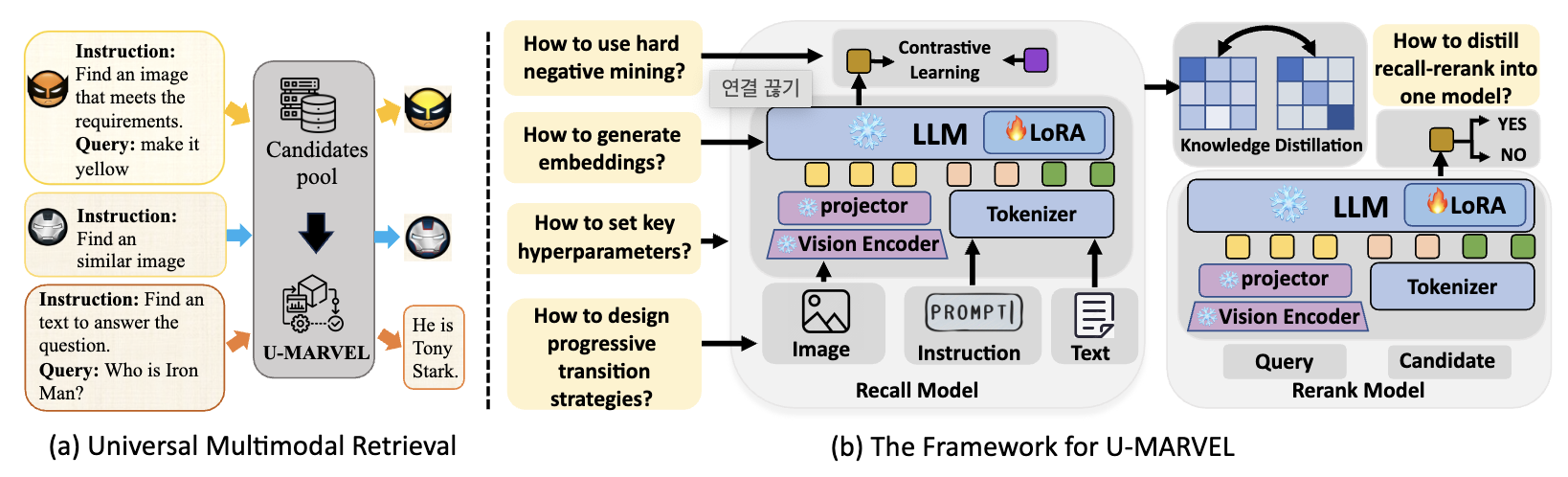
MLLM을 임베딩 모델로 잘 만들기 위한 설계/학습 레시피를 3축으로 정리.
2.0 기본 파이프라인(베이스라인)
- 백본: Qwen2-VL-7B-Instruct를 임베딩 모델로 사용
- 학습: LoRA로 LLM 부분만 튜닝, 비전 인코더/프로젝터 등 “visual side”는 freeze
- 목적함수: InfoNCE (코사인 유사도/temperature τ 사용)
- 데이터: 주로 M-BEIR로 supervised 학습/평가
2.1 (축 1) Decoder-only MLLM을 임베딩 모델로 변환
2.1.1 임베딩 추출
기존 MLLM 기반 retrieval 논문들에 흔한 방식은:
- Last-token + compression prompt
- 입력 끝에 “Summarize … in one word:
” 같은 압축 프롬프트를 붙이고, - 마지막 토큰(예:
)의 hidden state를 임베딩으로 사용
- 입력 끝에 “Summarize … in one word:
이 논문은 여기서 대안으로:
- Bidirectional attention + mean pooling
- causal(단방향) 대신 bidirectional attention으로 바꾸고,
- 마지막 레이어 hidden states를 mean pooling해서 시퀀스 임베딩으로
Finding 1 결론:
“Bidirectional + mean pooling”이 “compression prompt + last token”보다 전반적으로 더 좋다.
