Demystifying Domain-adaptive Post-training for Financial LLMs
Written By. Zixuan Ke, Yifei Ming, Xuan-Phi Nguyen, Caiming Xiong, Shafiq Joty
1. 문제 정의
핵심 문제
강력한 범용 instruction-tuned LLM을 금융 도메인 전문가 모델로 만들기 위한 효과적인 domain-adaptive post-training 방법 탐색이 핵심 문제임.
기존 금융 LLM 연구들은 대체로 다음 방식 중 일부만 사용함.
- 금융 텍스트 기반 CPT
- 금융 테스크 기반 instruction tuning (IT)
- 선호 데이터 기반 preference alignment (PA)
- 위 단계를 단순 순차 적용
그러나 기존 방식에는 다음 한계 존재.
기존 연구의 한계
1) 금융 LLM이 갖춰야 할 능력 정의 부족
기존 연구는 주로 감성 분석, NER, 요약 등 일부 금융 테스크 성능만 평가함.
하지만 금융 전문가 LLM은 단순 테스크 성능뿐 아니라 다음 능력까지 필요함.
- 금융 개념 이해
- 금융 테스크 수행
- 금융 reasoning
- instruction-following 및 chat 능력 유지
즉, 금융 테스크 점수만으로 금융 LLM을 평가하기에는 부족함.
2) CPT, IT, PA의 역할과 trade-off 분석 부족
CPT, instruction tuning, preference alignment는 각각 효과가 다름.
| 단계 | 주요 효과 | 주요 문제 |
|---|---|---|
| CPT | 금융 개념 주입 | 일반 지식 및 instruction-following 망각 |
| IT / SFT | 지시 따르기 및 테스크 적응 | novel task generalization 한계 |
| PA / DPO | reasoning 개선 | 고품질 preference data 필요 |
논문은 각 단계의 역할을 분리해 분석하고, 이를 조합하는 최적 recipe를 찾는 것을 목표로 함.
3) 금융 특화와 일반 능력 유지의 균형 문제
금융 데이터만 학습하면 금융 성능은 오를 수 있지만, 기존 LLM이 가진 일반 지식과 instruction-following 능력이 손상될 수 있음.
2. FINDAP 프레임워크
논문은 금융 특화 post-training 프레임워크인 FINDAP 제안.
FINDAP은 네 구성요소로 이루어짐.
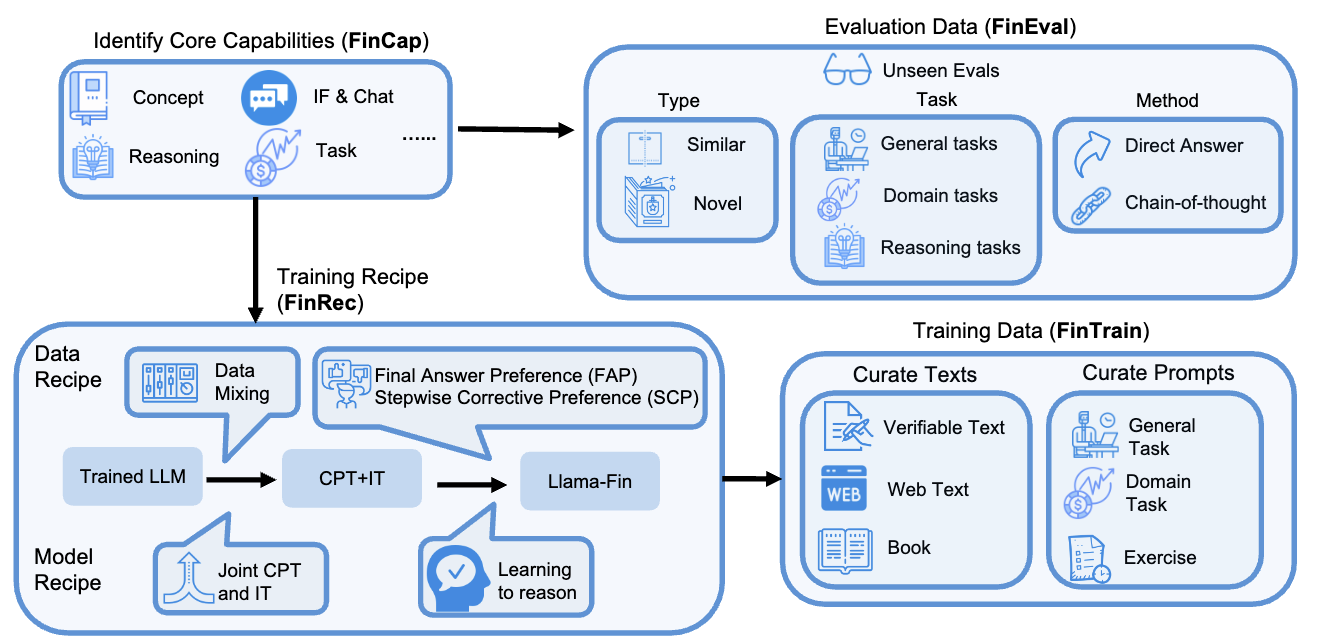
| 구성요소 | 의미 |
|---|---|
| FinCap | 금융 LLM이 가져야 할 핵심 능력 정의 |
| FinRec | CPT, IT, PA를 조합한 학습 recipe |
| FinTrain | FinRec 구현을 위한 학습 데이터 |
| FinEval | FinCap에 맞춘 평가 프레임워크 |
전체 흐름은 다음과 같음.
