Multi-Agent-as-Judge: Aligning LLM-Agent-Based Automated Evaluation with Multi-Dimensional Human Evaluation
Multi-Agent-as-Judge: Aligning LLM-Agent-Based Automated Evaluation with Multi-Dimensional Human Evaluation
Written By. Jiaju Chen, Yuxuan Lu, Xiaojie Wang, Huimin Zeng, Jing Huang, Jiri Gesi, Ying Xu, Bingsheng Yao, Dakuo Wang
1. 문제정의
- 현실 과제 평가의 본질적 어려움
- 실제 NLP 응용은 교육·의료처럼 다양한 이해관계자 관점이 동시에 필요한 경우가 많음
- 따라서 평가 기준도 단일 축이 아니라 문법성, 적절성, 전문성, 교육성, 임상적 유용성 등 복수 축 필요
- 단일 평가자나 단순 유사도 지표만으로는 이러한 현실적 평가 구조 반영의 어려움
- 기존 자동평가 지표의 한계
- ROUGE, BLEU, BERTScore 등은 주로 표면적 중첩 또는 의미 유사도 측정에 강점
- 그러나 의료 요약의 근거 강도, 교육용 QA의 아동 발달 적합성처럼 도메인 특화 평가축 포착의 한계
- 즉, 정답과 비슷한가는 보더라도 실제로 전문가가 좋다고 볼 만한가는 충분히 반영하지 못함
- 기존 LLM-as-a-judge의 한계
- 단일 LLM 평가 방식의 경우 모델 고유 편향에 묶여 다중 이해관계자 관점 모사에 한계
- 최근의 multi-agent 평가도 존재하지만, 대체로 페르소나가 수작업·임의 설계 방식
- 같은 “teacher” 역할이라도 어떤 연구에서는 문법, 다른 연구에서는 참여도에 초점을 두는 식으로 재현성 부족
- 특정 태스크에 맞춰 하드코딩된 평가축이 많아 새 도메인으로의 일반화 부족
- 이 논문의 핵심 문제의식
- “사람처럼 다면적으로 평가하는 자동 평가자”의 필요
- “임의로 만든 에이전트”가 아니라 문헌 근거 기반으로 자동 생성된 이해관계자 페르소나의 필요