왜 그런가:
- last token은 “마지막 토큰에 정보가 몰리는” 구조라 recency bias 영향을 크게 받는다고 설명.
- 반면 mean pooling은 전체 시퀀스 표현을 고르게 반영해 임베딩 모델 목적(holistic representation)에 더 맞다는 논리.
중요한 상호작용:
- compression prompt는 last token일 때 강하게 맞물려 작동하고(mean token으로 바꾸면 성능 급락),
- bidirectional attention은 이 결합을 일부 완화하지만,
- 결국 bidirectional + mean pooling에서 compression prompt를 제거하는 게 가장 낫다는 결론
2.1.2 Instruction 통합(Instruction Integration)
UMR에서는 입력이 보통 [Instruction] + [Query(텍스트/이미지/혼합)] 형태
Mean pooling을 할 때 instruction 토큰까지 함께 평균내면,
- instruction이 이미 self-attention으로 query representation에 반영되어 있는데,
- pooling에서 instruction을 또 섞어 비교(쿼리-후보) 관점에서 바이어스가 생길 수 있다고 봄.
그래서 제안:
- mean pooling 시 instruction 토큰을 마스킹(제외)하고 query 부분만 pooling
Finding 2 결론:
Instruction을 pooling에서 빼면 성능이 소폭이지만 일관되게 오름.
2.1.3 Progressive Transition (단계적 전이 학습)
decoder-only MLLM은 원래 생성(autoregressive) 용도라 retrieval 임베딩 학습으로 바로 던지면 “task 난이도 갭”이 큼.
그래서 논문은 “쉬운 것 → 어려운 것” 순으로 3단계 적응을 제안.
- Text Retrieval Adaptation
- NLI 기반 데이터(논문은 SimCSE NLI를 언급) 등으로 텍스트 임베딩/대조학습 감각을 먼저 잡음
- 이 단계는 unidirectional InfoNCE로 학습했다고 명시
- Cross-modal Alignment
- CC3M 같은 텍스트-이미지 페어로 cross-modal 정렬을 강화
- 이 단계는 bidirectional InfoNCE로 학습했다고 설명
- Instruction Tuning for Multimodal Retrieval
- 마지막으로 M-BEIR 같은 멀티태스크/멀티인스트럭션 UMR 데이터로 마무리 튜닝
Finding 3 결론:
Text-only → Text-image → Instruction-guided UMR 순으로 단계적으로 가면 성능이 꾸준히 개선
핵심 직관(논문 주장):
- causal 학습에 익숙한 LLM을 bidirectional로 바꾸면 정렬이 깨질 수 있는데,
- text 단계에서 “텍스트 의미 표현”을 강화하고,
- 이미지-텍스트 페어로 “텍스트-비전 정렬”을 회복/강화한다는 시나리오.
2.2 (축 2) InfoNCE로 MLLM embedder를 학습할 때의 “레시피”
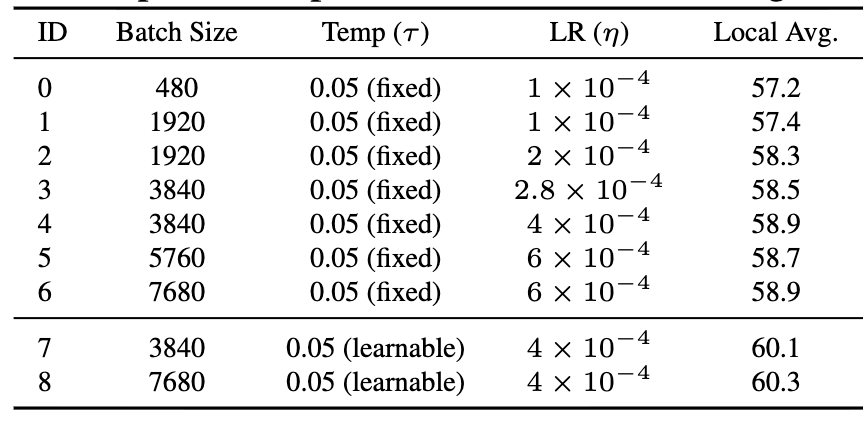
2.2.1 배치 크기–러닝레이트–온도(temperature)의 상호작용
논문은 흔한 믿음(“배치 키우면 무조건 좋아짐”)을 반박.