- Llama3-8B-Instruct → Joint CPT + IT → Preference Alignment → Llama-Fin
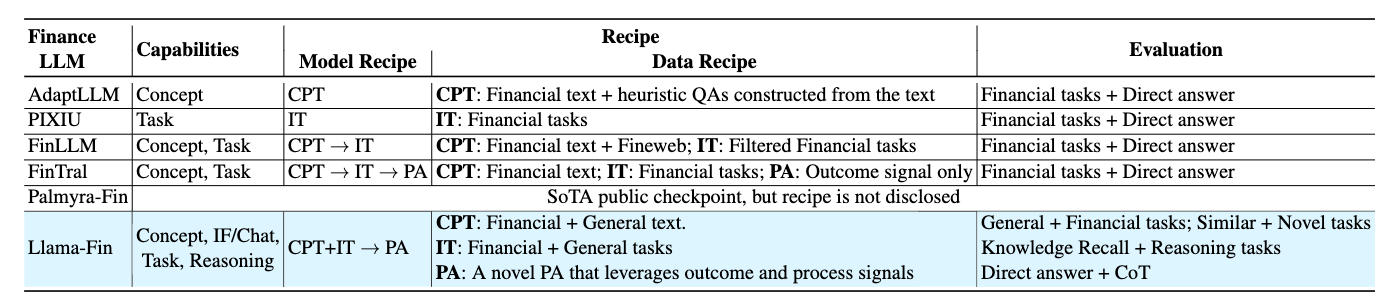
2.1 FinCap: 금융 LLM 핵심 능력 정의
FinCap은 금융 전문가 LLM이 가져야 할 능력을 네 가지로 정의함.
1) Domain-specific concepts
금융 개념 이해 능력임.
금융 용어는 일반 문맥과 다른 의미를 갖는 경우가 많음.
따라서 금융 도메인 텍스트를 통해 개념 자체를 모델에 주입하는 과정 필요.
이 역할은 주로 CPT가 담당함.
2) Domain-specific tasks
금융 특화 테스크 수행 능력임. (금융 특화 테스크 예시: 금융 감성 분석, 금융 NER, 금융 뉴스 요약, 주가 움직임 예측, 신용 점수 예측, 사기 탐지, 재무제표 QA)
개념을 아는 것과 테스크를 잘 푸는 것은 다름.
따라서 instruction 형태의 금융 테스크 학습 필요.
이 역할은 주로 IT / SFT가 담당함.
3) Reasoning
복잡한 금융 추론 능력임. ( 추론 예시: CFA 문제 풀이, 재무제표 기반 계산, 수익성·위험성 판단, 조건부 금융 의사결정, 수치 추론)
금융 문제는 단순 분류보다 단계별 계산과 근거 연결이 중요한 경우가 많음.
따라서 reasoning step을 개선하기 위한 별도 alignment 필요.
이 역할은 주로 PA / DPO가 담당함.
4) 일반 지식 Instruction-following & Chat
실제 서비스 사용성을 위한 지시 이해 및 대화 능력임.
CPT만 수행하면 instruction-following 능력이 크게 손상될 수 있음.
따라서 금융 특화 과정에서도 기존 instruction-following 능력을 보존해야 함.
2.2 FinRec: 학습 recipe
FinRec의 핵심은 CPT와 IT의 joint training, 이후 PA를 통한 reasoning 강화임.
기존 sequential 방식의 문제
기존 방식은 보통 다음 흐름임.
- Base LLM → CPT → IT → PA
문제는 CPT 단계에서 instruction-following 능력이 먼저 크게 손상된다는 점임.
이후 IT가 이를 회복해야 하지만, 완전히 회복되지 않을 수 있음.
논문 방식: Joint CPT + IT
논문은 CPT와 IT를 동시에 학습함.
- Base LLM → Joint CPT + IT → PA
핵심 아이디어는 다음과 같음.
CPT로 금융 개념을 학습하면서, IT로 instruction-following 능력을 동시에 유지함.
CPT와 IT는 모두 next-token prediction 기반임.
차이는 loss masking 방식임.
| 데이터 유형 | 학습 방식 |
|---|---|
| CPT | plain text 전체에 next-token prediction loss 적용 |
| IT | instruction 부분은 masking, response 부분에만 loss 적용 |
따라서 두 데이터를 섞어 하나의 학습 루프로 joint optimization 가능.
2.3 Joint CPT + IT의 장점
1) 금융 개념 학습
CPT를 통해 금융 문서, 웹 텍스트, 교재, CFA 자료 등에서 금융 개념 습득 가능.
2) instruction-following 망각 완화
IT 데이터를 함께 넣기 때문에 모델이 instruction-response 구조를 계속 학습하므로 CPT 단독 학습 대비 instruction-following 손상 감소.