- “단일 답변”이 아니라 토론과 조정을 거친 다중 관점 평가의 필요
2. MAJ-EVAL
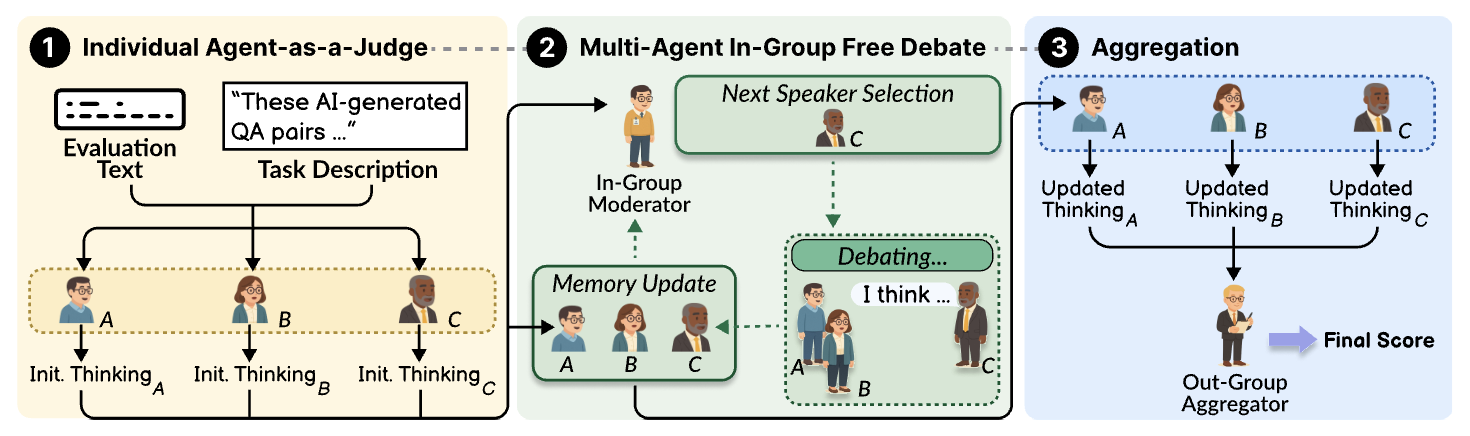
- 핵심 제안
- MAJ-EVAL은 문헌 기반 이해관계자 추출 + 페르소나 생성 + 집단 내 토론 기반 평가를 결합한 Multi-Agent-as-Judge 프레임워크 제안
- 전체 2단계 구조
- 1단계: 이해관계자 페르소나 생성
- 2단계: 멀티에이전트 토론 평가
2-1. 1단계: 이해관계자 페르소나 생성
- 입력
- 특정 도메인 태스크와 관련된 문서 집합 입력
- 예: 연구 논문, 질적 연구 문헌, 과업 설명 문서 등
- 세부 단계 1: 평가축 추출(Evaluative Dimension Extraction)
- LLM이 문서를 읽고 이해관계자와 그들의 관점, 근거를 추출
- 논문상 표현으로는 각 문서에서
- 이해관계자 이름
- 이해관계자 설명
- 평가축과 그 근거
- 를 구조화된 튜플 형태로 정리하는 방식
- 예시
- 부모: 질문이 단순 사실 회상이 아니라 창의성·호기심을 자극해야 함
- 임상의: 환자 특성, PICO 요소, 근거 적용 가능성이 중요함
- 중요한 점
- 평가 결과만 뽑는 것이 아니라 반드시 문헌 근거와 연결
- 따라서 역할 정의가 임의 설정이 아니라 증거 기반 구성이 됨
- 세부 단계 1의 후처리: 이해관계자 통합·군집화
- 서로 유사한 역할들을 LLM 기반 의미 군집화로 묶음
- 예
- education technology developers + AI developers → 더 큰 stakeholder group으로 통합 가능
- 동시에 지나치게 중복되는 평가축은 병합
- 단, 토론의 다양성을 위해 서로 다른 관점은 가능한 한 유지
- 즉, 중복 제거와 관점 다양성 보존의 균형 추구
- 세부 단계 2: 차원 기반 페르소나 구성(Dimension-Based Persona Construction)
- 통합된 각 축마다 하나의 구체적 페르소나 생성
- 페르소나 구성 요소 5가지
- 인구통계 정보
- 평가 관점
- 도메인 전문성
- 심리적 특성
- 사회적 관계
- 예
- 단순히 “교사 역할”만 부여하는 방식이 아니라,