Table 4에서 보여주는 것:
- 배치를 키우면 좋아지긴 하는데 어느 순간 plateau가 옴
- 배치만 키우고 lr 그대로면 개선이 거의 없음 (ID-0 vs ID-1)
- lr은 배치 증가에 맞춰 스케일링해야 하고, 여기서는 “증가 비율의 sqrt 정도가 적절”하다고 관찰
- 그리고 가장 중요한 주장 중 하나:
- τ를 고정하지 말고 learnable temperature로 두면 성능이 크게 오름.
Finding 4 요약:
- 큰 배치는 유리하지만 lr 스케일링 없이는 이득이 작고, 2. learnable τ가 대조학습을 더 robust하게 만듬
2.2.2 Continual Training + Hard Negative Mining
여기서 논문은 “하드 네거티브가 항상 좋은 게 아니다”를 강하게 보여줌.

- 단순히 top-k hard negative만 쓰면 학습 실패(ID-0)
- in-batch negative에 hard negative를 섞어도 오히려 성능 하락(ID-1).
원인 가설:
- hard negative 중 일부는 사실 정답일 수 있는 false negative(semantic similarity는 높지만 라벨상 negative)라서 학습을 망친다.
그래서 제안하는 간단하지만 효과 큰 레시피:
Hard Negative Mining 절차(논문이 단계로 명시):
- Feature extraction
- 이전 스테이지 모델로 모든 query/candidate 임베딩 추출
- positive 제외하고 similarity 계산 후 랭킹 → “어려운 negative” 후보 생성
- Filtered hard negative
- similarity가 threshold를 초과하는 negative는 false negative로 보고 제거
- 남은 것 중 top-k만 선택
- Balanced training
- hard negative만 쓰면 너무 어렵고 수렴이 안 되므로,
- 적당한 k를 고르고, in-batch negative와 섞어서 continual finetuning을 InfoNCE로 수행
Finding 5 결론:
“false negative 필터링 + in-batch 혼합”이 성능을 크게 끌어올린다
2.3 (축 3) Recall-then-Rerank를 “단일 임베딩 모델”로 distill
UMR 시스템에서 흔한 구조:
- recall 모델(임베딩) 로 top-k 후보를 좁힌 뒤
- reranker 로 재정렬 → 성능 좋아지지만 지연/복잡도 증가
논문은 이를 teacher(리콜+리랭크 앙상블) → student(단일 임베딩 모델) 로 distill해
- cascade를 제거하면서 성능을 유지/개선하는 게 목표
2.3.1 Reranker 학습 방식(teacher 구성)
- decoder-only MLLM 기반 generative reranker를 학습
- 데이터 구성:
- 임베딩 모델로 임베딩 뽑고
- 각 query에 대해 positive + “가장 어려운 negative(상위 50개)”를 구성
- 프롬프트 출력:
- positive면 “YES”, negative면 “NO”
- next-token prediction loss로 학습
리랭킹 스코어:
- reranker가 “YES”일 확률을 score로 사용
- recall score와 rerank score를 선형 결합: $S_{\text{multi}} = \alpha S_{\text{recall}} + (1-\alpha) S_{\text{rerank}}$
2.3.2 Distillation(teacher → student)
- student는 “단일 임베딩 모델”
teacher가 만들어낸 결합 스코어 분포 $S_{\text{multi}}$를 학생의 $S_{\text{single}}$이 모방하도록
KL divergence로 학습: $L_{\text{distill}} = D_{KL}(S_{\text{multi}} \parallel S_{\text{single}})$
- full distill은 비싸지만, 데이터 10%만으로도 큰 개선을 보였다고 강조함.