3) novel task generalization 개선
IT만으로는 학습한 테스크와 유사한 문제에는 강하지만, 새로운 금융 테스크 일반화에는 한계 존재.
반면 CPT는 여러 테스크에 공유되는 금융 개념을 학습하므로 novel task generalization에 도움.
4) CPT와 IT 간 knowledge transfer
CPT에서 배운 금융 개념이 IT 테스크 학습에 활용됨.
즉, 개념 학습과 테스크 학습 간 상호 보완 발생.
2.4 CPT+IT 데이터 구성
최종 recipe는 CPT와 IT를 50:50 비율로 혼합함.
Group 1
| 구분 | 구성 |
|---|---|
| CPT | 금융 텍스트 50% + 일반 텍스트 50% |
| IT | 금융 테스크 20% + 일반 테스크 80% |
Group 2
| 구분 | 구성 |
|---|---|
| CPT | Group 1 + 금융 도서 데이터 |
| IT | Group 1 + 도서에서 추출한 exercise |
Group 2는 더 고품질의 금융 도서와 exercise를 포함함.
즉, curriculum learning처럼 상대적으로 고품질 데이터를 후반에 배치한 구조임.
2.5 FinTrain: 학습 데이터
FinTrain은 CPT, IT, PA 각각에 맞게 구성된 데이터셋임.
| 구분 | 목적 | 데이터 구성 | 주요 출처/예시 | 규모 | 핵심 역할 |
|---|---|---|---|---|---|
| CPT 데이터 | 금융 개념 주입 및 일반 지식 보존 | 금융 텍스트 + 일반 텍스트 | 금융 웹사이트 70개, 금융 기관/규제기관 자료, 교육 플랫폼, 산업 뉴스, 금융 도서, CFA 준비 자료, NaturalInstruction, PromptSource 등 | 약 6B tokens | 금융 용어·개념·문체 학습. 일반 텍스트는 catastrophic forgetting 완화를 위한 replay 역할 |
| IT 데이터 | instruction-following, 금융 태스크 수행, reasoning 학습 | 금융 태스크 + 일반 instruction/chat + reasoning 데이터 | FinRED, 금융 NER, 금융 headline/sentiment classification, TradeTheEvent, FinanceInstruct, ConvFinQA, FinQA, FiQA, Self-Instruct, SlimOrca, UltraChat, ShareGPT, OrcaMath, MetaMathQA, MathInstruct, CFA exercise 등 | 약 3.16M prompts | 사용자의 지시를 따르는 능력 유지.금융 태스크 적응. 수학·코드·CFA 기반 reasoning 능력 보강 |
2.6 Preference Alignment: reasoning 강화
CPT+IT 이후에도 복잡한 금융 reasoning은 부족할 수 있음.
특히 국제 공인 재무분석사 문제처럼 각 reasoning step이 중요한 문제에서 오류 발생 가능성 존재.
이를 해결하기 위해 논문은 DPO 기반 Preference Alignment 수행.
단, 일반적인 preference data가 아니라 두 종류의 preference signal 사용.
- FAP: Final Answer Preference
- SCP: Stepwise Corrective Preference
2.7 FAP: Final Answer Preference
FAP는 최종 답변 수준의 preference임.
절차
- 질문 입력
- CPT+IT checkpoint가 solution 생성
- GenRM이 solution 전체 평가
- 최종 답이 맞으면 chosen
- 최종 답이 틀리면 rejected
특징
| 항목 | 내용 |
|---|---|
| supervision 수준 | 전체 답변 수준 |
| 장점 | 생성 비용 낮음, 효율적 |
| 단점 | 어느 reasoning step이 틀렸는지 알기 어려움 |
FAP는 outcome-level reward에 해당함.
2.8 SCP: Stepwise Corrective Preference
SCP는 reasoning step 수준의 preference임.
논문에서 가장 중요한 방법론적 기여 중 하나임.
핵심 아이디어
최종 답만 평가하지 않고, reasoning 과정에서 처음 틀린 step을 찾아 교정함.
절차
- 질문과 모델 reasoning path 입력
- GenRM이 첫 번째 오류 step 식별
- GenRM이 해당 step을 올바른 step으로 수정
- 기존 오류 step을 rejected로 사용
- 수정된 step을 chosen으로 사용
preference sample 구성
1
2
3
4
5
6
7
8
9
10
Input:
Question
+ 첫 오류 직전까지의 reasoning steps
+ "What is the next step?"
Chosen:
GenRM이 생성한 올바른 next step
Rejected:
모델이 원래 생성한 잘못된 step
장점
SCP는 모델에게 다음을 직접 학습시킴.
특정 reasoning prefix 다음에 어떤 step이 와야 하는가.
따라서 복잡한 금융 문제에서 중간 추론 오류를 줄이는 데 효과적임.