- “27세 조기교육 교사, 단순한 what-question을 선호, 아동 호기심 유발에 열정적, 동료 교사와 협업” 같은 수준의 구체성 부여
- 효과
- 에이전트가 단순 역할명에 반응하는 것이 아니라 실제 사람 같은 우선순위와 평가 습관을 갖도록 유도하는 설계
- 이 단계의 핵심 의의
- 기존 multi-agent 평가의 가장 큰 약점이던 임의적 페르소나 설계 문제 해결
- 새로운 도메인에서도 관련 문헌만 있으면 평가자 자동 재구성 가능성
- 즉, 태스크별 하드코딩이 아니라 문헌-구동형 평가자 생성 방식이라는 점이 핵심 차별점
2-2. 2단계: 멀티에이전트 토론 평가
- 기본 아이디어
- 생성된 페르소나를 실제 LLM 에이전트로 인스턴스화한 뒤,
- 같은 이해관계자 그룹 내부에서 자유 토론 진행
- 이후 그룹 간 결과를 종합하여 최종 점수와 피드백 생성
- Phase 1: 개별 초기 평가(Individual Agent-as-a-Judge)
- 각 에이전트가 먼저 독립적으로 평가
- 같은 콘텐츠를 보더라도 서로 다른 관점 때문에 초기 점수가 달라지도록 설계
- 목적
- 처음부터 평균을 내는 것이 아니라 관점 다양성 확보
- 실제 인간 평가자들의 초기 의견 차이를 모사하는 단계
- Phase 2: 집단 내 자유 토론(Multi-Agent In-Group Free Debate)
- 이 단계가 본 논문의 실질적 핵심
- 그룹마다 moderator/coordinator agent가 존재
- coordinator가 토론 기록을 보고 다음 발화자를 선택
- 선택 기준
- 아직 해결되지 않은 의견 충돌 존재 여부
- 아직 충분히 언급되지 않은 관점 존재 여부
- 각 에이전트의 행동
- 다른 평가에 동의
- 반박
- 보완 설명 추가
- 기존 판단 수정
- 발언할 내용이 더 없으면
"NO MORE COMMENTS"와 함께 최종 평가 제출 - 알고리즘 관점 정리
- 초기 평가 집합 생성
- 토론 이력(history/memory) 누적
- coordinator가 다음 화자 선택
- 발화 반영 후 메모리 업데이트
- 종료 조건 충족 시 각 에이전트 최종 피드백 확보
- 이 구조의 장점