또 하나 중요한 실험:
- “distill 성능 향상이 단지 hard negative를 더 본 효과냐?”를 보기 위해
- 같은 데이터를 hard negative로만 보고 계속 InfoNCE 학습(“Continue-hard”)을 돌렸더니
- distillation이 더 좋았음
Finding 6 결론:
reranker distillation은 “hard negative 추가”만으로 설명되지 않는, 실제 distill 효과로 성능을 더 올림.

2.4 최종 프레임워크: U-MARVEL = 3-stage recipe
논문은 위 발견들을 다음 3단계로 묶어 U-MARVEL이라 명명.
- Progressive transition (text → text-image → instruction UMR)
- Hard negative mining (false negative filtering + 혼합)
- Distillation (reranker 기반 recall-then-rerank를 single model로 distill)
구체 하이퍼파라미터/학습 설정은 Appendix C의 Table 12에 정리되어 있음.
3. Experiments
3.1 데이터/평가: M-BEIR
- M-BEIR는 instruction + query set + candidate pool 구조이고,
- 텍스트/이미지/혼합 등 8개 유형을 더 세분화해 총 16 retrieval 타입 평가
- Train: 133만 query / 193만 candidate, Test: 19만 query / 560만 candidate
- Metric: Fashion200K/FashionIQ는 R@10, 나머지는 R@5
- Local pool vs Global pool(글로벌은 모달리티 에러 가능) 모두 평가
3.2 핵심 ablation: “Finding”들을 실험 성능으로 검증
- Table 1: last token vs mean pooling + (causal/bidir) + compression prompt 여부
- Table 2: instruction token masking pooling
- Table 3: progressive transition 단계별 성능
- Table 4: batch/lr/temperature 상호작용 + learnable τ
- Table 5: hard negative mining 실패 사례와 filtered 전략의 효과
- Table 6: distillation vs continue-hard 통제
3.3 SOTA 비교: M-BEIR supervised
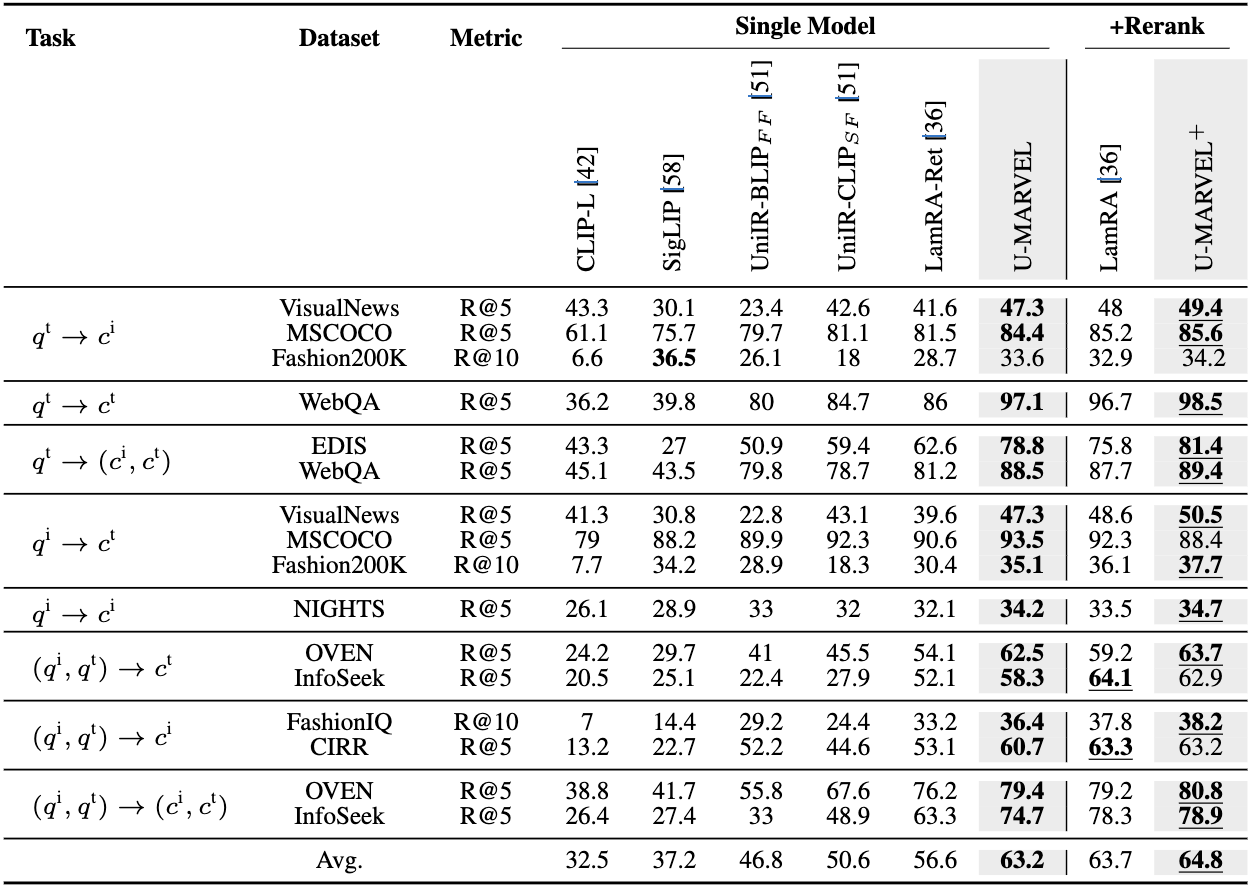
- local pool: U-MARVEL이 single-model 기준 평균 63.7로, LamRA-Ret(63.2) 등 대비 우수하며, +rerank 버전(U-MARVEL+)도 가장 높음