2.9 FAP와 SCP 비교
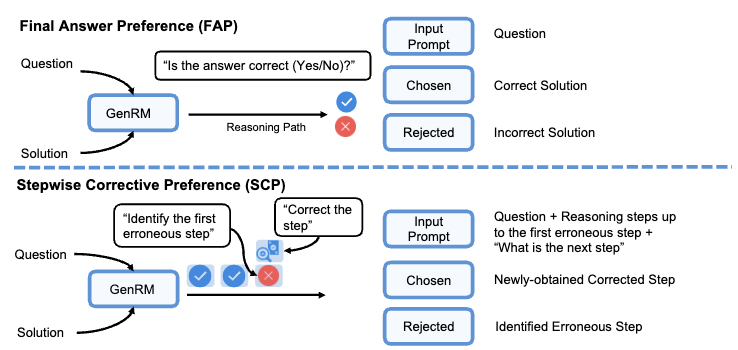
| 구분 | FAP | SCP |
|---|---|---|
| 평가 단위 | 최종 답변 | reasoning step |
| reward 유형 | outcome reward | process reward |
| 장점 | 효율적 | 오류 위치 교정 가능 |
| 단점 | 오류 원인 파악 어려움 | 데이터 생성 복잡 |
| 역할 | 전체 답변 품질 개선 | 단계별 추론 품질 개선 |
논문은 FAP와 SCP를 함께 사용함.
FAP는 넓은 preference signal 제공, SCP는 세밀한 reasoning supervision 제공.
3. 실험
3.1 평가 프레임워크: FinEval
FinEval은 총 35개 테스크로 구성됨.
평가 축은 다음과 같음.
| 축 | 구분 |
|---|---|
| 테스크 유사도 | Similar, Novel |
| 도메인 | General, Finance, Reasoning |
| 평가 방식 | Direct answer, Chain-of-thought |
Similar vs Novel 구분
| 구분 | 의미 |
|---|---|
| Similar unseen tasks | 학습 테스크와 유형은 유사하지만 sample은 unseen |
| Novel tasks | 학습 중 보지 않은 새로운 테스크 유형 |
이 구분은 매우 중요함.
단순히 비슷한 테스크를 잘 푸는지, 완전히 새로운 금융 테스크에도 일반화되는지 분리 평가하기 위함임.
3.4 Similar unseen task 결과
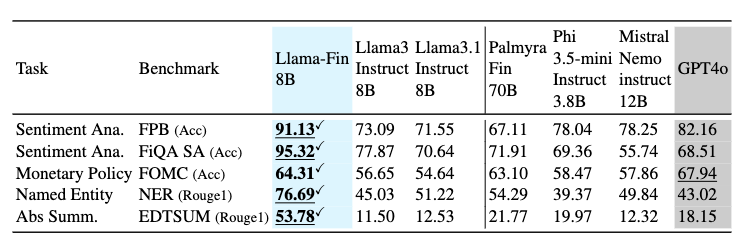
평가 테스크
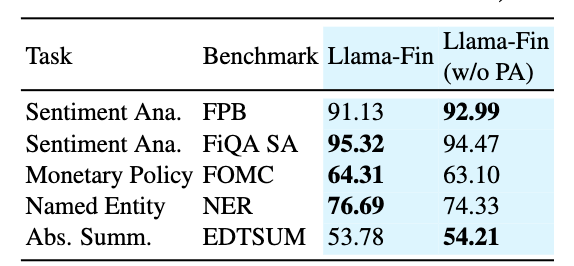
- FPB sentiment analysis, FiQA sentiment analysis, FOMC monetary policy classification, 금융 NER, EDTSUM abstractive summarization
해석
- Llama-Fin은 8B급 baseline 대비 큰 폭의 성능 향상 달성.
- 다만 이 테스크들은 완전히 새로운 테스크가 아니라 학습 테스크와 유사한 유형이므로, 결과 해석 시 주의 필요.