- 단순 다수결이 아니라 상호 반박·성찰·수정 과정 반영
- 블라인드 스폿 발견 가능성
- 인간 협업 평가와 더 유사한 절차 확보
- Phase 3: 최종 집계(Aggregation)
- aggregator agent가 모든 그룹의 최종 평가 수집
- 수행 내용 2가지
- 질적 피드백 종합: 어디서 의견 일치/불일치가 있었는지 요약
- 양적 점수 집계: 그룹별 사후 점수 평균을 통해 최종 점수 도출
- 결과적으로 산출물은 단순 점수 하나가 아니라
- 합의점
- 쟁점
- 최종 해석
- 평균 점수
- 를 포함하는 다면적 평가 결과물
2-3. 프롬프트 설계까지 포함한 구현 특징
- 평가 축 추출 프롬프트
- 문단 단위로 읽기
- related work와 references 무시
- 사람/이해관계자 식별
- 각 이해관계자의 관점과 근거를 JSON으로 출력
- 즉, 문헌 요약이 아니라 평가자 설계용 정보 추출 목적의 프롬프트 설계
- 페르소나 생성 프롬프트
- 하나의 stakeholder 안에서도 관점별로 별도 persona 생성
- 인구통계, 전문성, 심리, 관계까지 명시
- 결과적으로 동일 stakeholder group 내부에서도 미세하게 다른 시각 보유 가능성 확보
- 에이전트 인스턴스화 프롬프트
- “너는 누구이며, 어떤 전문성과 심리·사회적 관계를 가진 평가자인가”를 먼저 고정
- 이후 자신의 관점에 기반해 평가하도록 유도
- “다른 에이전트 의견을 듣되 무조건 동조하지 말고 자신의 관점에 근거할 것”이라는 제약 포함
- 최종적으로 해결한 것
- 페르소나 설계의 임의성 감소
- 태스크 전환 시 재설계 비용 감소
- 다면적 인간 평가와의 정렬 강화
- 정량 점수와 정성 피드백의 동시 제공 가능성
3. 실험
3-1. 실험 과제와 데이터셋
- 과제 1: 아동 스토리북 QAG 평가
- 데이터셋: StorySparkQA
- 전체 5,868 QA 쌍 중, 실험에서는 GPT-4가 생성한 70개 QA 쌍 사용
- 인간 전문가 평가축 4개
- Grammar Correctness
- Answer Relevancy
- Contextual Consistency