- 논문은 특히 단일 모델인데도 기존의 cascade가 내던 성능에 근접/상회하는 점을 강조
3.4 Zero-shot 평가
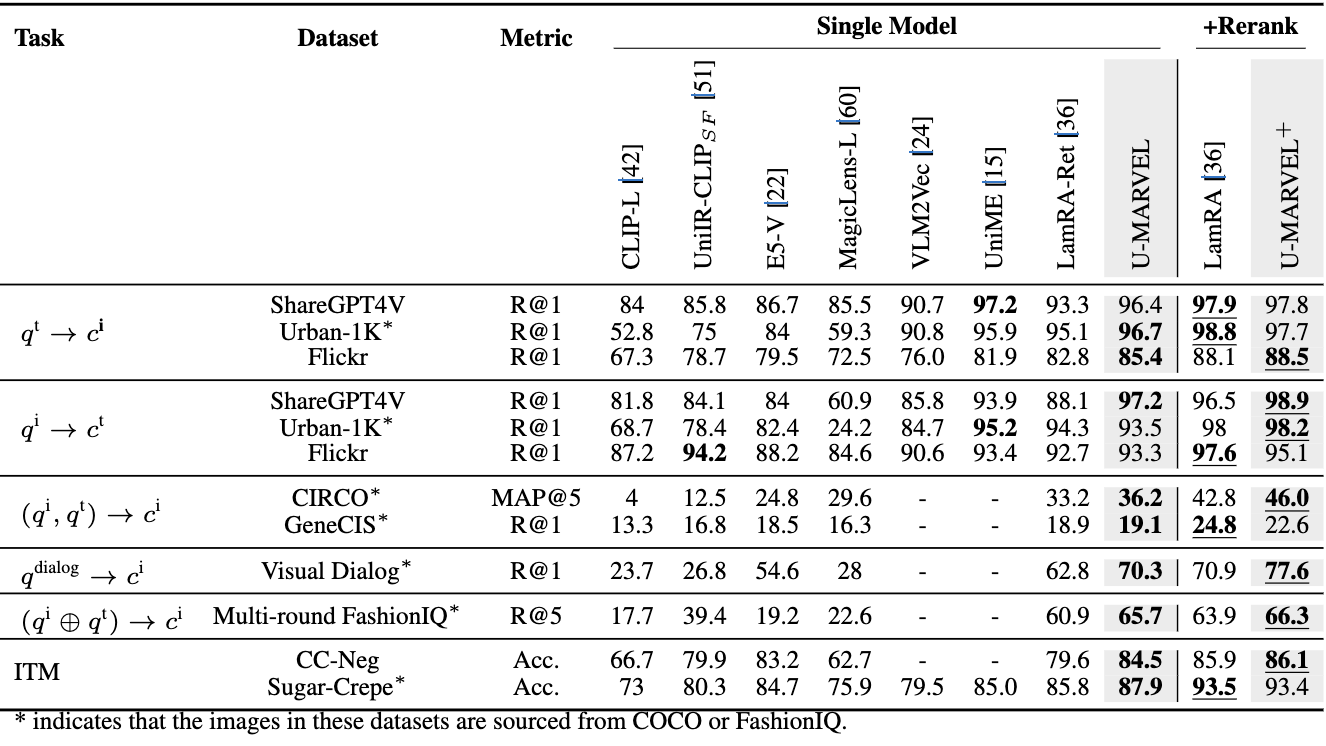
- ShareGPT4V, Urban-1K, Flickr, CIRCO 등 unseen 데이터에서 강한 성능(10개 중 6개 task SOTA라고 주장)
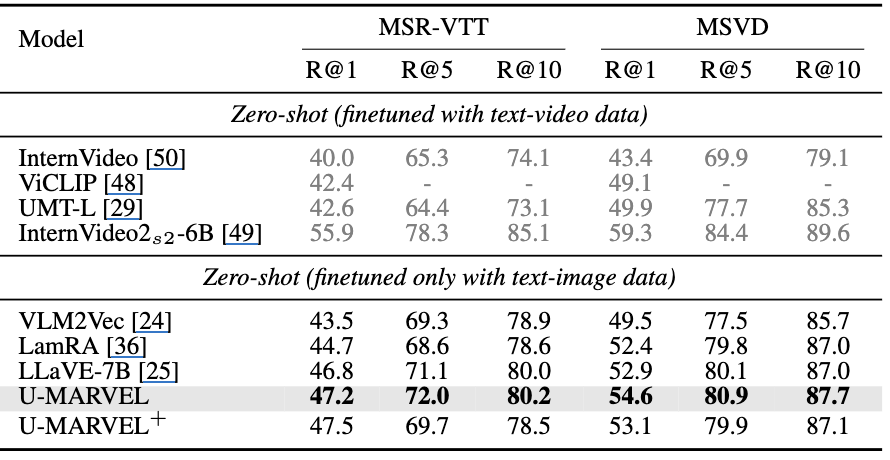
- text-to-video(MSR-VTT, MSVD)에서도 text-image만으로 finetune했는데 LamRA/VLM2Vec/LLaVE-7B보다 높거나 비슷한 결과 보고
4. 결론
- MLLM 기반 UMR에서 성능을 좌우하는 요인을 체계적으로 분해해 보여줌:
- 임베딩 추출(특히 bidirectional+mean pooling),
- instruction token 처리,
- progressive transition,
- InfoNCE 파라미터들 작용(배치–lr–learnable τ),
- hard negative mining에서 false negative 필터링,
- reranker distillation
- 이를 통합한 U-MARVEL이 M-BEIR supervised에서 큰 폭으로 SOTA를 갱신하고, zero-shot에서도 강함을 보임