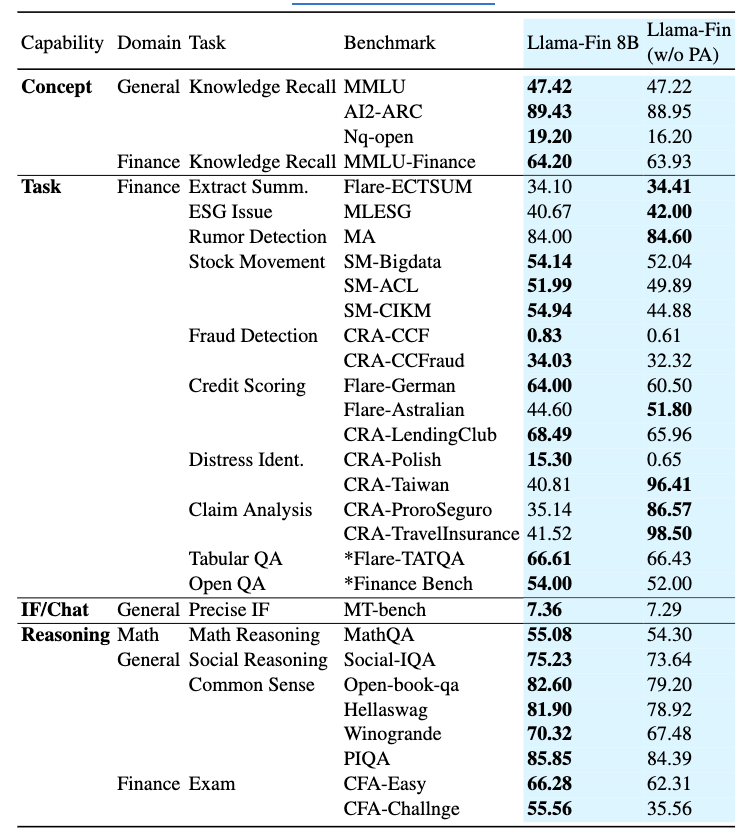
3.5 Novel task 결과
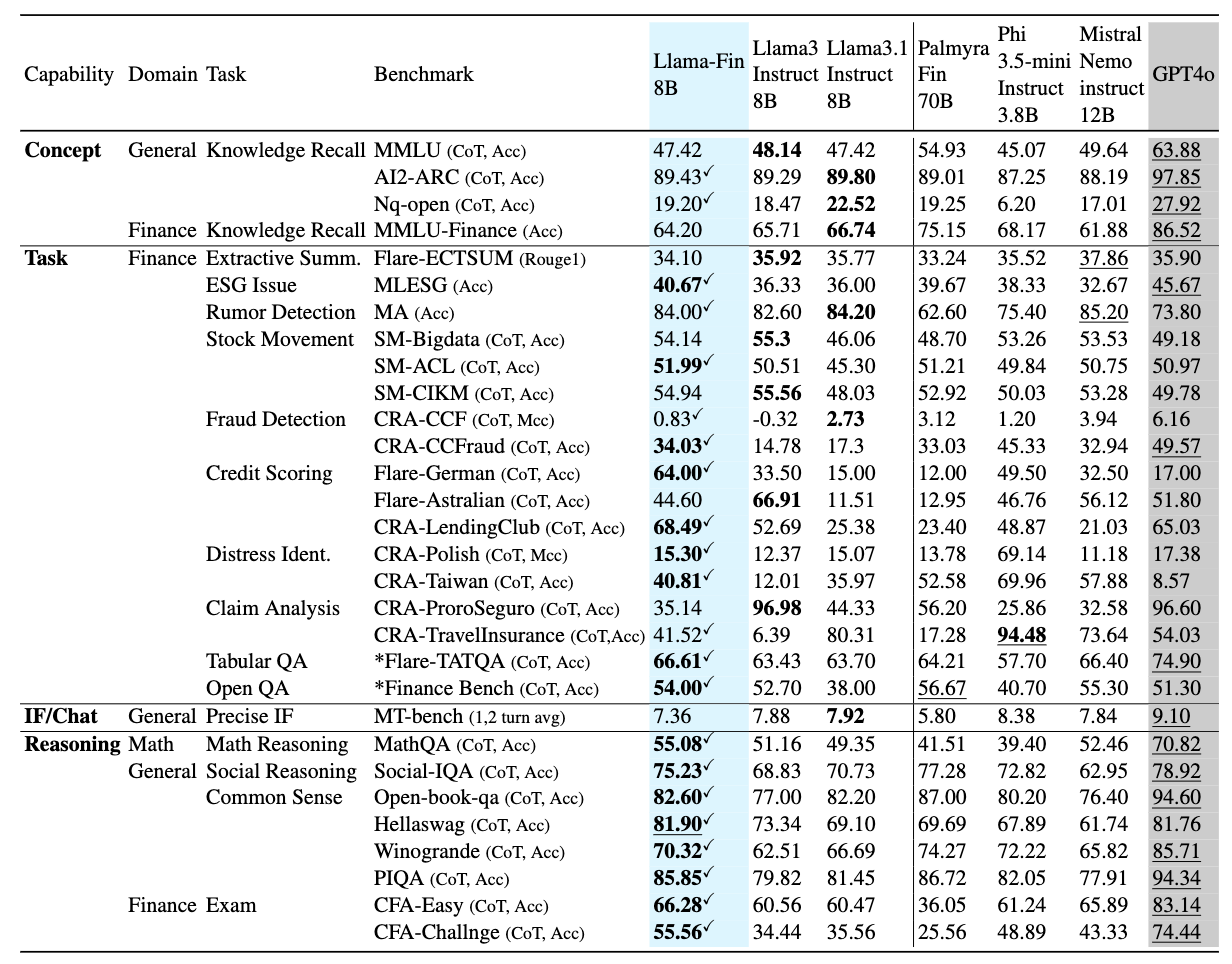
Novel task에서는 FinCap의 네 능력별 평가 수행.
1) Concept
일반 지식에서는 Llama-Fin이 base model과 비슷하거나 일부 더 나은 성능을 보임.
이는 joint CPT+IT와 일반 데이터 mixing이 general forgetting을 어느 정도 완화했음을 의미함.
다만 MMLU-Finance에서는 base보다 약간 낮음.
논문은 CPT가 학습한 금융 개념과 MMLU-Finance가 요구하는 개념이 다를 수 있다고 해석함.