- Children’s Educational Appropriateness
- 과제 2: 의료 문헌 다문서 요약 평가
- 데이터셋: MSLR-COCHRANE
- 6개 모델이 만든 600개 요약 중 모델별 17개씩 샘플링하여 총 102개 사용
- 인간 전문가 평가축 4개
- Fluency
- PIO Consistency
- Effect Direction
- Evidence Strength
3-2. 비교 대상
- 전통적 자동평가
- ROUGE-L F1
- BERTScore
- 단일 LLM-as-a-judge
- G-Eval
- 기반 모델로 GPT-4, Claude-3.7-Sonnet, Qwen-3-235B 활용
- 기존 Multi-Agent-as-a-Judge
- ChatEval
- 역시 여러 기반 모델 변형 실험 수행
3-3. 평가 지표와 구현
- 주요 평가 지표
- 절대값 Spearman’s ρ
- Kendall’s τ
- Pearson correlation
- 핵심 관점은 인간 점수와 얼마나 잘 정렬되는가의 측정
- 구현 세부
- MAJ-EVAL 기반 모델: Claude-3.7-Sonnet, Qwen-3-235B
- 페르소나 생성용 입력 문헌은 Google Scholar 기반 snowballing으로 수집
- 최근 3년 논문도 추가 검색하여 관점 최신성 확보
- QAG용 3개 문헌, 의료 요약용 2개 문헌 선택
3-4. 주요 결과
전체 성능 결과
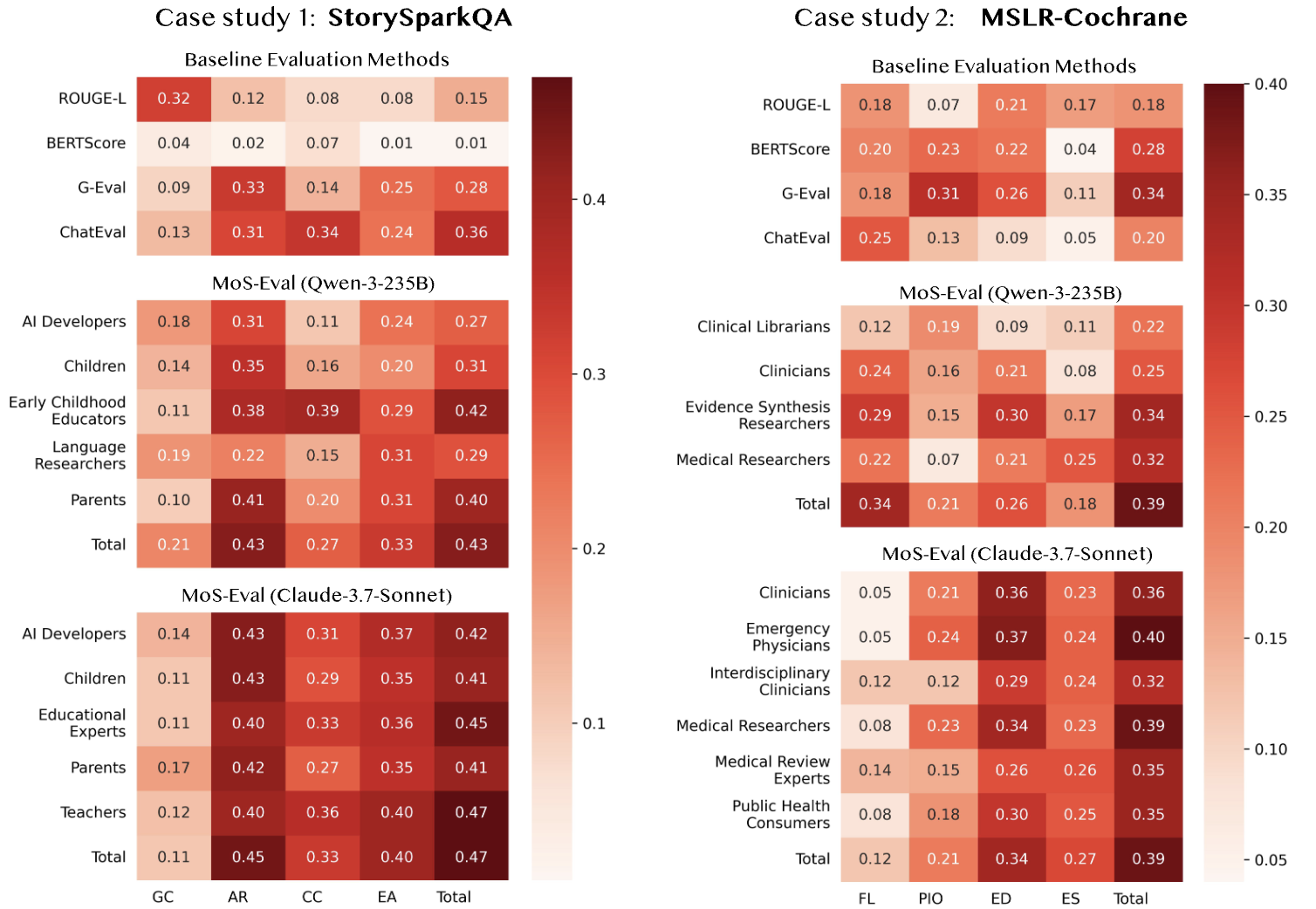
- 두 태스크 모두에서 MAJ-EVAL이 전반적으로 가장 높은 인간 정렬 성능 보고
- 특히 아동 교육 QA처럼 단순 유사도보다 교육적 적절성·맥락성이 중요한 과제에서 큰 차이 확인
- MAJ-EVAL의 정성적 장점: 결과가 단순 점수 출력이 아니라 도메인 전문가다운 설명 가능 평가라는 점이 강점
3-5. Ablation Study
상세 페르소나 vs 단순 역할 정의
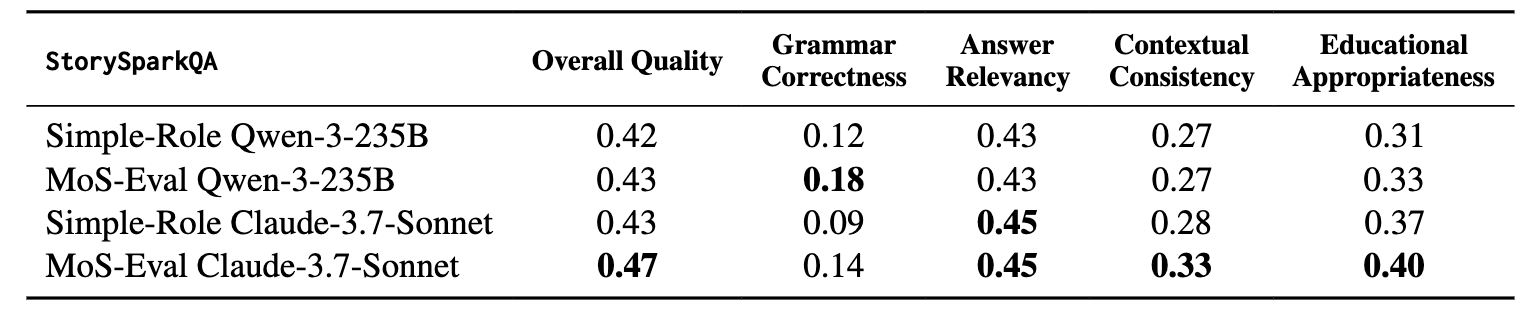
- “당신은 유치원 교사입니다” 같은 단순 역할보다, 논문이 제안한 상세 페르소나 구성이 인간 점수와 더 높은 상관을 보임