2) Task
Novel 금융 테스크 17개 중 13개에서 Llama-Fin이 base model보다 우수함.
이는 단순히 학습 테스크 memorization이 아니라 새로운 금융 테스크에도 일정 수준 일반화됨을 의미함.
3) IF/Chat
Llama-Fin이 base보다 다소 낮지만, CPT를 수행했음에도 instruction-following 능력을 상당 부분 유지함.
CPT 단독 수행 시 MT-Bench가 약 1점 수준까지 떨어졌던 점을 고려하면 joint CPT+IT의 효과가 큼.
4) Reasoning
reasoning 테스크에서는 Llama-Fin이 base model보다 전반적으로 높은 성능을 보임.
특히 CFA-Challenge에서 PA 효과가 큼.
이는 FAP + SCP 기반 PA가 금융 reasoning 개선에 효과적임을 보여줌.
4. Ablation 분석
4.1 CPT 데이터 구성
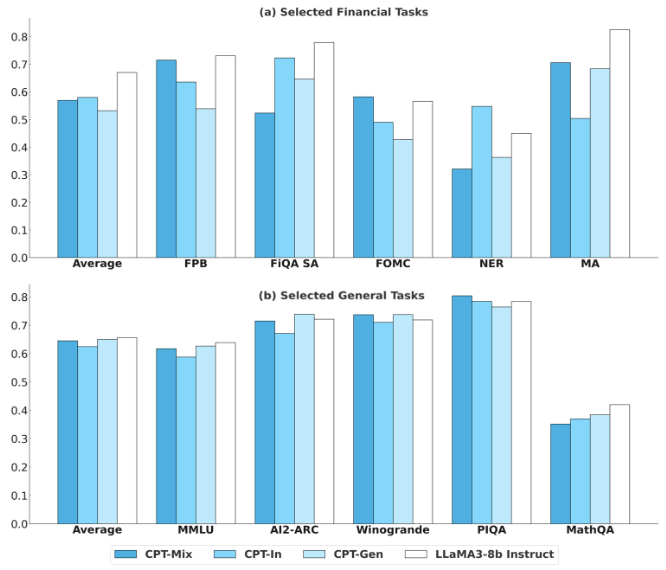
CPT 데이터는 세 가지로 비교함.
| 데이터 | 구성 |
|---|---|
| CPT-In | 금융 텍스트만 사용 |
| CPT-Gen | 일반 텍스트만 사용 |
| CPT-Mix | 금융 + 일반 텍스트 혼합 |
금융 CPT에는 금융 데이터만 넣는 것보다 일반 데이터 replay를 함께 넣는 것이 중요함.
4.2 IT 데이터 구성
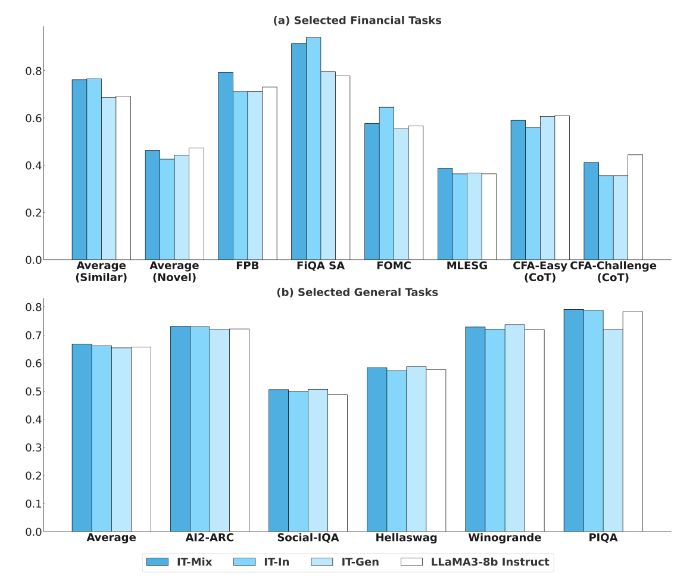
IT 데이터도 세 가지로 비교함.
| 데이터 | 구성 |
|---|---|
| IT-In | 금융 instruction만 사용 |
| IT-Gen | 일반 instruction만 사용 |
| IT-Mix | 금융 + 일반 instruction 혼합 |
IT는 CPT보다 forgetting이 훨씬 작음.
다만 IT만으로는 novel task generalization 개선이 제한적임.
4.3 Sequential vs Joint CPT+IT
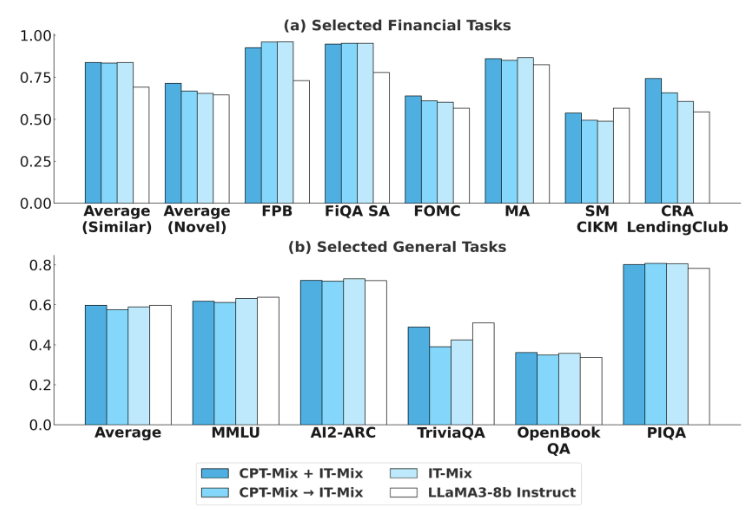
Joint training이 sequential training보다 우수함.
이유는 다음과 같음.
- CPT 단계에서 발생하는 instruction-following 망각을 줄임
- CPT에서 학습한 금융 개념을 IT가 바로 활용 가능
따라서 논문의 최종 recipe는 joint CPT+IT임.
4.4 Down-sampling vs No-sampling
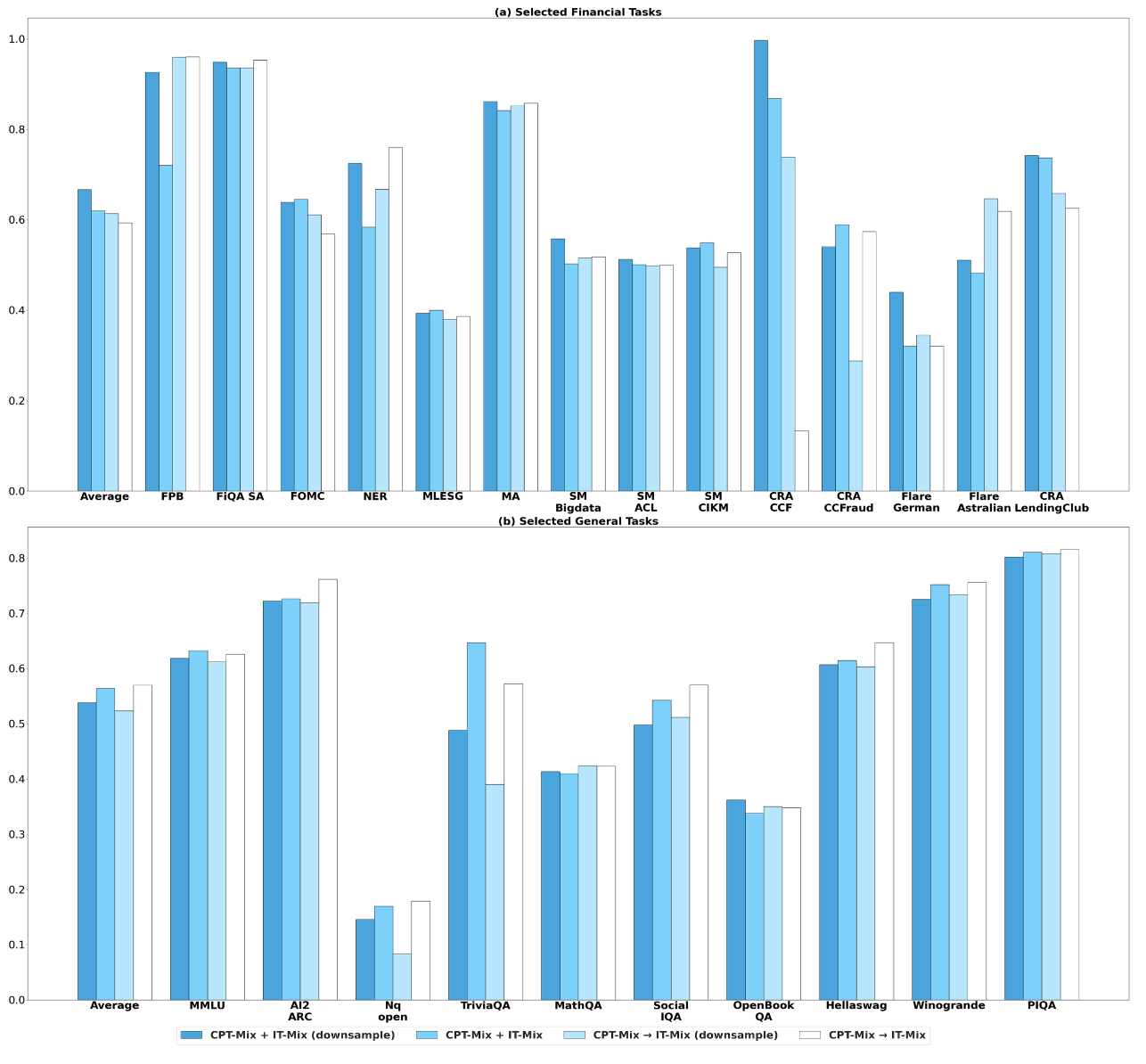
CPT 데이터는 IT 데이터보다 훨씬 큼. 따라서 CPT를 IT 규모에 맞춰 down-sampling할지 여부 비교.
| 전략 | 장점 | 단점 |
|---|---|---|
| down-sampling | 금융 테스크 및 instruction-following에 유리 | 일반 개념 유지에는 불리할 수 있음 |
| no-sampling | 일반 개념 유지에 유리 | 금융 테스크와 instruction-following 약화 가능 |
최종 recipe에서는 CPT와 IT를 50:50으로 맞추는 down-sampling 전략 사용.