토론 메커니즘 효과
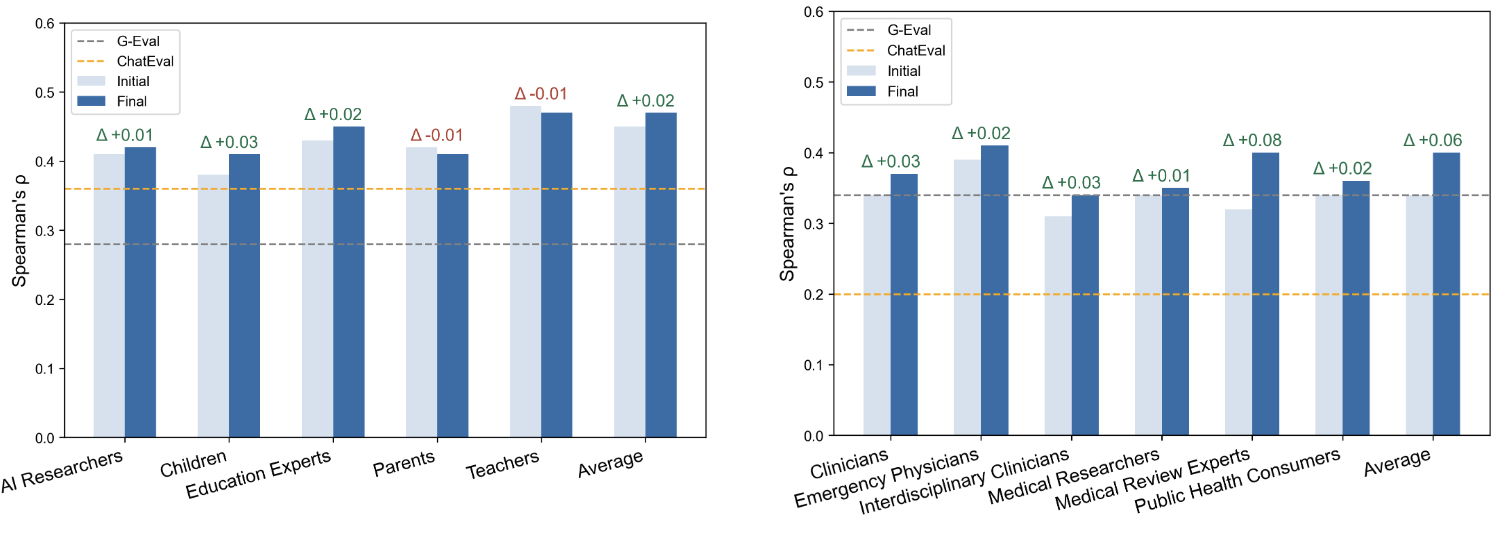
- 태스크 수준 평균 상관도는 모두 상승
- 일부 그룹에서는 상관 하락도 있었는데, 이는 인간 기준에는 없지만 이론적으로 타당한 추가축을 고려했기 때문이라는 해석 제시
3-6. 비용·실용성
- 토큰 비용
- 페르소나 생성: 문서당 평균 약 34,103 tokens
- 토론: stakeholder group당 데이터포인트당 약 18,281 tokens
- 예시 설정 기준 총 약 141,329 tokens/task
- Claude 3.7 Sonnet 가격 기준 약 $0.42/task
- 지연 시간
- Qwen: 약 26.13초/task
- Claude: 약 34.20초/task
- 그룹별 토론 병렬화 가능성 존재
- 저자 주장상 인간 전문가 평가 대비 비용·시간 측면에서 충분한 실용성 확보
4. 결론
- 핵심 결론 1
- MAJ-EVAL은 단순 자동평가나 단일 LLM 평가보다 인간의 다차원 평가와 더 잘 정렬되는 프레임워크라는 점
- 핵심 결론 2
- 성능 향상의 핵심 원인은 단순히 에이전트 수 증가가 아니라,
- 문헌 기반 평가축 추출
- 세밀한 페르소나 생성
- 집단 내 토론
- 의 결합이라는 점 시사
- 성능 향상의 핵심 원인은 단순히 에이전트 수 증가가 아니라,
- 핵심 결론 3
- 교육, 의료처럼 다양한 사회적 역할·전문성·사용자 요구가 얽힌 태스크에 특히 적합
- 반면 문법성 같은 표면적 축만 볼 때는 전통 지표가 여전히 강점 보유 가능성 존재
- 의의
- 평가자를 수작업으로 정의하는 기존 방식에서 벗어나, 도메인 문헌으로부터 자동으로 인간 평가자 집단을 구성하는 평가 패러다임 제시
- 정답과 비슷한가보다 현실의 다양한 사람이 어떻게 평가할 것인가에 더 가까운 자동평가 방향 제안
- 저자들이 제시한 향후 과제
- 인간 라벨러의 판단 근거 **추가 수집 필요
- 수집된 근거를 활용한 role-play agent 고도화 필요
- 더 다양한 도메인·더 작은 모델에서의 일반화 검증 필요
This post is licensed under CC BY 4.0 by the author.