4.5 LoRA vs Full fine-tuning
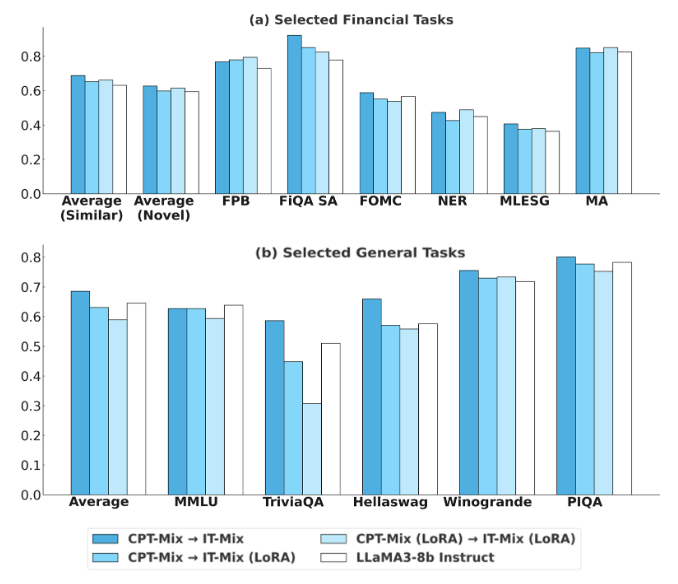
CPT+IT의 경우
- Full fine-tuning이 LoRA보다 우수함.
- CPT에서 학습한 지식을 IT로 전이하려면 전체 파라미터 업데이트가 중요함.
따라서 금융 CPT 기반 전문 LLM을 만들 때 LoRA만으로는 novel task generalization에 한계가 있을 수 있음.
4.6 PA 효과
PA는 모든 테스크를 무조건 개선하는 단계는 아님.
특히 reasoning 테스크에서 효과가 큼.
Similar tasks
5개 중 3개 테스크에서 PA가 성능 개선. 나머지 2개에서도 큰 forgetting 없음.
Novel tasks
금융 task에서는 mixed result 발생.
일부 쉬운 classification/task에서는 PA가 오히려 성능을 낮추기도 함.
하지만 reasoning에서는 명확한 개선 확인.
즉, PA는 일반 금융 테스크 성능 향상용이라기보다 복잡한 금융 reasoning 개선용으로 해석하는 것이 적절함.
5. 결론
1) 금융 CPT 단독 학습은 위험함
CPT는 금융 개념 주입에는 효과적임.
하지만 instruction-tuned LLM에 CPT만 수행하면 instruction-following과 일반 능력 망각이 큼.
따라서 금융 CPT는 단독으로 수행하기보다 일반 데이터 replay와 IT를 함께 고려해야 함.
2) CPT와 IT는 joint training이 효과적임
Sequential 방식보다 joint 방식이 더 안정적임.
핵심 recipe:
1
2
3
50% CPT + 50% IT
금융 데이터 + 일반 데이터 혼합
고품질 금융 도서 및 exercise를 후반 curriculum에 배치
3) 금융 reasoning에는 preference alignment 필요
CPT+IT만으로는 복잡한 금융 reasoning이 충분하지 않음.
FAP와 SCP 기반 PA를 추가하면 CFA와 같은 고난도 금융 reasoning 성능이 크게 개선됨.
특히 SCP는 최종 정답이 아니라 reasoning step 자체를 교정하기 때문에 금융 수치 추론과 시험형 문제에 적합함.
4) 데이터 구성의 핵심은 “금융 데이터만 많이 넣기”가 아님
중요한 것은 데이터 균형임.
- 금융 텍스트와 일반 텍스트의 균형
- 금융 instruction과 일반 instruction의 균형
- 개념 학습과 테스크 학습의 균형
- final answer preference와 stepwise preference의 균형
- 금융 특화 성능과 일반 능력 보존의 균형
실무 적용 관점 요약
금융 특화 LLM을 CPT로 만들려는 경우, 이 논문에서 가져갈 핵심 recipe는 다음임.
1
2
3
4
5
6
7
8
9
10
1. instruction-tuned LLM에서 시작
2. 금융 CPT 단독 수행 지양
3. CPT와 IT를 joint training
4. CPT에는 금융 텍스트 + 일반 고품질 텍스트 혼합
5. IT에는 금융 task + 일반 instruction/chat + reasoning 데이터 혼합
6. CPT:IT 비율은 50:50 근처에서 시작
7. 고품질 금융 도서와 exercise를 curriculum 후반에 배치
8. 복잡한 금융 reasoning이 중요하면 DPO 기반 PA 추가
9. PA 데이터는 FAP + SCP로 구성
10. 평가는 similar task와 novel task를 반드시 분리